De Rishi Bommasani1 de colaboradores. 12 de julho de 2022.
Índice
Resumo
A IA está passando por uma mudança de paradigma com o surgimento de modelos (p. ex., BERT, DALL-E, GPT-3) treinados em dados amplos (geralmente utilizando autossupervisão em escala) que podem ser adaptados a uma vasta gama de tarefas posteriores. Chamamos esses modelos de modelos fundamentais para sublinhar o seu carácter crucialmente central, embora incompleto. Este relatório fornece um relato completo das oportunidades e riscos dos modelos fundamentais, que vão desde suas capacidades (p. ex., linguagem, visão, manipulação robótica, raciocínio, interação humana) e princípios técnicos (p. ex., arquiteturas de modelos, procedimentos de treinamento, dados, sistemas, segurança, avaliação, teoria) às suas aplicações (p. ex., direito, saúde, educação) e impacto social (p. ex., desigualdade, uso indevido, impacto econômico e ambiental, considerações legais e éticas). Embora os modelos fundamentais sejam baseados no aprendizado profundo paradigmático e no aprendizado por transferência, a sua escala resulta em novas capacidades emergentes e a sua eficácia em tantas tarefas incentiva a homogeneização. A homogeneização proporciona uma vantagem poderosa, mas exige cautela, uma vez que os defeitos do modelo fundamental são herdados por todos os modelos adaptados posteriores. Apesar da iminente implementação generalizada de modelos fundamentais, atualmente carecemos de uma compreensão clara de como funcionam, quando falham e do que são capazes devido às suas propriedades emergentes. Para responder a essas questões, acreditamos que grande parte da investigação crítica sobre modelos fundamentais exigirá uma colaboração interdisciplinar profunda, proporcional à sua natureza fundamentalmente sociotécnica.
1 INTRODUÇÃO
Este relatório investiga um paradigma emergente para a construção de sistemas de inteligência artificial (IA) com base numa classe geral de modelos que chamamos de modelos fundamentais.2 Um modelo fundamental é qualquer modelo treinado em dados amplos (geralmente usando autossupervisão em escala) que pode ser adaptado (p. ex., com ajuste fino) para uma ampla gama de tarefas posteriores; exemplos atuais incluem BERT [Devlin et al. 2019], GPT-3 [Brown et al. 2020] e CLIP [Radford et al. 2021]. Do ponto de vista tecnológico, os modelos fundamentais não são novos; baseiam-se em redes neurais profundas e no aprendizado autossupervisionado, que existem há décadas. No entanto, a escala e o escopo dos modelos fundamentais dos últimos anos ampliaram a nossa imaginação sobre o que é possível; por exemplo, o GPT-3 tem 175 bilhões de parâmetros e pode ser adaptado por meio de instruções em linguagem natural para realizar um trabalho aceitável em uma ampla gama de tarefas, apesar de não ser treinado explicitamente para realizar muitas dessas tarefas [Brown et al. 2020]. Ao mesmo tempo, os modelos fundamentais existentes têm o potencial de acentuar os danos, e as suas características são, em geral, pouco compreendidas. Dada a sua iminente implementação generalizada, eles tornaram-se um tema de intenso escrutínio [Bender et al. 2021].
1.1 Emergência e homogeinização
A importância dos modelos fundamentais pode ser resumida em duas palavras: emergência e homogeneização. Emergência significa que o comportamento de um sistema é induzido implicitamente, em vez de ser construído explicitamente; é fonte tanto de entusiasmo científico quanto de ansiedade com relação a consequências imprevistas. Homogeneização indica a consolidação de metodologias para a construção de sistemas de aprendizado de máquina numa ampla gama de aplicações; proporciona um forte aproveitamento para muitas tarefas, mas também cria pontos únicos de falha. Para melhor apreciar a emergência e a homogeneização, reflitamos sobre a sua ascensão na pesquisa em IA ao longo dos últimos 30 anos.
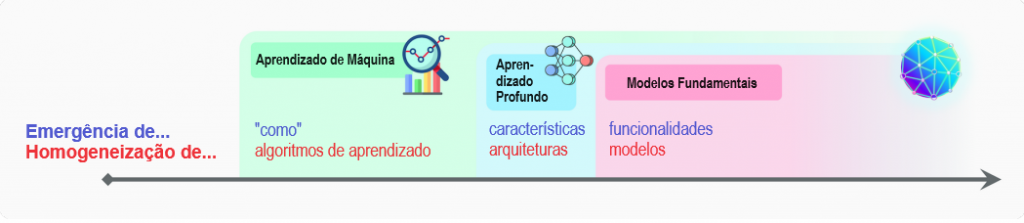
Aprendizado de máquina. A maioria dos sistemas de IA atuais são alimentados por aprendizado de máquina, no qual modelos preditivos são treinados em dados históricos e usados para fazer previsões futuras. A ascensão do aprendizado de máquina na IA começou na década de 1990, representando uma mudança acentuada na forma como os sistemas de IA eram construídos anteriormente: em vez de especificar como resolver uma tarefa, um algoritmo de aprendizado a induziria com base em dados, ou seja, o como emerge da dinâmica de aprendizado. O aprendizado de máquina também representou um passo em direção à homogeneização: uma ampla gama de aplicações agora podia ser alimentada por um único algoritmo de aprendizado genérico, como a regressão logística.
Apesar da onipresença do aprendizado de máquina na IA, tarefas semanticamente complexas em processamento de linguagem natural (PLN) e visão computacional, como resposta a perguntas ou reconhecimento de objetos, nas quais as entradas são frases ou imagens, ainda exigiam que especialistas no domínio executassem “engenharia de características”, isto é, escrever lógica específica ao domínio para converter dados brutos em características de nível superior (p. ex., SIFT [Lowe 1999] em visão computacional), o que era mais adequado para métodos populares de aprendizado de máquina.
Aprendizado profundo. Por volta de 2010, um renascimento das redes neurais profundas sob a alcunha de aprendizado profundo [LeCun et al. 2015] começou a ganhar força na área do aprendizado de máquina. O aprendizado profundo foi alimentado por conjuntos de dados maiores, mais computação (a saber, a disponibilidade de GPUs) e maior audácia. As redes neurais profundas seriam treinadas com base nas entradas brutas (p. ex., pixels), e características de nível superior surgiriam por meio do treinamento (um processo denominado “aprendizado de representação”). Isso levou a enormes ganhos de desempenho em referenciais-padrão, como, por exemplo, no trabalho seminal do AlexNet [Krizhevsky et al. 2012] no conjunto de dados ImageNet [Deng et al. 2009]. O aprendizado profundo também refletiu uma mudança adicional em direção à homogeneização: em vez de ter canalizações de engenharia de características personalizadas para cada aplicação, a mesma arquitetura de rede neural profunda poderia ser usada para muitas aplicações.
Modelos fundamentais. Os modelos fundamentais tomaram forma mais fortemente no PLN; por isso focamos nossa história aqui por enquanto. Apesar disso, por mais que o aprendizado profundo tenha sido popularizado na visão computacional, mas exista além dela, entendemos os modelos fundamentais como um paradigma geral da IA, em vez de específico ao PLN de qualquer forma. No final de 2018, a área do PLN estava prestes a passar por outra mudança sísmica, marcando o início da era dos modelos fundamentais. A nível técnico, os modelos fundamentais são possibilitados pelo aprendizado por transferência [Thrun 1998] e pela escala. A ideia do aprendizado por transferência é pegar o “conhecimento” aprendido a partir de uma tarefa (p. ex., reconhecimento de objetos em imagens) e aplicá-lo a outra tarefa (p. ex., reconhecimento de atividades em vídeos). No aprendizado profundo, o pré-treinamento é a abordagem dominante ao aprendizado por transferência: um modelo é treinado em uma tarefa substituta (muitas vezes apenas como um meio para um fim) e depois adaptado à tarefa posterior de interesse por meio de ajuste fino.
O aprendizado por transferência é o que possibilita os modelos fundamentais, mas a escala é o que os torna poderosos. A escala exigia três ingredientes: (i) melhorias no hardware computacional; p. ex., o rendimento e a memória da GPU aumentaram em 10x nos últimos quatro anos (§4.5: SISTEMAS); (ii) o desenvolvimento da arquitetura do modelo Transformer [Vaswani et al. 2017] que aproveita o paralelismo do hardware para treinar modelos muito mais expressivos do que antes (§4.1: MODELAGEM); e (iii) a disponibilidade de muito mais dados de treinamento.
Não se pode subestimar a importância da disponibilidade de dados e da capacidade de aproveitá-los. O aprendizado por transferência com conjuntos de dados rotulados tem sido uma prática comum há pelo menos uma década, por exemplo, com o pré-treinamento no conjunto de dados ImageNet [Deng et al. 2009] para classificação de imagens na comunidade da visão computacional. No entanto, o custo não trivial da rotulação impõe um limite prático aos benefícios do pré-treinamento.
Por outro lado, no aprendizado autossupervisionado, a tarefa de pré-treinamento é derivada automaticamente de dados não rotulados.3 Por exemplo, a tarefa de modelagem de linguagem mascarada usada para treinar BERT [Devlin et al. 2019] consiste em prever uma palavra que falta em uma frase, dado o contexto circundante (p. ex., eu gosto de couve_____). As tarefas autossupervisionadas não são apenas mais amplificáveis, dependendo apenas de dados não rotulados, mas são feitas para forçar o modelo a prever partes das entradas, tornando-as mais ricas e potencialmente mais úteis do que modelos treinados num espaço de rótulos mais limitado.
Houve um progresso considerável no aprendizado autossupervisionado desde os vetores de palavras [Turian et al. 2010; Mikolov et al. 2013; Pennington et al. 2014], que associavam cada palavra a um vetor independente do contexto e forneceu a base para uma ampla gama de modelos de PLN. Pouco tempo depois, o aprendizado autossupervisionado baseado na modelagem de linguagem autoregressiva (prever a próxima palavra com base nas palavras anteriores) [Dai e Le 2015] tornou-se popular. Isso produziu modelos que representavam palavras em contexto, como GPT [Radford et al. 2018], ELMo [Peters et al. 2018] e ULMFiT [Howard e Ruder 2018].4
A próxima onda de desenvolvimentos no aprendizado autossupervisionado — BERT [Devlin et al. 2019], GPT-2 [Radford et al. 2019], RoBERTa [Liu et al. 2019], T5 [Raffel et al. 2019], BART [Lewis et al. 2020a] — seguiu-se rapidamente, adotando a arquitetura Transformer, incorporando codificadores bidirecionais profundos de frases mais potentes e amplificando para modelos e conjuntos de dados maiores.
Embora possamos ver esta última onda de desenvolvimentos técnicos puramente através das lentes do aprendizado autossupervisionado, houve um ponto de inflexão sociológico em torno da introdução do BERT. Antes de 2019, o aprendizado autossupervisionado com modelos de linguagem era essencialmente uma subárea do PLN, que progrediu paralelamente a outros desenvolvimentos no PLN. Depois de 2019, o aprendizado autossupervisionado com modelos de linguagem tornou-se mais um substrato do PLN, visto que o uso do BERT se tornou a norma. A aceitação de que um único modelo poderia ser útil para uma ampla gama de tarefas marca o início da era dos modelos fundamentais.
Os modelos fundamentais levaram a um nível de homogeneização sem precedentes: quase todos os modelos de PLN do estado da arte são agora adaptados a partir de um dos poucos modelos fundamentais, como BERT, RoBERTa, BART, T5, etc. Embora essa homogeinização produza um aproveitamento extremamente alto (qualquer melhoria nos modelos básicos pode levar a benefícios imediatos em todo o PLN), é também um perigo; todos os sistemas de IA podem herdar os mesmos vieses problemáticos de alguns modelos fundamentais [Bolukbasi et al. 2016; Caliskan et al. 2017; Abid et al. 2021, entre outros]) — ver §5.1: JUSTIÇA, §5.6: ÉTICA, mais discussões.
Também estamos começando a ver uma homogeneização entre as comunidades de pesquisa. Por exemplo, abordagens semelhantes de modelagem de sequência baseadas no Transformer são agora aplicadas a textos [Devlin et al. 2019; Radford et al. 2019; Raffel et al. 2019], imagens [Dosovitskiy et al. 2020; Chen et al. 2020d], fala [Liu et al. 2020d], dados tabulares [Yin et al. 2020], sequências de proteínas [Rives et al. 2021], moléculas orgânicas [Rothchild et al. 2021] e aprendizado por reforço [Chen et al. 2021b; Janner et al. 2021]. Esses exemplos apontam para um futuro possível onde teremos um conjunto unificado de ferramentas para desenvolver modelos fundamentais em uma ampla gama de modalidades [Tamkin et al. 2021b].
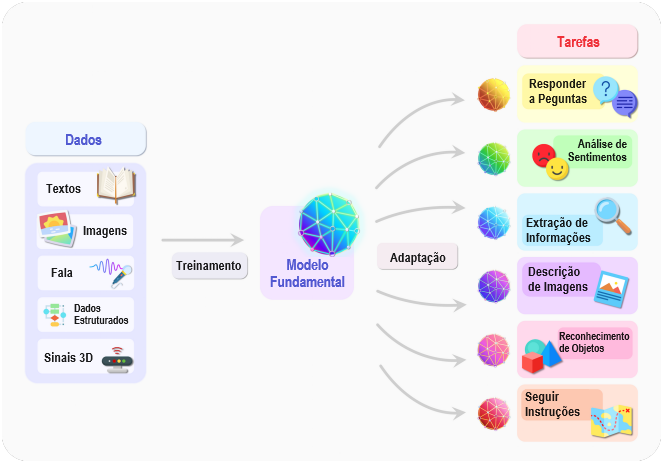
Além da homogeneização de abordagens, também vemos a homogeneização de modelos reais entre comunidades de pesquisa na forma de modelos multimodais: por exemplo, modelos fundamentais treinados em dados de linguagem e visão [Luo et al. 2020; Kim et al. 2021a; Cho et al. 2021; Ramesh et al. 2021; Radford et al. 2021]. Os dados são naturalmente multimodais em alguns domínios: p. ex., imagens médicas, dados estruturados, textos clínicos no cuidado médico (§3.1: CUIDADO MÉDICO). Assim, os modelos fundamentais multimodais são uma forma natural de fundir todas as informações relevantes sobre um domínio e de adaptar a tarefas que também abrangem vários modos (Figura 2).
Os modelos fundamentais também levaram a uma surpreendente emergência resultante da escala. Por exemplo, o GPT-3 [Brown et al. 2020], com 175 bilhões de parâmetros em comparação com 1,5 bilhão do GPT-2, permite o aprendizado no contexto, no qual o modelo de linguagem pode ser adaptado a uma tarefa posterior simplesmente fornecendo-lhe um prompt (uma descrição da tarefa em linguagem natural), uma propriedade emergente que não foi especificamente treinada, tampouco foi previsto que surgiria.
A homogeneização e a emergência interagem de uma forma potencialmente perturbadora. A homogeneização tem o potencial de proporcionar enormes ganhos para muitos domínios nos quais os dados específicos de tarefas são bastante limitados — veja as oportunidades apresentadas em vários desses domínios (por exemplo, §3.1: CUIDADO MÉDICO, §3.2: DIREITO, §3.3: EDUCAÇÃO) —; por outro lado, quaisquer falhas no modelo são herdadas cegamente por todos os modelos adaptados (§5.1: JUSTIÇA, §5.6: ÉTICA). Uma vez que o poder dos modelos fundamentais advém das suas qualidades emergentes e não da sua construção explícita, os modelos fundamentais existentes são difíceis de compreender (§4.4: AVALIAÇÃO, §4.10: TEORIA, §4.11: INTERPRETABILIDADE) e têm modos de falha inesperados (§4.7: SEGURANÇA, §4.8: ROBUSTEZ). Dado que a emergência gera uma incerteza substancial sobre as capacidades e falhas dos modelos fundamentais, a homogeneização agressiva através destes modelos é um negócio arriscado. A eliminação de riscos é o desafio central no desenvolvimento de modelos fundamentais de uma perspectiva ética (§5.6: ÉTICA) e de segurança da IA (§4.9: SEGURANÇA DA IA).
Notas
1. Autor para correspondência: pliang@cs.stanford.edu
2. Escolhemos o termo modelos fundamentais para capturar o status inacabado, porém importante, desses modelos — ver §1.1.1: NOMENCLATURA, para uma discussão mais aprofundada sobre o nome.
3. Curiosamente, o aprendizado autossupervisionado era dominante nos primeiros dias do aprendizado profundo [Hinton et al. 2006], mas foi por uma década vastamente ultrapassado pelo puro aprendizado supervisionado conforme os conjuntos de dados rotulados foram crescendo.
4. O trabalho presciente de Collobert e Weston [2008] está relacionado: eles treinaram em uma tarefa amplificável semelhante à modelagem de linguagem mascarada em conjunto com tarefas subsequentes, em vez de produzir um modelo fundamental único que pode ser adaptado após o ocorrido para tarefas subsequentes.
Referências
Consulte as referências do documento original.
Tradução: Luan Marques
Link para o original