De Jacob Steinhardt. 11 de janeiro de 2022.
Em 1972, o físico ganhador do Prêmio Nobel Philip Anderson escreveu o ensaio “Mais É Diferente”. Nele, ele argumenta que mudanças quantitativas podem levar a fenômenos qualitativamente diferentes e inesperados. Embora ele tenha se concentrado na física, é possível encontrar muitos exemplos de Mais é Diferente também em outros domínios, incluindo a biologia, a economia e a ciência da computação. Alguns exemplos de Mais é Diferente incluem:
- Urânio. Com um pouco de urânio, nada de especial acontece; com uma grande quantidade de urânio compactado de forma suficientemente densa, você tem uma reação nuclear.
- DNA. Dadas apenas moléculas pequenas, como o cálcio, não é possível codificar informações úteis de maneira significativa; dadas moléculas maiores, como o DNA, é possível codificar um genoma.
- Água. As moléculas individuais de água não são molhadas. A umidade só ocorre devido às forças de interação entre muitas moléculas de água intercaladas em um tecido (ou outro material).
- Tráfego. Com alguns carros na estrada, a situação é tranquila, mas com muitos você terá um engarrafamento. Pode ser que 10.000 carros possam atravessar uma rodovia facilmente em 15 minutos, mas 20.000 na estrada ao mesmo tempo podem levar mais de uma hora.
- Especialização. Historicamente, em populações pequenas, praticamente todos precisavam cultivar ou caçar para sobreviver; em contraste, em comunidades maiores e mais densas, são produzidos alimentos suficientes para que grandes parcelas da população se especializem no trabalho não agrícola.
Enquanto alguns dos exemplos, como o urânio, correspondem a uma transição acentuada, outros, como a especialização, são mais contínuos. Usarei emergência para me referir a mudanças qualitativas que surgem de aumentos quantitativos de escala, e transições de fase para casos em que a mudança é acentuada.
Neste post, argumentarei que a emergência ocorre frequentemente no campo da IA e que isso deve afetar significativamente nossas intuições sobre o desenvolvimento e a implementação de sistemas de IA a longo prazo. Deveríamos esperar que fenômenos estranhos e surpreendentes surgissem à medida que amplificamos os sistemas. Isso apresenta oportunidades, mas também apresenta riscos importantes.
Índice
Mudanças emergentes na história da IA
Já houve vários exemplos de diferenças quantitativas que levaram a importantes mudanças qualitativas no aprendizado de máquina.
Armazenamento e aprendizado. O surgimento do aprendizado de máquina como uma abordagem viável para a IA é em si um exemplo de Mais É Diferente. Embora o aprendizado tenha sido discutido desde a década de 1950, foi apenas nas décadas de 80 e 90 que ele se tornou um paradigma dominante: por exemplo, o primeiro modelo de tradução estatística da IBM foi publicado em 1988, embora a ideia tenha sido proposta em 1949.1 Não por coincidência, 1 GB de armazenamento custava mais de US$ 100 mil em 1981, mas apenas cerca de US$ 9 mil em 1990 (ajustado para dólares de 2021). O corpus Hansard usado para treinar o modelo da IBM compreendia 2,87 milhões de frases e teria sido difícil de usar antes dos anos 80. Mesmo o simples conjunto de dados MNIST exigiria US$ 4.000 em hardware apenas para ser armazenado em 1981, mas esse valor caiu para alguns dólares em 1998, quando foi publicado. Hardware mais barato permitiu, portanto, uma abordagem qualitativamente nova à IA: em outras palavras, Mais armazenamento permitiu abordagens Diferentes.
Computação, dados e redes neurais. À medida que o hardware melhorou, tornou-se possível treinar redes neurais muito profundas pela primeira vez. Melhor computação permitiu modelos maiores treinados por mais tempo, e melhor armazenamento permitiu o aprendizado com mais dados; modelos do tamanho do AlexNet e conjuntos de dados do tamanho do ImageNet não seriam viáveis para os pesquisadores experimentarem em 1990.
O aprendizado profundo funciona bem com muitos dados e computação, mas tem dificuldades em escalas menores. Sem muitos recursos, algoritmos mais simples tendem a superá-lo, mas com recursos suficientes ele fica muito à frente da concorrência. Essa reversão da sorte levou a mudanças qualitativas no campo. Por exemplo, o campo da tradução de máquina passou de modelos baseados em frases (características codificadas manualmente, engenharia de sistemas complexos) para modelos neurais de sequência a sequência (características prendidas, arquitetura especializada e inicialização) para o simples ajuste fino de um modelo fundamental como o BERT ou o GPT-3. A maior parte do trabalho em modelos baseados em frases foi evitada pela tradução neural, e o mesmo padrão foi mantido em muitas outras tarefas de linguagem, nas quais o esforço de engenharia específico ao domínio conquistado a duras penas foi simplesmente substituído por um algoritmo geral.
Aprendizado de poucas amostras (few-shot learning). Mais recentemente, o GPT-2 e o GPT-3 revelaram o surgimento de fortes capacidades de poucas ou zero amostra, por meio de prompts de linguagem natural bem escolhidos.

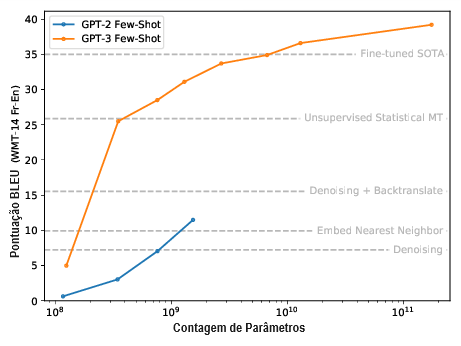
Esse foi um fenômeno inesperado e qualitativamente novo que só apareceu em grandes escalas e surgiu sem nunca treinarmos explicitamente modelos para terem essas capacidades de poucas amostras. Comparar o GPT-2 com o GPT-3 mostra que o tamanho exato do modelo necessário pode variar devido à distribuição do treinamento ou outros fatores, mas isso não afeta a ideia básica de que novas capacidades podem aparecer sem projetarmos ou treinarmos com elas em vista.
Grokking. Em 2021, Power et al. identificaram um fenômeno que chamam de “grokking“, no qual o comportamento de generalização de uma rede melhora qualitativamente ao treiná-la por mais tempo (mesmo que a perda de treinamento já seja pequena).
Especificamente, para certos conjuntos de dados lógicos/matemáticos gerados por algoritmos, as redes neurais treinadas para 1.000 etapas alcançam uma precisão de treinamento perfeita, mas uma precisão de teste quase zero. No entanto, após cerca de 100.000 etapas, a precisão de teste aumenta repentinamente, alcançando uma generalização quase perfeita em 1 milhão de etapas.
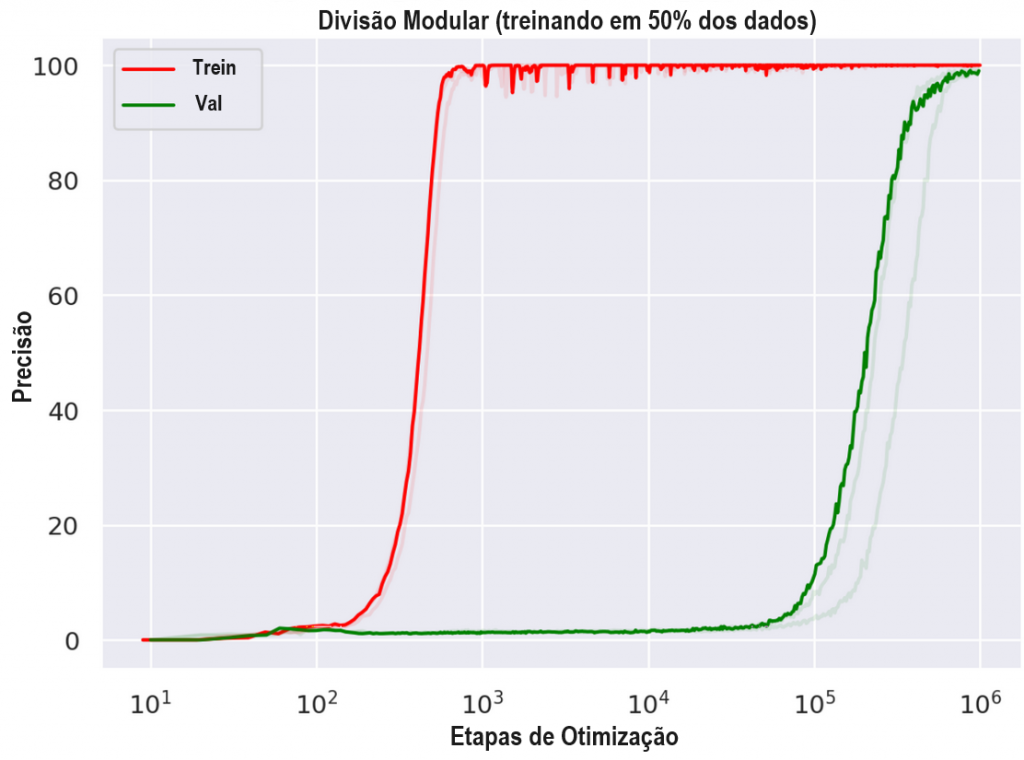
Isso mostra que, mesmo para um único modelo, podemos encontrar transições de fase qualitativas à medida que treinamos por mais tempo.
Outros exemplos potenciais. Listarei brevemente outros exemplos de artigos recentes. Não creio que esses exemplos sejam tão claros individualmente, mas coletivamente pintam um quadro interessante:
- McGrath et al. (2021) mostram que o AlphaZero adquire muitos conceitos de xadrez numa transição de fase próxima a 32.000 etapas de treinamento.
- Pan et al. (2021) mostram que o hackeamento de recompensas às vezes ocorre por meio de transições de fase qualitativas à medida que o tamanho do modelo aumenta.
- O recente modelo Gopher da DeepMind exibe uma transição de fase na tarefa FEVER, adquirindo a capacidade de avaliar evidências fornecidas como informações secundárias (Figura 3):

- Wei et al. (2021) mostram que o ajuste de instruções prejudica modelos pequenos, mas ajuda modelos grandes (veja Figura 6).
- Algumas tarefas de poucas amostras, como a aritmética, mostram transições de fase com o tamanho do modelo (veja Brown et al. (2020), Figura 3.10).
- Este pesquisador compartilha uma anedota parecida com o artigo do “grokking”.
Quais são as implicações disso para a visão de mundo da Engenharia
No post de introdução desta série, comparei duas visões de mundo chamadas Filosofia e Engenharia. A visão de mundo da Engenharia, preferida pela maioria dos pesquisadores de aprendizado de máquina, tende a prever o futuro observando tendências empíricas e extrapolando-as adiante. Eu próprio simpatizo bastante com esta visão e, por essa razão, considero o comportamento emergente perturbador e desorientador. Em vez de esperar que as tendências empíricas continuem, a emergência sugere que devemos muitas vezes esperar novos comportamentos qualitativos que não sejam extrapolações de tendências anteriores.
De fato, nesse sentido, a Engenharia (ou pelo menos a pura extrapolação de tendências) é autodestrutiva enquanto ferramenta para prever o futuro.2 A visão de mundo da Engenharia quer extrapolar tendências, mas uma tendência é que o comportamento emergente está se tornando cada vez mais comum. Das quatro transições de fase que citei acima, a primeira (armazenamento) ocorreu por volta de 1995, e a segunda (computação) ocorreu por volta de 2015. As duas últimas ocorreram em 2020 e 2021. Com base nas tendências passadas, devemos esperar que as tendências futuras se quebrem com cada vez mais frequência.3
Como podemos nos orientar ao pensar sobre o futuro da IA, apesar da probabilidade de desvios frequentes com relação à experiência passada? Terei muito mais a dizer sobre isso nos próximos posts, mas vou colocar algumas das minhas cartas na mesa:
- Enfrentar a emergência exigirá a adoção de mentalidades que são menos familiares para a maioria dos pesquisadores de aprendizado de máquina e a utilização de mais da visão de mundo da Filosofia (em conjunto com a Engenharia e outras visões de mundo).
- Os futuros sistemas de aprendizado de máquina terão modos de falha estranhos que não se manifestam hoje, e devemos começar a pensar sobre eles e lidar com eles com antecedência.
- Por outro lado, não creio que a Engenharia como ferramenta para prever o futuro seja totalmente autodestrutiva. Apesar do comportamento emergente, as descobertas empíricas muitas vezes se generalizam de forma surpreendente, pelo menos se formos cuidadosos na sua interpretação. Utilizar esse fato será crucial para fazer progressos concretos na pesquisa.
Notas
1. Dos autores do modelo IBM: “Em 1949, Warren Weaver sugeriu que o problema fosse atacado com métodos estatísticos e ideias da teoria da informação, uma área que ele, Claude Shannon e outros estavam desenvolvendo na época (Weaver 1949). Embora os investigadores tenham abandonado rapidamente essa abordagem, apresentando numerosas objeções teóricas, acreditamos que os verdadeiros obstáculos residem na relativa impotência dos computadores disponíveis e na escassez de textos legíveis por máquinas a partir dos quais possam reunir as estatísticas essenciais para tal ataque. Hoje, os computadores são cinco ordens de grandeza mais rápidos do que eram em 1950 e possuem centenas de milhões de bytes de armazenamento. Corpora grandes e legíveis por máquinas estão prontamente disponíveis.”
2. Isso contrasta com o uso da Engenharia para construir sistemas capazes e impressionantes hoje. Pelo contrário, os acontecimentos recentes solidificaram fortemente o domínio da Engenharia nessa tarefa.
3. Essa lista provavelmente está sujeita ao viés de seleção e efeitos de recência, embora eu preveja que meu ponto de vista ainda seria válido para uma lista cuidadosamente selecionada (por exemplo, não incluí os vários exemplos ambíguos em minha contagem). Eu ficaria feliz em apostar em mais transições de fase no futuro, se algum leitor quiser ficar do outro lado.
Tradução: Luan Marques
Link para o original