De Scott Alexander. 23 de fevereiro de 2022.
Índice
Introdução
Tenho tentado revisar e resumir os diálogos recentes de Eliezer Yudkowksy sobre segurança da IA. Anteriormente em sequência: Yudkowsky Contra Ngo sobre Agentes. Agora estamos com Yudkowsky contra Cotra sobre âncoras biológicas, mas antes de chegarmos lá, precisamos descobrir do que Cotra está falando e o que está acontecendo.
O Open Philanthropy Project (“Open Phil”) é uma grande fundação altruísta eficaz interessada em financiar a segurança da IA. Tem US$ 20 bilhões, provavelmente a maior parte do dinheiro na área; então as suas decisões são muito importantes e está bem aplicada em acertar as coisas. Em 2020, pediu à pesquisadora sênior Ajeya Cotra que produzisse um relatório sobre quando a IA de nível humano chegaria. Diz que o documento resultante é “informal”, mas tem 169 páginas e provavelmente afetará milhões de dólares de financiamento, o que alguns podem descrever como meio que formal. O relatório encontra uma probabilidade de 10% de “IA transformadora” até 2031, uma probabilidade de 50% até 2052 e uma probabilidade de quase 80% até 2100.
Eliezer rejeita a metodologia da organização e espera a IA mais cedo (ele não oferece muitos números, mas aqui ele dá a Bryan Caplan probabilidades de meio a meio em 2030, embora não totalmente a sério). Ele defendeu isso em seu longo ensaio, Linhas do Tempo da IGA Inspiradas na Biologia: um Truque que Nunca Funciona, gerando um monte de argumentos, e contra-argumentos, e ensaios ainda mais longos.
Já existe uma pequena indústria de resumir o relatório, como, por exemplo, o artigo do diretor-executivo da OpenPhil, Holden Karnofsky, e o comentário do editor da Alignment Newsletter, Rohin Shah. Eu me baseei em ambos para a minha tentativa muito inferior.
Parte I: O Relatório de Cotra
Ajeya Cotra é analista de pesquisa sênior da OpenPhil. Ela é auxiliada por seu noivo Paul Christiano (doutor em ciência da computação, veterano da OpenAI, dirige uma organização sem fins lucrativos de alinhamento da IA) e, em menor grau, por outros líderes. Embora nem todos os envolvidos tenham treinamento formal em aprendizado de máquina, se você se preocupa muito se os esforços são “de dentro do sistema” ou “oposicionistas”, este provavelmente é mais de dentro do sistema.
O relatório pergunta quando teremos pela primeira vez “IA transformadora” (ou seja, IA que produz uma transição tão impressionante quanto a Revolução Industrial; provavelmente isso exigirá que seja tão inteligente quanto humanos). Sua metodologia é:
- Descubra quanta computação inferencial o cérebro humano faz.
- Tente descobrir quanta computação de treinamento seria necessária, neste momento, para conseguir uma rede neural que faz a mesma quantidade de computação inferencial. Consiga um número absurdo de grande.
- Leve em conta o “progresso algorítmico”, ou seja, talvez no futuro as redes neurais sejam melhores no uso de recursos computacionais de forma eficiente. Consiga um número que, de modo realista, ainda seja absurdo de grande.
- Provavelmente, se você quisesse aquela quantidade de computação absurda de grande, seria necessária alguma quantia de dinheiro absurda de grande. Mas a computação está ficando mais barata a cada ano. Além disso, a economia cresce a cada ano. Além disso, a parcela da economia direcionada aos investimentos em empresas de IA cresce a cada ano. Então, em algum momento, alguma empresa de IA realmente será capaz de arcar com aquela quantia de dinheiro absurda de grande, implementar a quantidade de computação absurda de grande e treinar a IA que tem a mesma computação inferencial que o cérebro humano.
- Descubra em que ano isso será.
Isso codifica muitas suposições questionáveis? Por exemplo, a IGA poderia vir de um ecossistema de projetos interativos (por exemplo, como a Revolução Industrial surgiu de um ecossistema de tecnologias interativas) de modo que ninguém tivesse que treinar uma IA inteira do tamanho de um cérebro de uma só vez? Talvez; na verdade, Ajeya pensa que o cenário da Revolução Industrial pode ser mais provável do que o cenário da execução única. Mas ela considera o cenário da execução única um limite superior útil (posteriormente, ela menciona outras razões para tratá-lo como um limite inferior e se compromete a tratá-lo como uma estimativa central) e ainda acha que vale a pena descobrir quanto tempo levará.
Então, vamos seguir as etapas, uma por uma.
Quanta computação o cérebro humano faz?
O primeiro passo – descobrir quanta computação o cérebro humano faz – é uma tarefa assustadora. Uma solução bem-sucedida se pareceria com uma série de FLOP/S (operações de ponto flutuante por segundo), uma unidade básica de computação em computadores digitais. Felizmente para Ajeya e para nós, outro analista da OpenPhil, Joe Carlsmith, concluiu um relatório sobre isso alguns meses antes. Concluiu que o cérebro provavelmente usa 10^13 – 10^17 FLOP/S. Por quê? Em parte, porque esse foi o número fornecido pela maioria dos especialistas. Mas também existem cerca de 10^15 sinapses no cérebro, cada qual disparando cerca de uma vez por segundo, e um pico sináptico provavelmente faz cerca de um FLOP de computação.
(Não tenho certeza se ele está levando em conta pesquisas recentes que sugerem que a computação às vezes acontece dentro dos dendritos — veja a seção 2.1.1.2.2 de seu relatório para complicações e por que ele se sente bem em ignorá-las —, mas, de forma realista, há muitas áreas cinzentas de tamanhos de ordem de grandeza aqui, e ele fornece uma gama suficientemente ampla que, contanto que as incógnitas desconhecidas não estejam todas na mesma direção, está tudo bem.)
Então, uma IA de nível humano também precisaria realizar 10^15 operações de ponto flutuante por segundo? Não está claro. Os computadores podem funcionar com algoritmos mais ou menos eficientes; redes neurais podem usar sua computação de forma mais ou menos eficaz do que o cérebro. Você pode pensar que seria mais eficiente, uma vez que os designers humanos podem fazer melhor do que o acaso cego da evolução. Ou você pode pensar que seria menos eficiente, uma vez que muitos processos biológicos ainda estão muito além da tecnologia humana. Ou você pode fazer o que o OpenPhil fez e só olhar alguns exemplos de sistemas evoluídos versus sistemas projetados e ver quais são geralmente melhores:
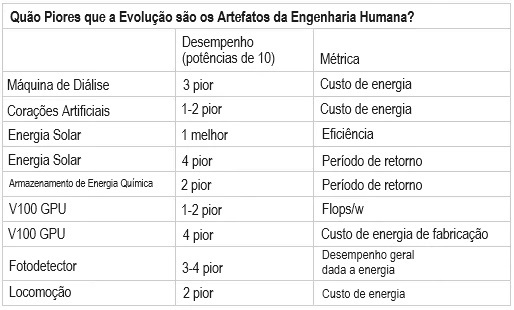
Ajeya combina isso com outra métrica na qual veem como a IA existente se compara a animais com capacidade computacional aparentemente semelhante; por exemplo, ela diz que o mecanismo Starcraft da DeepMind tem tanta computação inferencial quanto uma abelha e parece igualmente impressionante, subjetivamente falando. Eu não tenho ideia do que isso significa. Impressionante no quê? Ganhar jogos on-line de vários jogadores? Picar gente? De qualquer forma, eles decidem penalizar a IA em uma ordem de grandeza em comparação com a Natureza, de modo que uma IA de nível humano precisaria fazer 10^16 operações de ponto flutuante por segundo.
Quanta computação seria necessária para treinar um modelo que faz 10^16 operações de ponto flutuante por segundo?
Portanto, uma IA poderia igualar o cérebro humano com 10^16 FLOP/S.
Boas notícias! Há um supercomputador no Japão capaz de fazer 10^17 FLOP/S!

Então, por que ainda não temos IA? Por que não temos dez IAs?
No paradigma moderno de aprendizado de máquina, são necessários computadores muito grandes para treinar IAs de produto final relativamente pequenas. Se você tentasse treinar o GPT-3 no mesmo tipo de computador de tamanho médio em que você o executa, levaria entre dezenas e centenas de anos. Em vez disso, você treina o GPT-3 em supercomputadores gigantes como os acima, obtém resultados em alguns meses e então o executa em computadores de tamanho médio, talvez cerca de 10 vezes melhores que um desktop comum.
Mas nossa futura IA hipotética de nível humano é 10^16 FLOP/S no modo de inferência. Precisa rodar em um supercomputador gigante como o da foto. Nada do que temos agora poderia sequer começar a treiná-la.
Não há uma maneira direta e óbvia de converter requisitos de inferência em requisitos de treinamento. Ajeya tenta presumir que cada parâmetro contribuirá com cerca de 10 FLOPs, o que significaria que o modelo teria cerca de 10^15 parâmetros (o GPT-3 tem cerca de 10^11 parâmetros). Finalmente, ela usa algumas leis de amplificação empíricas derivadas da observação de projetos de aprendizado de máquina para estimar que o treinamento de 10^15 parâmetros exigiria H * 10^30 FLOPs, sendo que H representa o “horizonte” do modelo.
Se bem entendi, “horizonte” é um conceito de aprendizado por reforço: quanto tempo leva para saber quanta recompensa você recebeu por alguma coisa? Se você está jogando em uma máquina caça-níqueis, a resposta é um segundo. Se você está abrindo uma empresa, a resposta pode ser dez anos. Então, qual horizonte você precisa para uma IA de nível humano? Quem sabe? Provavelmente depende de que tarefa de nível humano você deseja que a IA execute, além de quão bem uma IA pode aprender a realizar essa tarefa a partir de coisas menos complexas do que a tarefa inteira. Se escrever um bom livro é principalmente aprender a escrever boas frases e, em seguida, juntá-las, uma IA que escreve livros pode se safar com um horizonte curto. Se nada menos que escrever um livro inteiro e depois avaliá-lo para ver se é bom ou ruim pode ensinar você a escrever livros, a IA precisará de um longo horizonte de tempo. Ajeya não afirma ter uma grande resposta para isso e considera três modelos: horizontes de alguns minutos, algumas horas e alguns anos. Cada passo acrescenta mais três ordens de grandeza; então, ela termina com três estimativas de 10^30, 10^33 e 10^36 FLOPs.
(Como referência, a estimativa de treinamento mais baixa — 10^30 — levaria o supercomputador retratado acima 300.000 anos para completar; a mais alta, 300 bilhões.)
E se ignorarmos tudo isso e fizermos outra coisa?
Isso está acumulando muitas suposições; então, Ajeya tenta três outros métodos de descobrir quão difícil é essa tarefa de treinamento.
Os humanos parecem ser IAs de nível humano. De quanto treinamento nós precisamos? Você pode fazer uma analogia da nossa infância com o período de treinamento de uma IA. Recebemos um fluxo de dados dos sentidos. Começamos nos debatendo meio que aleatoriamente. Parte do que fazemos é recompensado. Parte do que fazemos é punido. Nosso comportamento acaba se tornando mais sofisticado. Submetemos nosso novo comportamento a recompensas ou punições, fazendo mais ajuste fino nele.
O musical Rent nos pergunta: como você mede a vida de uma mulher ou de um homem? Ele responde: “Em luzes do dia, em pores do sol, em meias-noites, em xícaras de café; em centímetros, em quilômetros, em risos, em conflitos.” Mas você também pode medir em operações de ponto flutuante, e nesse caso, a resposta é cerca de 10^24. Na verdade, isso é trivial: multiplique os 10^15 FLOP/S do cérebro humano pelos ~10^9 segundos de infância e adolescência. Essa nova estimativa de 10^24 é muito inferior à nossa estimativa de rede neural de 10^30 – 10^36 acima. Na verdade, é apenas um fio de cabelo acima da quantidade necessária para treinar o GPT-3! Se a IA de nível humano fosse tão fácil, deveríamos tê-la atingido por acidente em algum momento do processo de fabricação de um protótipo do GPT-4. Como a OpenAI não mencionou isso, provavelmente é mais difícil do que isso e está faltando alguma coisa.
Provavelmente estamos esquecendo que os humanos não são uma folha em branco. Não é que começamos do zero e depois usamos apenas a nossa infância para nos treinar ainda mais. A própria estrutura do nosso cérebro codifica certas suposições sobre que tipos de dados devemos procurar e como devemos usá-los. Nossos dados de treinamento não são só o que observamos durante a infância; são tudo o que qualquer um dos nossos ancestrais observaram durante a evolução. Quantas operações de ponto flutuante é o processo evolutivo?
Ajeya estima 10^41. Não acredito que estou escrevendo isso. Não posso acreditar que alguém, na verdade, estimou o número de operações de ponto flutuante envolvidas em águas-vivas saindo do lodo primordial e acabando por se tornar peixes, lagartos, mamíferos e assim por diante até a Descendência do Homem. Ainda assim, a ideia é simples. Você estima há quanto tempo os animais com neurônios existem (10^16 segundos), o número total de animais em qualquer determinado segundo (10^20) vezes o número médio de FLOPS por animal (10^5) e você pode ler mais aqui, mas resulta em 10^41 FLOPs. Eu não chamaria isso de estimativa exata — por um lado, presume que todos os animais são nematelmintos, alegando que os animais não nematelmintos são basicamente um erro de arredondamento no grande esquema das coisas. Mas isso de fato justifica essa suposição bizarra, e não me sinto inclinado discutir minúcias aqui: não é certo que a quantidade total de computação realizada pela evolução é irrelevante, exceto como um limite superior extremo? Não é certo que a parte em que a Austrália conseguiu todos aqueles marsupiais estranhos não era estritamente necessária para o cérebro humano ter inteligência de nível humano?
Mais uma tentativa esquisita de estimativa de dados de treinamento humano: e o genoma? Se em algum sentido um pouco de informação no genoma é um “parâmetro”, quantos parâmetros isso sugere que os humanos têm, e como isso afeta o tempo de treinamento? Ajeya calcula que o genoma tem cerca de 7,5×10^8 parâmetros (em comparação com 10^15 parâmetros em nosso cálculo de rede neural e 10^11 para o GPT-3). Então, podemos…
Ok, tenho que admitir, isso não tem exatamente o mesmo fator “hein?!” que tentar calcular o número de FLOPs na evolução, mas em muitos aspectos é ainda mais doido. A planta da flor Paris japonica tem um genoma cinquenta vezes maior do que o nosso, o que sugere que o tamanho do genoma não corresponde muito bem à grandiosidade do organismo. Além disso, a maior parte do genoma codifica proteínas estranhas que estabilizam o formato do túbulo renal ou algo assim. Por que isso deveria ser importante para a inteligência?

Acho que Ajeya responderia que ela está debatendo ordens de grandeza aqui, e cada uma dessas coisas estranhas custa apenas algumas ordens de grandeza e provavelmente todas elas se igualam. Isso ainda deixa a questão de por que ela acha que essa abordagem é interessante; e a isso ela responde o seguinte:
A intuição motivadora é que a evolução realizou uma busca num espaço de genomas pequenos e compactos que codificavam cérebros grandes, em vez de buscar diretamente no espaço muito maior de todos os cérebros grandes possíveis, e os pesquisadores humanos poderão competir com a evolução nesse eixo.
Então, talvez, em vez de ter que descobrir como gerar um cérebro propriamente dito, você descubra como gerar algum programa (mais) curto que possa emitir um cérebro? Mas isso seria muito diferente de como o aprendizado de máquina funciona agora. Além disso, você precisa dar a cada programa curto a chance de se desenrolar em um cérebro antes que você possa avaliá-lo, algo para o qual a evolução tem tempo, mas provavelmente não temos.
Ajeya meio que menciona esses problemas e rebate com o argumento de que talvez você possa pensar no genoma como um aprendizado por reforço com um longo horizonte. Não entendo bem isso, mas parece o tipo de coisa que quase pode fazer sentido. De qualquer forma, quando você aplica as leis de amplificação a um genoma de parâmetro 7,5*10^8 e o penaliza por um longo horizonte, você obtém cerca de 10^33 FLOPs, o que é estranhamente semelhante a algumas das outras estimativas.
Portanto, agora temos seis estimativas de custos de treinamento diferentes. Primeiro, redes neurais com horizontes curto, médio e longo, que são 10^30, 10^33 e 10^36 FLOPs, respectivamente. Em seguida, a quantidade de dados de treinamento durante a vida humana – 10^24 FLOs – e em toda a história evolutiva – 10^41 FLOPs. E, finalmente, esse negócio estranho do genoma, que tem 10^33 FLOPs.
Um otimista pode dizer: “Bem, nossa estimativa mais baixa é 10^24 FLOPs; nossa mais alta é 10 ^ 41 FLOPs; esses números parecem semelhantes; pelo menos não há ‘5 FLOPs’ ou ’10^9999 FLOPs’ ali.”
Um pessimista pode dizer: “A diferença entre 10^24 e 10^41 é de dezessete ordens de grandeza, ou seja, um fator de 100.000.000.000.000.000 de vezes. Isso quase não restringe nossas expectativas!”
Antes de decidirmos em quem confiar, vamos lembrar que ainda estamos apenas no Passo 2 da nossa metodologia de oito passos e continuar.
Como levamos em conta o progresso algorítmico?
Portanto, hoje, em 2022 (ou em 2020, quando isso foi escrito, ou quando for), suponha que seria necessário cerca de 10^33 FLOPs para treinar uma IA de nível humano.
Mas a tecnologia avança constantemente. Talvez descubramos maneiras de treinar IAs mais rapidamente ou de executar IAs mais eficientemente, ou algo parecido. Como isso influencia a nossa estimativa?
Ajeya baseia-se em Medindo a Eficiência Algorítmica das Redes Neurais, de Hernandez & Brown. Eles analisam quantos FLOPs foram necessários para treinar várias IAs de reconhecimento de imagem para um nível equivalente de desempenho entre 2012 e 2019 e descobrem que ao longo desses sete anos diminuiu por um fator de 44x, ou seja, a eficiência do treinamento dobra a cada dezesseis meses! Ajeya presume um tempo de duplicação um pouco maior do que isso, porque é mais fácil fazer progresso em campos simples e bem compreendidos, como o reconhecimento de imagens, do que na nova tarefa de IA de nível humano. Ela escolhe um tempo de duplicação de “apenas” 2 a 3 anos.
Se a eficiência do treinamento duplicar a cada 2-3 anos, ela diminuirá em cerca de 10 anos. Então embora possam ser necessários 10^33 FLOPs para treinar uma IA de nível humano hoje, em dez anos ou mais isso pode levar só 10^32, em vinte anos 10 ^ 31 e assim por diante.
Quando alguém terá recursos computacionais suficientes para treinar uma IA de nível humano
Em 2020, os pesquisadores de IA podiam comprar recursos computacionais por cerca de US$ 1 por 10^17 FLOPs. Isso significa que os 10^33 FLOPs necessários para treinar uma IA de nível humano custariam US$ 10^16, ou seja, dez quatrilhões de dólares. Isso é cerca de vinte vezes mais dinheiro do que existe no mundo inteiro.
Mas os custos computacionais caem rápido. Algumas formulações da Lei de Moore sugerem que ela reduz pela metade a cada dezoito meses. Isso não parece mais se manter exatamente, mas parece estar caindo sim pela metade talvez uma vez a cada 2,5 anos. O número exato é meio controverso: Ajeya admite que ultimamente tem estado mais para uma vez a cada 3-4 anos, mas ela ouviu coisas boas sobre alguns chips futuros e previu que poderia voltar à tendência mais rápida de longo prazo (já se passaram dois anos, alguns novos chips foram lançados e essa previsão parece muito boa).
Assim, com o passar do tempo, o progresso algorítmico reduzirá o custo do treinamento (em FLOPs), e o progresso do hardware também reduzirá o custo dos FLOPs (em dólares). Portanto, o treinamento se tornará gradualmente mais acessível com o passar do tempo. Quando atingir um custo que uma pessoa esteja disposta a pagar, ela comprará uma IA de nível humano, e então esse será o ano em que a IA de nível humano acontecerá.
Qual é o custo que alguém (empresa? governo? bilionário?) está disposto a pagar por uma IA de nível humano?
O treinamento de IA mais caro da história foi o AlphaStar, um projeto da DeepMind que gastou mais de US$ 1 milhão para treinar uma IA para jogar StarCraft (em sua defesa, ele ganhou). Mas as pessoas têm investido cada vez mais dinheiro em IA ultimamente:
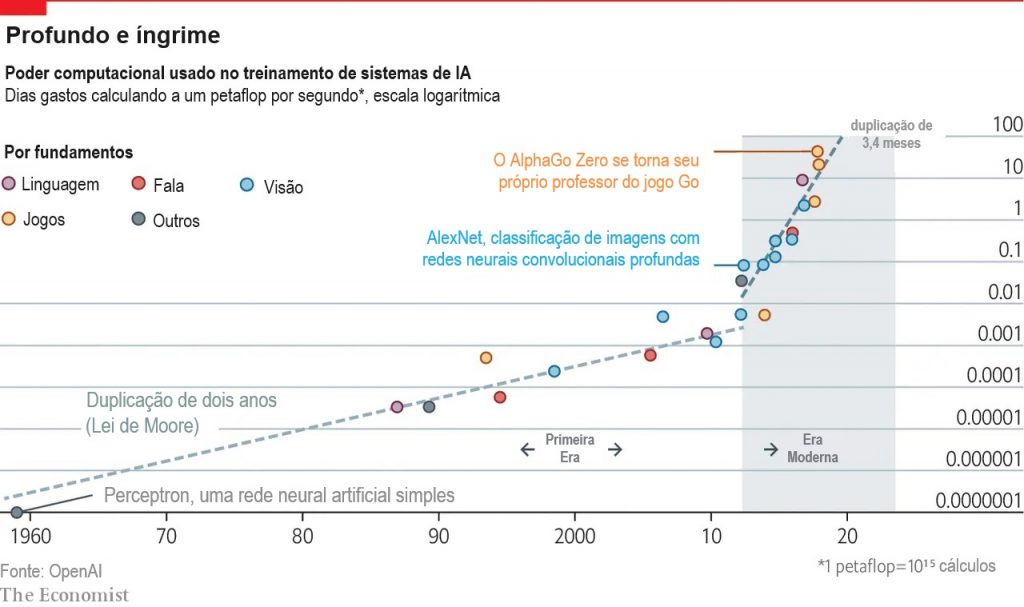
A IA de StarCraft era uma espécie de projeto de vaidade, ou ciência pela ciência, ou chame como quiser. Mas a IA está começando a se tornar lucrativa, e a IA de nível humano seria muito lucrativa. Quem sabe quanto as empresas estarão dispostas a pagar no futuro?
Ajeya extrapola a linha do gráfico para 2025 e obtém US$ 1 bilhão. Isso está começando a parecer um tanto absurdo: a empresa Open AI inteira foi fundada com US$ 1 bilhão em capital de risco; parece muito esperar que ela gaste mais de US$ 1 bilhão em um único treinamento. Portanto, Ajeya recua após 2025 e prevê um “tempo de duplicação de dois anos”. Isso não é exatamente uma concessão. Ainda significa que em 2040 alguém poderá estar gastando US$ 100 bilhões para treinar uma IA.
Isso sequer é plausível? No auge do Projeto Manhattan, os EUA investiram cerca de 0,5% do seu PIB nesse esforço; um investimento semelhante hoje valeria US$ 100 bilhões. E somos cerca de duas vezes mais ricos que 2000, de modo que 2040 poderá ser duas vezes mais rico que nós. Nesse ponto, US$ 100 bilhões para treinar uma IA estão ao alcance da Google e talvez de alguns indivíduos bilionários (apesar de que isso ainda exigiria a maior parte da sua fortuna ou toda ela).
Ajeya cria uma função complicada para avaliar quanto dinheiro as pessoas estarão dispostas a pagar em projetos gigantes de IA por ano. Isso parece uma curva de inclinação ascendente. A linha que representa o custo provável de treinar uma IA de nível humano parece uma curva de inclinação descendente. Em algum ponto, essas duas curvas se encontram, representando quando a IA de nível humano será treinada pela primeira vez.
Então, quando obteremos IA de nível humano?
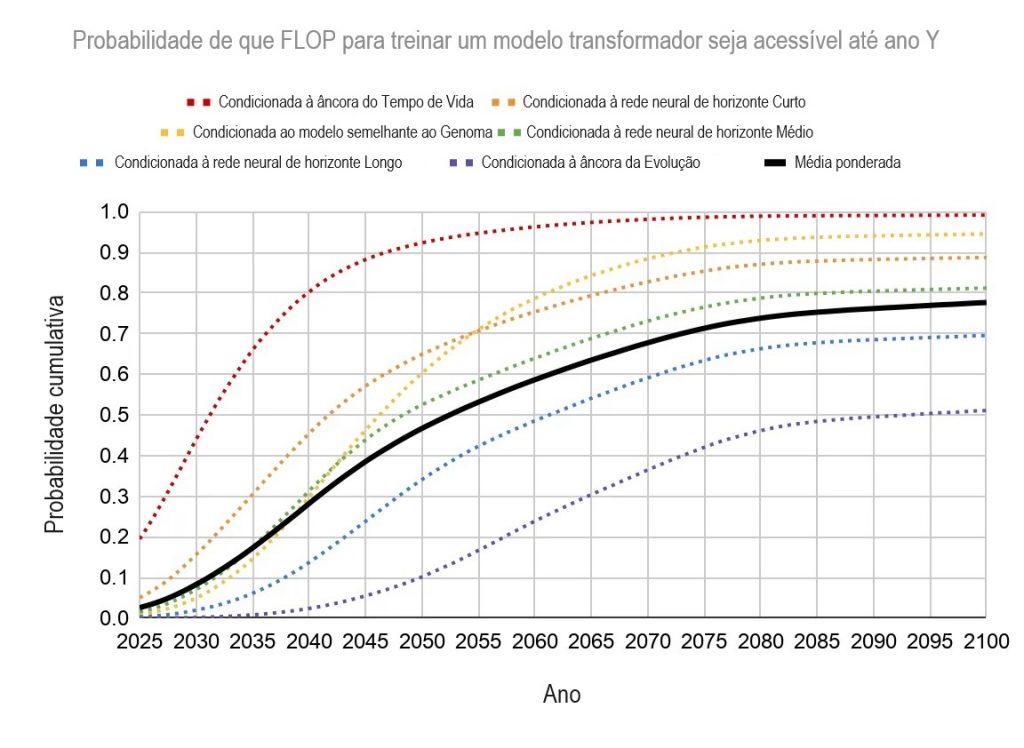
O relatório fornece uma longa distribuição de datas com base nos pesos atribuídos aos seis diferentes modelos, cada qual com intervalos de confiança realmente amplos e opções para ajustar a média e variância com base em suas suposições. Mas a mediana de tudo isso é 10% de chance até 2031, 50% de chance até 2052 e quase 80% de chance até 2100.
Ajeya pega seus seis modelos e decide pesá-los assim, com base em quão plausível ela acha que cada um é:
- 20% rede neural, horizonte curto
- 30% rede neural, horizonte médio
- 15% rede neural, horizonte longo
- 5% vida humana como dados de treinamento
- 10% história evolutiva como dados de treinamento
- 10% genoma como número de parâmetro
Ela termina com isto:
Tradução: Luan Marques
Link para o original