De Dan Hendrycks e Mantas Mazeika. 20 de setembro de 2022.
Índice
Resumo
A inteligência artificial (IA) tem o potencial de melhorar muito a sociedade, mas, como qualquer tecnologia poderosa, ela vem com riscos e responsabilidades acentuados. As pesquisas atuais em IA carecem de uma discussão sistemática sobre como gerenciar os riscos de longo prazo dos sistemas de IA, incluindo riscos especulativos de longo prazo. Mantendo em mente os benefícios potenciais da IA, há alguma preocupação de que construir sistemas de IA cada vez mais inteligentes e poderosos possa acabar resultando em sistemas mais poderosos do que nós; alguns dizem que isso é como brincar com fogo e especulam que isso poderia criar riscos existenciais (riscos x). Para adicionar precisão e fundamentar essas discussões, fornecemos um guia sobre como analisar os riscos x da IA, que consiste em três partes: primeiro, revisamos como os sistemas podem ser tornados mais seguros hoje, baseando-nos em conceitos testados pelo tempo de análise de riscos e segurança de sistemas que foram feitos para orientar grandes processos para direções mais seguras. Em seguida, discutimos estratégias para ter impactos de longo prazo na segurança de sistemas futuros. Finalmente, discutimos um conceito crucial para tornar os sistemas de IA mais seguros, melhorar o equilíbrio entre segurança e capacidades gerais. Esperamos que este documento e os conceitos e ferramentas apresentados sirvam como um guia útil para entender como analisar os riscos x da IA.
4. Equilíbrio entre segurança e capacidades
Discutimos como melhorar a segurança dos sistemas futuros em geral. No entanto, um conceito adicional necessário para analisar os riscos futuros da IA em particular é o equilíbrio entre segurança e capacidades, sem o qual houve muita confusão sobre como reduzir inequivocamente os riscos x. Primeiro discutimos a associação entre segurança e capacidades e distinguimos as duas. Em seguida, discutimos como as buscas bem-intencionadas pela segurança podem ter consequências não pretendidas, dando exemplos concretos de pesquisas de segurança que avançam capacidades e vice-versa. Para evitar futuras consequências não pretendidas, propomos que os pesquisadores demonstrem que estão melhorando o equilíbrio entre segurança e capacidades.
Como preliminar, observamos que “capacidades gerais” se relaciona a conceitos como a precisão de um modelo em tarefas típicas, habilidades de tomada de decisão sequencial em ambientes típicos, habilidades de raciocínio em problemas típicos, e assim por diante. Devido ao teorema do nenhum almoço grátis [68], não nos referimos a todas as tarefas matematicamente definíveis.
A Inteligência Pode Ajudar ou Prejudicar a Segurança. Modelos que são tornados mais inteligentes poderiam evitar falhas mais facilmente e agir de modo mais seguro. Ao mesmo tempo, modelos de maior inteligência poderiam agir mais facilmente de forma destrutiva ou ser direcionados maliciosamente. Da mesma forma, uma IA forte poderia nos ajudar a tomar decisões mais acertadas e nos ajudar a alcançar um futuro melhor, mas a perda de controle também é uma possibilidade. A inteligência bruta é uma espada de dois gumes e não está intrinsecamente ligada a comportamentos desejáveis. Por exemplo, é bem conhecido que virtudes morais são distintas de virtudes intelectuais. Um agente que é conhecedor, inquisitivo, perspicaz e rigoroso não é necessariamente honesto, justo, avesso ao poder ou gentil [2, 39, 3]. Consequentemente, queremos que nossos modelos tenham mais do que apenas inteligência bruta.
Efeitos Colaterais da Otimização de Métricas de Segurança. Tentativas de dotar os modelos com mais do que inteligência bruta podem levar a consequências não pretendidas. Em particular, tentativas de buscar pautas de segurança às vezes podem acelerar o surgimento de riscos da IA. Por exemplo, suponha que um objetivo de segurança seja concretizado por meio de uma métrica de segurança e um pesquisador tente criar um modelo que melhore essa métrica de segurança. Na Figura 3, o pesquisador poderia melhorar o modelo A apenas melhorando a métrica de segurança (modelo B), ou avançando simultaneamente na métrica de segurança e nas capacidades gerais (modelo C). Neste último caso, o pesquisador melhorou as capacidades gerais e como efeito colateral aumentou a inteligência do modelo, o que estabelecemos ter um impacto ambíguo na segurança. Chamamos esses aumentos de externalidades de capacidades, mostradas na Figura 3. Isso não sugere que as capacidades sejam boas ou ruins em si mesmas; elas podem ajudar ou prejudicar a segurança e acabar sendo necessárias para ajudar a humanidade a alcançar seu pleno potencial.
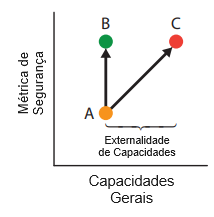
Exemplos de Capacidades → Metas de Segurança. Agora fornecemos exemplos concretos para ilustrar como a segurança e capacidades gerais estão associadas. O aprendizado autossupervisionado pode aumentar a precisão e a eficiência dos dados, mas também pode melhorar várias metas de segurança em robustez e monitoramento [36]. O pré-treinamento torna os modelos mais precisos e extensíveis, mas também melhora várias metas de robustez e monitoramento [34]. Melhorar o modelo de mundo de um agente o torna mais geralmente capaz, mas isso também pode torná-lo menos propenso a gerar consequências não pretendidas. Otimizadores que operam ao longo de horizontes temporais mais longos serão capazes de alcançar metas mais difíceis, mas isso também poderia fazer com que os modelos agissem com mais prudência e evitassem realizar ações irreversíveis.
Exemplos de Metas de Segurança → Capacidades. Alguns argumentam que uma meta de segurança é modelar as preferências do usuário, mas dependendo das preferências modeladas, isso pode ter externalidades de capacidades previsíveis. Sistemas de recomendação, publicidade, busca e tradução de máquina fazem uso do feedback humano e das preferências reveladas para melhorar seus sistemas. Trabalhos recentes em modelos de linguagem utilizam o aprendizado por reforço para incorporar as preferências do usuário sobre uma série geral de tarefas, como sumarização, resposta a perguntas e geração de código [27, 53, 4]. Aproveitar preferências de tarefas, frequentemente estilizadas como “valores humanos”, pode significar tornar os modelos mais inteligentes de forma geral, já que os usuários preferem modelos mais inteligentes. Em vez de modelar preferências de tarefas, os pesquisadores poderiam como alternativa minimizar as externalidades de capacidades, modelando valores humanos atemporais, como fatores normativos [40] e bens intrínsecos (p. ex., prazer, conhecimento, amizade, e assim por diante).
Alguns argumentam que uma meta de segurança é a veracidade, mas tornar os modelos mais verazes pode ter externalidades de capacidades previsíveis. Aumentar a veracidade pode consistir em aumentar a precisão, a calibração e a honestidade. Aumentar a precisão-padrão claramente avança capacidades gerais; então os pesquisadores que visam melhorar claramente a segurança fariam bem em trabalhar mais especificamente em direção à calibração e à honestidade.
Razão entre Segurança e Capacidades. Como vimos, melhorar as métricas de segurança não necessariamente melhora nossa segurança global. Melhorar uma métrica de segurança pode melhorar nossa segurança, tudo o mais igual. No entanto, muitas vezes tudo o mais não é igual, já que as capacidades também são melhoradas; então nossa segurança global não necessariamente aumentou. Consequentemente, para avançar, os pesquisadores de segurança devem realizar uma análise de risco mais holística que relata simultaneamente métricas de segurança e externalidades de capacidades, a fim de demonstrar uma redução no risco total. Sugerimos que os pesquisadores melhorem o equilíbrio entre segurança e capacidades gerais ou, por assim dizer, melhorem uma razão entre segurança e capacidades. Para ser ainda mais cautelosa e ter um efeito menos ambíguo na segurança, sugerimos que a pesquisa de segurança busque evitar externalidades de capacidades gerais. Isso ocorre porque a pesquisa de segurança deve consistentemente melhorar a segurança mais do que seria melhorada por padrão.
Isso certamente não sugere que a pesquisa de segurança está em conflito com a pesquisa de capacidades; os efeitos gerais do aumento das capacidades na segurança são simplesmente ambíguos, conforme estabelecido anteriormente. Enquanto desenvolvemos a IA com precaução, seria benéfico evitar uma estrutura contraproducente de “segurança versus capacidades”. Em vez disso, os pesquisadores de capacidades devem focar cada vez mais nos benefícios potenciais da IA, e os pesquisadores de segurança devem se concentrar em minimizar quaisquer riscos potenciais de longo prazo. Esse processo funcionaria melhor se fosse feito de forma colaborativa, e não adversária, de maneira semelhante à colaboração de engenheiros de software de segurança da informação com outros engenheiros de software. Enquanto outros pesquisadores avançam em capacidades gerais, os pesquisadores de segurança podem melhorar diferencialmente [6] a segurança, melhorando a relação entre segurança e capacidades.
Agora consideramos objeções a esta visão. Alguns pesquisadores podem argumentar que precisamos avançar nas capacidades (p. ex., capacidades de raciocínio, descoberta da verdade e contemplação) para estudar alguns problemas de segurança de longo prazo. Isso não parece ser resilientemente benéfico para a segurança e não parece ser necessário, pois existem inúmeros problemas de pesquisa existentes negligenciados, importantes e tratáveis. Em contraste, avançar nas capacidades gerais obviamente não é algo negligenciado. Além disso, os pesquisadores de segurança poderiam contar com o restante da comunidade para melhorar as capacidades a montante e, finalmente, usar essas capacidades para estudar problemas relevantes para a segurança. Em seguida, equipes de pesquisa podem argumentar que têm as mais puras das motivações, de modo que sua organização deve avançar nas capacidades para ultrapassar a concorrência e construir IA forte o mais rápido possível. Mesmo se uma grande vantagem sobre todo o campo puder ser sustentada de forma confiável e previsível, o que é altamente duvidoso, isso não necessariamente é uma maneira melhor de reduzir os riscos do que canalizar recursos adicionais para a pesquisa de segurança. Por fim, alguns argumentam que o trabalho em segurança levará a uma falsa percepção de segurança e fará com que os modelos sejam implementados mais cedo. Atualmente, muitas empresas claramente carecem de esforços críveis de segurança (p. ex., muitas empresas não possuem uma equipe de pesquisa de segurança), mas no futuro a comunidade deve estar atenta a uma falsa sensação de segurança, como é importante em outras indústrias.
Recomendações Práticas. Para ajudar os pesquisadores a terem um impacto menos ambíguo e mais claro na segurança, sugerimos dois passos. Primeiro, os pesquisadores devem medir empiricamente em que medida seu método melhora sua meta ou métrica de segurança (p ex., AUROC de detecção de anomalias, precisão de robustez adversária, etc.); metas de segurança mais concretas podem ser encontradas em [33] e no Apêndice B. Segundo, os pesquisadores devem medir se seu método pode ser usado para aumentar as capacidades gerais, medindo seu impacto nos correlatos de capacidades gerais (p. ex., recompensa no Atari, precisão no ImageNet, etc.). Com esses valores estimados, os pesquisadores podem determinar se melhoraram diferencialmente o equilíbrio entre segurança e capacidades. Pesquisadores mais cautelosos também podem observar se sua melhoria é aproximadamente ortogonal às capacidades gerais e tem externalidades de capacidades mínimas. É assim que a pesquisa empírica que alega melhorar diferencialmente a segurança pode demonstrar uma melhoria diferencial na segurança empiricamente.
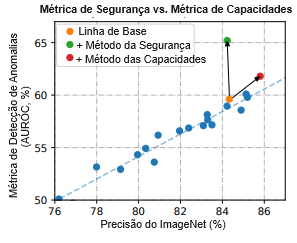
Aplicação: Detecção de Anomalias. Para ajudar a concretizar nossa discussão, aplicamos os vários conceitos desta seção à detecção de anomalias. Conforme mostrado na Figura 4, as medidas de segurança de detecção de anomalias estão correlacionadas com a precisão dos modelos-padrão, mas o progresso diferencial é possível sem simplesmente aumentar a precisão. Um gráfico semelhante está em um artigo de pesquisa anterior [31]. O gráfico mostra que é possível melhorar a detecção de anomalias sem externalidades de capacidades substanciais, de modo que o trabalho na detecção de anomalias pode melhorar o equilíbrio entre segurança e capacidades.
Referências
Consulte as referências do artigo original.
Tradução: Luan Marques
Link para o original