Índice
Evitando a destruição não construindo a máquina da destruição
Se você teme que alguém construa uma máquina que irá assumir o controle do mundo e aniquilar a humanidade, então um tipo de resposta é tentar construir outras máquinas que irão assumir o controle do mundo ainda mais cedo sem destruí-lo, evitando a conquista da máquina ruinosa. Um tipo alternativo ou complementar de resposta é tentar evitar que tais máquinas sejam construídas, pelo menos enquanto o grau de suas tendências apocalípticas for ambíguo.
A última abordagem me parece o tipo de coisa básica e óbvia digna de pelo menos uma consideração, e também a seu favor, se encaixa perfeitamente no gênero “coisas que não são tão difíceis de imaginar acontecendo no mundo real”. No entanto, minha impressão é que, para as pessoas preocupadas com o risco de extinção vindo da inteligência artificial, as estratégias sob o título “retardar ativamente o progresso da IA” foram historicamente descartadas e ignoradas (embora “não acelere ativamente o progresso da IA” seja popular).
A conversa perto de mim ao longo dos anos foi mais ou menos assim:
Algumas pessoas: A IA pode matar todo o mundo. Devemos projetar uma superIA divina de bondade perfeita para evitar isso.
Outros: Uau, isso parece extremamente ambicioso
Algumas pessoas: Sim, mas é muito importante e também somos extremamente inteligentes; então, sei lá, pode funcionar
[Trabalham nisso por uma década e meia]
Algumas pessoas: Ok, tá bem difícil, a gente desiste
Outros: Oh, hum, não deveríamos talvez tentar parar a construção dessa IA perigosa?
Algumas pessoas: Hum, isso envolveria coordenar várias pessoas – podemos ser arrogantes o suficiente para pensar que podemos construir uma máquina-deus que pode dominar o mundo e refazê-lo como um paraíso, mas isso daí já é delírio!
Isso parece um erro para mim. (E ultimamente, para um monte de outras pessoas).
Eu não tenho uma visão forte sobre se algo no espaço de “tentar retardar algumas pesquisas de IA” deve ser feito. Mas acho que a) o ingênuo palpite inicial deve ser um forte “provavelmente” e b) uma quantidade decente de pensamento deve acontecer antes de descartar tudo neste grande espaço de intervenções, ao passo que costumeiramente a resposta provisória parece ser “claro que não” e, em seguida, parece ser evitada uma reflexão mais aprofundada sobre o tópico. (Pelo menos na minha experiência – a comunidade de segurança de IA é grande e, para a maioria das coisas que digo aqui, provavelmente se têm experiências diferentes em diferentes partes dela).
Talvez minha opinião mais forte seja a de que não se deve aplicar padrões tão diferentes de ambição a essas diferentes classes de intervenção. Tipo: sim, parece haver dificuldades substanciais em retardar o progresso da IA com bons resultados. Mas, no alinhamento técnico, desafios montanhosos são enfrentados com entusiasmo por esforços montanhosos. E não é óbvio que a escala de dificuldade aqui seja muito maior do que a envolvida no projeto de versões aceitavelmente seguras de máquinas capazes de dominar o mundo antes que qualquer outra pessoa no mundo projete versões perigosas.
Tenho conversado sobre isso com as pessoas nos últimos meses e acumulado uma abundância de razões para não tentar retardar a IA, a maioria das quais eu gostaria de discutir pelo menos um pouco. Minha impressão é que discutir na vida real coincidiu com as pessoas se moverem em direção às minhas opiniões.
Esclarecimentos rápidos
Primeiro, para evitar mal-entendidos:
- Eu considero que “retardar a IA perigosa” inclui qualquer um de:
- Reduzir a velocidade com que o progresso da IA é feito em geral, p. ex., como ocorreria se o financiamento geral para IA diminuísse.
- Transferir os esforços de IA dos trabalhos que levam mais diretamente a resultados arriscados para outros trabalhos, p. ex., como poderia ocorrer se houvesse preocupação em larga escala com modelos de IA muito grandes, e as pessoas e o financiamento se transferissem para outros projetos.
- Interromper categorias de trabalho até que uma forte confiança em sua segurança seja possível, p. ex., como ocorreria se os pesquisadores de IA concordassem que certos sistemas apresentam riscos catastróficos e não deveriam ser desenvolvidos até que não os apresentassem mais (isso poderia significar um fim permanente para alguns sistemas, se eles fossem intrinsecamente inseguros).
- Acho que há uma atenção séria em algumas versões dessas coisas, geralmente com outros nomes. Vejo pessoas pensando em “progresso diferencial” (B. acima) e traçando estratégias sobre coordenação para retardar a IA em algum momento no futuro (p. ex., na “implementação”). E acho que se dá muita consideração a evitar acelerar ativamente o progresso da IA. O que estou dizendo que está faltando é a) considerar trabalhar ativamente para retardar a IA agora e b) partir diretamente para “retardar a IA”, em vez de fazer careta para isso e considerar apenas exemplos disso que aparecem sob outra conceituação (talvez este seja um diagnóstico injusto).
- A Segurança da IA é uma grande comunidade, e eu só tenho visto a janela de uma pessoa para ela, de modo que talvez as coisas sejam diferentes, p. ex., em Washington ou em conversas diferentes em Berkeley. Estou apenas dizendo que, no meu canto do mundo, o nível de desinteresse por isso tem sido notável e, a meu ver, errôneo.
Por que não retardar a IA? Por que não considerar isso?
Ok, então, se supusermos provisoriamente que ao menos vale a pena pensar neste tópico, o que pensamos? Retardar a IA é uma boa ideia? Há grandes razões para descartar a ideia?
Scott Alexander escreveu um post há pouco tempo propondo razões para não gostar da ideia, grosso modo:
- Quer perder uma corrida armamentista? Se a comunidade de segurança da IA tentar retardar as coisas, isso retardará desproporcionalmente o progresso nos EUA, e então as pessoas em outros lugares irão rápido e passarão a ser aquelas cuja competência determina se o mundo é destruído e cujos valores determinam o futuro, se houver. Da mesma forma, se o pessoal da segurança da IA criticar aqueles que contribuem para o progresso da IA, isso desencorajará principalmente as empresas de capacidades de IA mais amigáveis e cuidadosas, e as imprudentes chegarão lá primeiro.
- Poderíamos considerar a “coordenação” para evitar tais corridas mórbidas. Mas coordenar qualquer coisa com o mundo inteiro parece extremamente complicado. Por exemplo, alguns países são grandes e assustadores e é difícil conversar com eles.
- Fazer campanha por um progresso mais lento da IA é “desertar” contra o pessoal das capacidades de IA, que são bons amigos da comunidade de segurança da IA, e sua amizade é estrategicamente valiosa para garantir que a segurança seja levada a sério nos laboratórios de IA (além de linda em termos não instrumentais! Oi, amigos das capacidades de IA!).
Outras opiniões que ouvi, algumas das quais abordarei:
- Retardar o progresso da IA é inútil: apesar de todos os seus esforços, você provavelmente morrerá apenas alguns anos depois.
- A coordenação baseada em convencer as pessoas de que o risco da IA é um problema é absurdamente ambiciosa. É praticamente impossível convencer os professores de IA disso, muito menos qualquer fração real da humanidade, e você precisaria convencer um grande número de pessoas.
- O que vamos fazer, jamais construir IA poderosa e morrer quando a Terra for devorada pelo Sol?
- Na verdade, é melhor para a segurança se o progresso da IA se mover rapidamente. Isso pode ser porque, quanto mais rápido o trabalho de capacidades de IA acontecer, mais fluido será o progresso da IA, e isso é mais importante do que a duração do período. Ou acelerar o progresso agora pode forçar o progresso futuro a ser correspondentemente mais lento. Ou porque o trabalho de segurança é provavelmente melhor quando feito pouco antes de construir a IA relevantemente arriscada, caso em que a melhor estratégia pode ser chegar o mais perto possível da IA perigosa e, em seguida, parar e fazer o trabalho de segurança. Ou se o trabalho de segurança é muito inútil antes do tempo, talvez o atraso seja bom, mas há pouco a ganhar com isso.
- Rotas específicas para retardar a IA não valem a pena. Por exemplo, evitar trabalhar na pesquisa de capacidades de IA é ruim porque é tão útil para aprender no caminho para trabalhar no alinhamento. E o pessoal da segurança da IA que trabalha em capacidades de IA pode ser uma força para fazer escolhas mais seguras nessas empresas.
- A IA avançada ajudará o suficiente com outros riscos existenciais para representar uma redução líquida do risco existencial ao todo1.
- Os reguladores são ignorantes sobre a natureza da IA avançada (em parte porque ela não existe, de modo que todos são ignorantes sobre ela). Consequentemente, eles não serão capazes de regulá-la de forma eficaz e trazer os resultados desejados.
Minha impressão é que também há razões menos aprováveis, ou menos altruístas, ou mais bobas flutuando por aí para essa alocação de atenção. Algumas coisas que surgiram pelo menos uma vez ao falar com as pessoas sobre isso, ou que parecem estar acontecendo:
- A IA avançada pode trazer múltiplas maravilhas, p. ex., vidas longas de prosperidade inabalável. Chegar lá um pouco mais tarde é bom para a posteridade, mas para nossa própria geração pode significar morrer como nossos ancestrais morreram enquanto estamos à beira de uma eternidade utópica. Isso seria bastante decepcionante. Para uma pessoa que realmente acredita nesse futuro, pode ser tentador tentar o melhor cenário – a humanidade constrói uma IA forte e segura a tempo de salvar esta geração – em vez do cenário em que nossas próprias vidas são inevitavelmente perdidas.
- Às vezes, as pessoas que têm um apreço sincero pelo florescimento que a tecnologia proporcionou até agora podem achar doloroso estar superficialmente do lado do ludismo aqui.
- Descobrir como mentes funcionam bem o suficiente para criar novas mentes a partir da matemática é um projeto intelectual incrivelmente profundo e interessante, do qual parece certo participar. Pode ser difícil sentir intuitivamente que não se deve fazer isso.
(Ilustraçãode um cofundador da aprendizagem por reforço computacional moderna: )
- É desconfortável contemplar projetos que nos colocariam em conflito com outras pessoas. Defender uma IA mais lenta parece tentar impedir o projeto de outra pessoa, o que parece adversário e pode parecer que tem um ônus de prova maior do que apenas trabalhar em nosso próprio negócio.
- “Retarde a IGA” manda as mentes das pessoas para, p. ex., a sabotagem industrial ou o terrorismo, em vez de caminhos mais sem graça, como “fazer lobby para que laboratórios desenvolvam normas em comum para quando pausar a implementação de modelos”. É compreensível que isso estimule a abandonar o pensamento o mais rápido possível.
- Meu palpite fraco é que há um tipo de viés em ação no pensamento sobre o risco de IA em geral, no qual qualquer força que não seja zero é considerada arbitrariamente intensa. Tipo: se houver pressão para que agentes existam, haverá coisas arbitrariamente como agentes de forma arbitrariamente rápida. Se houver um ciclo de feedback, ele será arbitrariamente forte. Aqui, se paralisar a IA não pode ser para sempre, então é essencialmente por tempo zero. Se um regulamento não obstruir todos os projetos perigosos, então de nada vale. Qualquer desincentivo econômico finito para a IA perigosa não é nada diante dos incentivos econômicos onipotentes para a IA. Acho que isso é um mau hábito mental: as coisas no mundo real muitas vezes se resumem a quantidades finitas reais. Esse é, muito possivelmente, um diagnóstico injusto. (Não vou discutir isso mais tarde; isso é praticamente o que tenho a dizer).
- Sinto uma suposição de que retardar o progresso em uma tecnologia seria um movimento radical e inédito.
- Concordo com o lc que parece ter havido quase um tabu sobre o tema, o que talvez explique muito da falta de discussão, embora ele ainda exija sua própria explicação. Acho que isso sugere que as preocupações com a falta de cooperatividade desempenham um papel, e o mesmo para pensar que retardar a IA envolve centralmente estratégias antissociais.
Não tenho certeza se algo disso explica totalmente por que as pessoas da segurança da IA não pensaram em retardar mais a IA, ou se as pessoas deveriam tentar fazer isso. Mas minha intuição é que muitas das razões acima estão pelo menos um pouco erradas, e os motivos um tanto equivocados, de modo que quero discutir sobre muitos deles por sua vez, incluindo argumentos e temas motivacionais vagos.
A mundanidade da proposta
A contenção não é radical
Parece haver um pensamento comum de que a tecnologia é uma espécie de caminho inevitável ao longo do qual o mundo deve trilhar, e que tentar retardar ou evitar qualquer parte dela seria fútil e extremo2.
Mas, empiricamente, o mundo não busca todas as tecnologias – quase não busca nenhuma tecnologia.
Tecnologias capengas
Para começar, há muitas máquinas que não há pressão para fazer, porque não têm valor. Considere uma máquina que borrifa cocô nos olhos. Tecnologicamente, podemos fazer isso, mas provavelmente ninguém nunca construiu essa máquina.
Isso pode parecer um exemplo estúpido, porque nenhuma conjectura séria de “a tecnologia é inevitável” vai afirmar que tecnologias totalmente inúteis são inevitáveis. Mas se você é suficientemente pessimista com relação à IA, acho que essa é a comparação certa: se há tipos de IA que causariam enormes custos líquidos para seus criadores se criados, de acordo com nosso melhor entendimento, então eles são pelo menos tão inúteis de fazer quanto a máquina de “borrifar de cocô nos olhos”. Podemos fazê-las acidentalmente devido a erro, mas não há uma força econômica profunda nos incentivando a fazê-las. Se a superinteligência desalinhada destrói o mundo com alta probabilidade quando você pede para ela fazer uma coisa, então essa é a categoria em que ela está, e não é estranho que seus projetos simplesmente apodreçam no monte de sucata, com a máquina que borrifar cocô nos olhos e a máquina que espalha caviar na estrada.
Ok, mas talvez os atores relevantes estejam muito comprometidos em estar errados sobre que a superinteligência não alinhada seja uma ótima coisa para implementar. Ou talvez você pense que a situação é menos imediatamente terrível e que construir uma IA existencialmente arriscada realmente seria bom para as pessoas que tomam decisões (p. ex., porque os custos não chegarão por um tempo, e as pessoas se importam muito com uma chance de sucesso científico em comparação com uma parcela do futuro). Se os aparentes incentivos econômicos são grandes, as tecnologias são inevitáveis?
Tecnologias extremamente valiosas
Não me parece que sim. Aqui estão algumas tecnologias que eu acho que têm um valor econômico substancial, onde o progresso ou a captação da pesquisa parece ser drasticamente mais lento do que poderia ser, por razões de preocupação com a segurança ou a ética3.
- Enormes quantidades de pesquisas médicas, incluindo pesquisas médicas realmente importantes, por exemplo. A agência de saúde pública dos EUA proibiu os testes em humanos de vacinas contra os estreptococos A dos anos 70 aos anos 2000, apesar de 500.000 mortes globais a cada ano. Muitas pessoas também morreram enquanto as vacinas contra a Covid passavam por todos os testes adequados.
- Energia nuclear.
- Fraturamento Hidráulico (fracking).
- Várias coisas genéticas: modificação genética de alimentos, genética dirigida (gene drive), pesquisadores de DNA recombinante organizaram uma moratória e, em seguida, diretrizes de pesquisa em andamento, incluindo a proibição de certos experimentos (veja a Conferência de Asilomar).
- Armas nucleares, biológicas e talvez químicas (ou talvez estas simplesmente não sejam úteis).
- Várias inovações reprodutivas humanas: clonagem de seres humanos, manipulação genética de seres humanos (um exemplo notável de uma tecnologia economicamente valiosa que, tanto quanto sei, é pouco explorada em diferentes países, sem uma coordenação explícita entre esses países, embora isso os tornasse mais competitivos. Alguém usou CRISPR em bebês na China, mas foi preso por isso).
- Desenvolvimento de drogas recreativas.
- Geoengenharia.
- Muito da ciência sobre os seres humanos? Recentemente, realizei esta pesquisa e fui lembrada de como as regras éticas são pesadas até mesmo para pesquisas incrivelmente inócuas. Pelo que sei, a UE torna agora ilegal o recolhimento de dados na UE, a menos que se prometa apagar os dados de qualquer lugar a que possam ter chegado, se a pessoa que lhe forneceu os dados desejar isso em algum momento. Ao todo, lidar com isso e coisas relacionadas aos comitês de ética de pesquisa acrescentou talvez mais da metade do esforço do projeto. É plausivel que eu entenda mal as regras, mas duvido que outros pesquisadores sejam radicalmente melhores em entendê-las do que eu.
- Provavelmente há exemplos de campos que é considerado de mau gosto ou embaraçoso associar-se com eles, mas é difícil dizer observando de fora quais campos são genuinamente um caso perdido versus erroneamente considerados assim. Se houver intervenções de saúde economicamente valiosas entre aquelas consideradas obscurantistas, imagino que seria muito mais lento para cientistas com boa reputação identificá-las e buscá-las do que uma tecnologia igualmente promissora e não desconceituada dessa forma. A pesquisa científica sobre a inteligência é mais claramente desacelerada pelo estigma, mas é menos claro para mim qual o resultado economicamente valioso seria.
- (Acho que há muitas outras coisas que poderiam estar nesta lista, mas não tenho tempo para revisá-las no momento. Esta página pode coletar mais delas no futuro).
Parece-me ser comum retardar intencionalmente o progresso das tecnologias para dar tempo a cautelas até provavelmente excessivas. (E isso só olha para as coisas desaceleradas por cautela ou ética especificamente – provavelmente também há outras razões pelas quais as coisas são desaceleradas).
Além disso, entre tecnologias valiosas que ninguém está especialmente tentando retardar, parece comum o suficiente que o progresso seja enormemente desacelerado por obstáculos relativamente pequenos, o que é mais uma evidência de uma falta de força avassaladora das forças econômicas em jogo. Por exemplo, Fleming notou pela primeira vez o efeito do mofo sobre as bactérias em 1928, mas ninguém tentou a sério e com alto esforço desenvolvê-lo como uma droga até 19394. Além disso, nos milhares de anos que antecederam esses eventos, várias pessoas notaram inúmeras vezes que o mofo, outros fungos ou plantas inibiam o crescimento bacteriano, mas não exploraram essa observação sequer o bastante para que ela não fosse considerada uma nova descoberta na década de 1920. Enquanto isso, pessoas morrendo de infecção era uma coisa bastante real. Em 1930, cerca de 300.000 americanos morriam de doenças bacterianas por ano (cerca de 250/100.000).
Meu palpite é que as pessoas fazem escolhas reais sobre tecnologia, e as fazem diante de forças econômicas que são mais fracas do que se pensa comumente.
A contenção não é terrorismo, geralmente
Acho que as pessoas historicamente imaginam coisas estranhas quando pensam em “retardar a IA”. Minha hipótese é que sua imagem central às vezes é o terrorismo (em que compreensivelmente eles não querem pensar por muito tempo), e às vezes algum tipo de acordo global implausivelmente utópico.
Aqui estão algumas outras coisas com que “retardar as capacidades de IA” pode se parecer (sendo que a pessoa mais bem posicionada para realizar cada uma difere, mas se você não é essa pessoa, você pode, p. ex., falar com alguém que é):
- Não avance ativamente o progresso da IA, p. ex., dedicando sua vida ou milhões de dólares a ela (isso já é frequentemente considerado).
- Tente convencer persuisadores, financiadores, fabricantes de hardware, instituições, etc., que eles também deveriam parar de avançar ativamente o progresso da IA.
- Tente fazer com que qualquer uma dessas pessoas pare de avançar ativamente o progresso da IA, mesmo que não concorde com você: por meio de negociação, pagamento, repreensão pública ou outros meios ativistas.
- Tente passar a mensagem para o mundo de que a IA está caminhando para ser seriamente ameaçadora. Se o progresso da IA for amplamente condenado, isso escorrerá como uma miríade de decisões: escolhas de emprego, políticas de laboratório, leis nacionais. Para fazer isso, p. ex., produza demonstrações convincentes de risco, faça campanha para a estigmatização de ações arriscadas, escreva ficção científica ilustrando os problemas de forma ampla e sugestiva (acho que isso realmente foi útil repetidamente no passado), vá à TV, escreva editoriais, ajude a organizar e capacitar as pessoas que já estão preocupadas, etc.
- Ajude a organizar os pesquisadores que pensam que seu trabalho é potencialmente onicida numa ação coordenada de não fazê-lo.
- Mova recursos de IA de pesquisas perigosas para outras pesquisas. Mova investimentos de projetos que levam a capacidades grandes, porém pouco compreendidas, para projetos que levam à compreensão dessas coisas, p. ex., teoria antes da amplificação (veja desenvolvimento tecnológico diferencial em geral5).
- Formule precauções específicas para pesquisadores e laboratórios de IA tomarem em diferentes situações futuras bem definidas, ao estilo da Conferência de Asilomar. Isso pode incluir uma verificação mais intensa por partes ou métodos específicos, a modificação de experimentos ou a pausa total das linhas de investigação. Organize laboratórios para coordenar isso.
- Reduza a computação disponível para a IA, p. ex., por meio da regulamentação da produção e do comércio, das escolhas do vendedor, da compra de computação, da estratégia comercial.
- Nos laboratórios, escolha políticas que desacelerem outros laboratórios, p. ex., reduza os resultados de pesquisa úteis ao público.
- Altere o sistema de publicação e incentivos para reduzir a divulgação de pesquisas. Por exemplo, um periódico verifica os resultados da pesquisa e divulga o fato de sua publicação sem nenhum detalhe, mantém registros de prioridade de pesquisa para posterior divulgação e distribui financiamento para participação. (Foi assim que Szilárd e companhia organizaram a mitigação da pesquisa nuclear dos anos 1940 que ajudava a Alemanha, exceto que não tenho certeza se a ideia de financiamento compensatório foi usada6).
- As ações acima seriam realizadas por meio de escolhas feitas por cientistas, ou financiadores, ou legisladores, ou laboratórios, ou observadores públicos, etc. Comunique-se com essas partes ou ajude-as a agir.
A coordenação não é governo mundial milagroso, geralmente
A imagem comum da coordenação parece ser de algo explícito, centralizado, que envolve todas as partes do mundo e algo como cooperar em um dilema do prisioneiro: os incentivos empurram todas as partes racionais para a deserção a todo momento, mas talvez por meio de virtudes deontológicas, ou teorias de decisão sofisticadas, ou tratados internacionais fortes, todos conseguem não desertar por momentos oscilantes suficientes para encontrar outra solução.
Esse é um possível caminho de coordenação. (E é um caminho que acho que não deve ser visto como tão desesperador: o mundo realmente se coordenou em algumas coisas impressionantes, como, p. ex., a não proliferação nuclear). Mas se o que você quer é que muitas pessoas coincidam em fazer uma coisa quando poderiam ter feito outra, então há algumas maneiras de conseguir isso.
Considere alguns outros estudos de caso de comportamento coordenado:
- Não comer areia: o mundo inteiro se coordena para quase nunca comer areia. Como ele consegue? Na verdade, não é do interesse de quase ninguém comer areia, de modo que faz o trabalho a mera manutenção de uma saúde epistemológica suficiente para que isso seja amplamente reconhecido.
- Evitar a bestialidade: provavelmente algumas pessoas pensam que a bestialidade é moral, mas o suficiente delas não pensa assim, de modo que a sua prática arriscaria um enorme estigma. Assim, o mundo se coordena razoavelmente bem em praticar muito pouca bestialidade.
- Não usar trajes vitorianos nas ruas: isso é semelhante, mas sem nenhuma culpa moral envolvida. O vestuário histórico é muitas vezes mais estético do que o vestuário moderno, mas mesmo as pessoas que concordam fortemente com isso acham impensável usá-lo em geral, e assiduamente o evitam, exceto quando têm “desculpas” como uma festa especial. Essa é uma coordenação muito forte contra o que parece ser um incentivo onipresente (ser mais agradável aos olhos). Até onde eu sei, ela se deve substancialmente ao fato de que isso “não se faz” e agora seria estranho fazer o contrário (o que é um mecanismo de uso muito geral).
- O politicamente correto: o discurso público tem normas fortes sobre o que é permitido dizer, que não parecem derivar de uma grande maioria de pessoas concordando sobre isso (como, digamos, a bestialidade). Novas ideias sobre o que constitui ser politicamente correto às vezes se espalham amplamente. Esse comportamento coordenado parece ser aproximadamente devido à aplicação descentralizada da punição social, tanto de um núcleo de proponentes, quanto de pessoas que temem punição por não punir os outros. Depois, talvez também de pessoas que estão preocupadas com a falta de adesão ao que agora parece ser a norma, dadas as ações dos outros. Isso difere dos exemplos acima, porque parece que poderia persistir mesmo com um conjunto muito pequeno de pessoas concordando com as razões de nível de objeto para uma norma. Se deixar de defender a norma faz com que você seja publicamente constrangido pelos defensores, então você pode tender a defendê-la, tornando a pressão mais forte para todos os outros.
Todos esses são casos de coordenação de comportamento em larga escala, nenhum dos quais envolve situações do tipo dilema do prisioneiro, ou pessoas fazendo acordos explícitos que elas têm um incentivo para violar. Não envolvem a organização centralizada de grandes acordos multilaterais. O comportamento coordenado pode vir de todos individualmente quererem fazer uma determinada escolha por razões correlacionadas, ou de pessoas quererem fazer coisas que aqueles ao seu redor estão fazendo, ou de dinâmicas comportamentais distribuídas como punição de violações, ou da colaboração em pensar sobre um tópico.
Você pode pensar que são exemplos estranhos que não estão muito relacionados à IA. Acho que a) é importante lembrar a infinidade de dinâmicas estranhas que realmente surgem no comportamento de grupo humano e não se deixar levar pela teorização sobre IA em um mundo desprovido de tudo menos dilemas do prisioneiro e compromissos obrigatórios e b) as dinâmicas acima são realmente todas potencialmente relevantes aqui.
Se a IA de fato apresenta um grande risco existencial dentro de nossas vidas, de tal forma que é ruim para qualquer indivíduo em particular, então a situação em teoria se parece muito com isso no caso de “evitar comer areia”. É uma opção que uma pessoa racional não gostaria de escolher se estivesse sozinha e não enfrentasse nenhum tipo de situação multiagente. Se a IA é tão perigosa, então não escolher essa opção inferior pode vir em grande parte de um mecanismo de coordenação tão simples quanto a distribuição de boas informações. (Você ainda precisa lidar com pessoas irracionais e pessoas com valores incomuns.)
Mas, mesmo que falhe uma cautela coordenada vinda de um insight onipresente sobre a situação, outros modelos podem funcionar. Por exemplo, se viesse a existir uma preocupação um tanto generalizada de que a pesquisa de IA é ruim, isso poderia diminuir substancialmente a participação nela, além do conjunto de pessoas que estão preocupadas, por meio de mecanismos semelhantes aos descritos acima. Ou pode dar origem a uma ampla safra de regulamentação local, impondo qualquer comportamento que seja considerado aceitável. Essa regulamentação não precisa ser organizada centralmente em todo o mundo para servir ao propósito de coordenar o mundo, desde que tenha crescido em lugares diferentes de forma semelhante. Isso pode acontecer porque diferentes localidades têm interesses semelhantes (todos os governos racionais devem estar igualmente preocupados com a perda de poder para sistemas automatizados que buscam poder com objetivos não verificáveis), ou porque, como acontece com indivíduos, há dinâmicas sociais que sustentam normas que surgem de forma não centralizada.
O modelo da corrida armamentista e suas alternativas
Ok, talvez em princípio você espere se coordenar para não fazer coisas autodestrutivas, mas, de modo realista, se os EUA tentarem retardar as coisas, a China, ou o Facebook, ou alguém menos cauteloso não dominará o mundo?
Sejamos mais cuidadosos com o jogo que estamos jogando, falando em termos de teoria dos jogos.
A corrida armamentista
O que é uma corrida armamentista, em termos de teoria dos jogos? É um dilema do prisioneiro iterado, me parece. Cada rodada é mais ou menos assim:
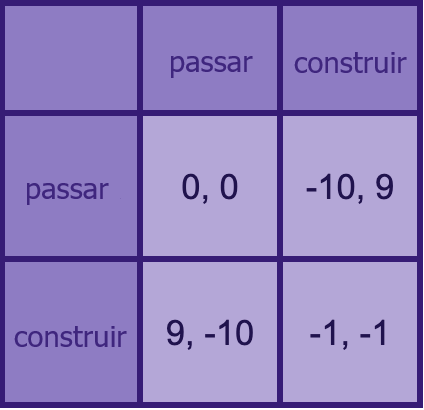
Neste exemplo, construir armas custa uma unidade. Se qualquer um terminar a rodada com mais armas do que qualquer outro, ele leva todas as coisas outro (dez unidades).
Em uma única rodada do jogo, é sempre melhor construir armas do que não construir (supondo que suas ações sejam desprovidas de implicações sobre as ações de seu oponente). E é sempre melhor dar o fora desse jogo.
Isso não é muito parecido com a situação atual da IA, se você acha que a IA apresenta um risco substancial de destruir o mundo.
A corrida suicida
Um modelo mais próximo: como acima, exceto que, se alguém decidir construir, tudo é destruído (todos perdem todas as suas coisas – dez unidades de valor -, bem como uma unidade caso tenham construído).
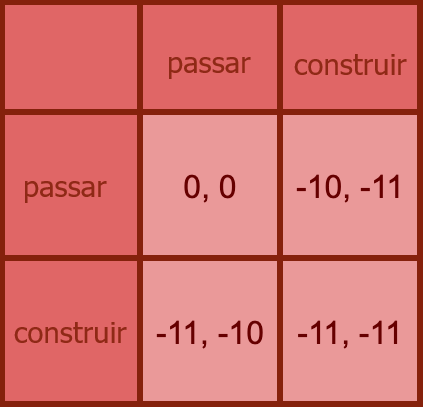
Isso é muito diferente da clássica “corrida armamentista”, pois pressionar o botão “todos perdem agora” não é uma estratégia de equilíbrio.
Ou seja: para quem acha que IA desalinhada poderosa representa morte quase certa, a existência de outros possíveis construtores de IA não é razão nenhuma para “correr”.
Mas poucas pessoas são tão pessimistas assim. Que tal uma versão mais branda, onde há uma boa chance de que os jogadores “alinhem a IA”?
A corrida da segurança ou suicídio
Ok, vamos fazer um jogo como o último, mas em que, se alguém construir, tudo é apenas talvez destruído (menos dez para todos), e no caso da sobrevivência, todos voltam à diversão da corrida armamentista original de redistribuir coisas com base em quem construiu mais do que quem (+10 para um construtor e -10 para um não construtor se houver um de cada). Então, se você construir IA sozinho, e tiver sorte no apocalipse probabilístico, ainda pode ganhar muito.
Vamos tomar 50% como a chance de ruína se alguma construção acontecer. Depois, temos um jogo cujos retornos esperados estão a meio caminho entre os dos últimos dois jogos:
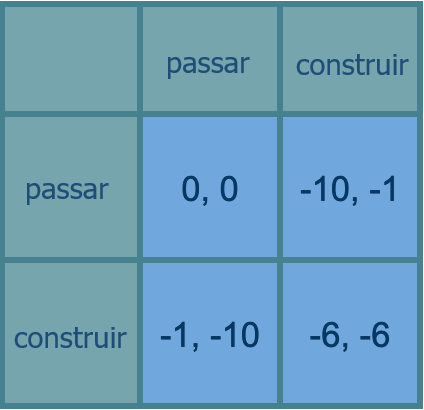
Agora você quer fazer o que o outro jogador está fazendo: construir se ele construir, passar se ele passar.
Se as chances de destruir o mundo fossem muito baixas, isso se tornaria a corrida armamentista original, e você sempre gostaria de construir. Se muito altas, se tornaria a corrida suicida, e você nunca iria querer construir. Quais devem ser as probabilidades no mundo real para levá-lo a algo como essas diferentes fases será diferente, porque todos esses parâmetros são inventados (a desvantagem da extinção humana não é 10x os custos de pesquisa da construção de IA poderosa, por exemplo).
Mas minha ideia continua de pé: mesmo em termos de modelos simplistas, fortemente não é óbvio que estejamos dentro ou perto de uma corrida armamentista. E, portanto, fortemente não é óbvio que correr para construir IA avançada mais rápido seja sequer promissor à primeira vista.
Menos em termos de teoria dos jogos: se você não parece nem perto de resolver o alinhamento, então correr o máximo que puder para ser aquele com a responsabilidade de resolver o alinhamento – especialmente se isso significa ter menos tempo para fazer isso, embora eu não tenha discutido isso aqui – provavelmente não é estratégico. Ter designers de IA mais ideologicamente pró-segurança vencendo uma “corrida armamentista” contra equipes menos preocupadas é inútil se você não tiver um modo para essas pessoas implementarem segurança suficiente para realmente não morrerem, o que parece uma possibilidade muito viva. (Robby Bensinger e talvez Andrew Critch em algum lugar defendem algo semelhante).
Conversas com meus amigos sobre esse tipo de tema podem acontecer assim:
Eu: Não há incentivo real para correr se o prêmio for a morte mútua
Eles: Claro, mas não é – se há uma lasca de esperança de sobreviver à IA desalinhada, e se seu lado assumir o controle nesse caso é um pouco melhor em expectativa, e se vão construir IA poderosa de qualquer maneira, então vale a pena correr. Todo o futuro está em jogo!
Eu: Você ainda não ficaria melhor direcionando seus próprios esforços para a segurança, já que seus esforços de segurança também ajudarão todos a ter uma IA segura?
Eles: Provavelmente só vai ajudá-los um pouco: você não sabe se o outro lado usará sua pesquisa de segurança. Mas também não é só que eles têm menos pesquisas de segurança. Os valores deles provavelmente são piores, do seu ponto de vista.
Eu: Se eles conseguirem alinhar, os valores estrangeiros são realmente piores do que os locais? Provavelmente qualquer ser humano com vasta inteligência em mãos tem uma chance semelhante de criar uma gloriosa utopia humanoide, não?
Eles: Não, mesmo que você esteja certa de que ser similarmente humano leva você a valores semelhantes no final, as outras partes podem ser mais tolas do que o nosso lado, e trancar7 alguma versão mal pensada de seus valores que eles querem no momento, ou mesmo se todos os projetos seriam tão tolos, nosso lado poderia ter melhores valores mal pensados para se trancar, além de ser mais propenso a usar ideias de segurança. Mesmo que seja muito provável que correr leve à morte, e que a sobrevivência leve ao desperdício da maior parte do valor, nessa minoria de mundos felizes há tanto em jogo em se somos nós ou outras pessoas que estão desperdiçando!
Eu: Hum, parece complicado, vou precisar de papel para isso.
A complicada corrida/anticorrida
Aqui está uma planilha de modelos de que você pode fazer uma cópia e com que pode jogar.
O primeiro modelo é assim:
- Cada jogador divide seu esforço entre segurança e capacidades.
- Um jogador “ganha”, ou seja, constrói “IGA” (inteligência geral artificial) primeiro.
- P(Alice ganha) é uma função logística do investimento em capacidades de Alice em relação ao de Bob.
- A segurança total de cada jogador é seu próprio investimento em segurança mais uma fração do investimento em segurança do outro.
- Para cada jogador, há alguma distribuição de resultados se alcançar a segurança e um conjunto de resultados se não alcançar, o que leva em conta, por exemplo, suas inclinações a decretar trancamentos estúpidos no curto prazo.
- O resultado é uma distribuição sobre vencedores e estados de alinhamento, cada um dos quais é uma distribuição de mundos (p. ex., utopia, bom trancamento no curto prazo).
- Isso tudo nos dá uma série de utils [NT: unidade econômica hipotética de satisfação]. (Deliciosos utils!)
O segundo modelo é o mesmo, exceto que, em vez de dividir o esforço entre segurança e capacidades, você escolhe uma velocidade, e a quantidade de alinhamento que está sendo feito por cada parte é um parâmetro exógeno.
Esses modelos provavelmente não são muito bons, mas até agora apoiam uma afirmação fundamental que quero fazer aqui: não é óbvio se se deve ir mais rápido ou mais devagar nesse tipo de cenário – é sensível a muitos parâmetros diferentes em gamas plausíveis.
Além disso, não acho que os resultados da análise quantitativa correspondam às intuições das pessoas aqui.
Por exemplo, aqui está uma situação que eu acho que soa intuitivamente como um mundo “em que se deve correr”, mas na qual, no primeiro modelo acima, você deve na realidade ir o mais devagar possível (este deve ser aquele plugado na planilha agora):
- A IA é bastante segura: a IGA não alinhada tem apenas 7% de chance de causar a ruína, além de mais 7% de chance de causar o trancamento no curto prazo de algo medíocre.
- Seu oponente arrisca um mau trancamento: se houver um “trancamento” de algo medíocre, seu oponente tem 5% de chance de trancar algo ativamente terrível, enquanto você sempre escolherá um bom mundo de trancamento medíocre (e trancamentos medíocres têm ou 5%, ou -5% do valor da utopia).
- Seu oponente corre o risco de arruinar a utopia: no caso de uma IGA alinhada, você alcançará de forma confiável o melhor resultado, enquanto seu oponente tem 5% de chance de acabar em um cenário “medíocre ruim” também.
- O investimento em segurança elimina sua chance de chegar à IGA primeiro: passar de nenhuma segurança para segurança total significa que você passa de uma chance de 50% de ser o primeiro para 0% de chance
- Seu oponente está correndo: seu oponente está investindo tudo em capacidades e nada em segurança
- O trabalho de segurança ajuda os outros com um desconto acentuado: seu trabalho de segurança contribui com 50% para a segurança do outro jogador
Sua melhor aposta aqui (neste modelo) ainda é maximizar o investimento em segurança. Por quê? Porque, ao buscar agressivamente a segurança, você pode levar o outro lado a meio caminho para a segurança total, o que vale muito mais do que a chance perdida de ganhar. Especialmente porque se você “ganhar”, será sem muita segurança, e sua vitória sem segurança é pior do que a vitória do seu oponente com segurança, mesmo que isso também esteja longe da perfeição.
Então, se você está em uma situação neste espaço e a outra parte está correndo, não é óbvio se é mesmo de seu interesse restrito dentro do jogo ir mais rápido às custas da segurança, embora possa ser.
Esses modelos são falhos em muitos aspectos, mas acho que são melhores do que os modelos intuitivos que apoiam corridas de armamentistas. Meu palpite é que os próximos modelos ainda melhores permanecem com nuances.
Outros equilíbrios e outros jogos
Mesmo que fosse do seu interesse correr se a outra pessoa estivesse correndo, “(fazer nada, fazer nada)” é muitas vezes um equilíbrio também nesses jogos. Pelo menos para várias configurações dos parâmetros. Não faz necessariamente sentido fazer nada na esperança de chegar a esse equilíbrio se você sabe que seu oponente está enganado sobre isso e está correndo de qualquer maneira, mas em conjunto com a comunicação com seu “oponente”, parece uma estratégia teoricamente boa.
Isso tudo tem presumido a estrutura do jogo. Acho que a resposta tradicional a uma situação de corrida armamentista é lembrar que você está em um mundo mais elaborado, com todos os tipos de recursos não modelados, e tentar sair da corrida armamentista.
Ser amigo de quem se arrisca
A cautela é cooperativa
Outra grande preocupação é que fazer pressão para um progresso mais lento da IA é “desertar” contra pesquisadores de IA que são amigos da comunidade de segurança da IA.
Por exemplo, diz Steven Byrnes:
“Acho que tentar retardar a pesquisa para a IGA por meio de regulamentação seria um fracasso, porque todos (políticos, eleitores, lobistas, empresários, etc.) gostam de pesquisa científica e desenvolvimento tecnológico, gera empregos, cura doenças, etc., e você está dizendo que deveríamos ter menos disso. Então, acho que o esforço falharia e também seria extremamente contraproducente, fazendo com que a comunidade de pesquisadores de IA visse a comunidade de segurança/alinhamento da IGA como seus inimigos, idiotas, esquisitos, luditas, o que quer que seja”.
(Também é um bom exemplo da visão criticada anteriormente, de que a regulamentação de coisas que criam empregos e curam doenças simplesmente não acontece).
Ou Eliezer Yudkowsky, sobre a preocupação de que espalhar o medo sobre a IA alienaria os principais laboratórios de IA:
Não acho que essa seja uma maneira natural ou razoável de ver as coisas, porque:
- Os próprios pesquisadores provavelmente não querem destruir o mundo. Muitos deles também concordam que a IA é um sério risco existencial. Então, de duas maneiras naturais, fazer pressão pela cautela é cooperativo com muitos, se não a maioria, dos pesquisadores de IA.
- Os pesquisadores de IA não têm um direito moral de colocar o mundo em risco, em que alguém estaria pisando ao exigir que eles se movam com mais cautela. Tipo, por que a “cooperação” se parece com o pessoal da segurança se curvar ao que o pessoal mais imprudente das capacidades querem, a ponto de temer representar seus interesses reais, enquanto o pessoal das capacidades defendem seu lado da “cooperação” indo em frente e construindo uma IA perigosa? Essa situação pode fazer sentido como uma consequência natural do poder de diferentes pessoas na situação. Mas então não chame isso de uma “cooperação”, da qual as partes orientadas à segurança estariam “desertando” desonrosamente se considerassem exercer qualquer poder que tivessem.
Pode ser que as pessoas no controle das capacidades de IA respondam negativamente se as pessoas da segurança da IA fizerem pressão para um progresso mais lento. Mas isso deveria ser chamado de “podemos ser punidos” e não de “não devemos desertar”. “Deserção” tem conotações morais indevidas. Chamar o fato de um dos lados fazer pressão por seu resultado preferido de “deserção” o desautoriza injustamente, colocando erroneamente a moralidade do senso comum contra ele.
Pelo menos se for o lado da segurança. Se alguma das ações disponíveis é uma “deserção” que o mundo em geral deveria condenar, eu afirmo que provavelmente essa ação é “construir máquinas que plausivelmente destruirão o mundo, ou ficar olhando enquanto isso acontece”.
(Isso seria mais complicado se as pessoas envolvidas estivessem confiantes de que não destruiriam o mundo e eu simplesmente discordasse delas. Mas cerca de metade dos pesquisadores pesquisados são realmente mais pessimistas do que eu. E em uma situação em que o pesquisador de IA mediano acha que o campo tem 5-10% de chance de causar a extinção humana, quão confiante alguma pessoa responsável pode estar em seu próprio julgamento de que é seguro?)
Ainda por cima de tudo isso, me preocupa que seja ainda mais destrutivo salientar a narrativa de que querer um progresso mais cauteloso é deserção, porque torna mais provável que o pessoal das capacidades de IA vejam o pessoal da segurança da IA como pensando em si mesmo como traindo os pesquisadores de IA, caso alguém se envolva em tais esforços, o que torna os esforços mais agressivos. Tipo, se toda vez que você vai ver os amigos, você se refere a isso como “trair meu companheiro”, seu companheiro pode razoavelmente se sentir magoado por seu desejo contínuo de ver os amigos, mesmo que a atividade em si seja inócua.
“Nós” não somos os EUA, “nós” não somos a comunidade de segurança da IA
“Se ‘nós’ tentarmos retardar a IA, o outro lado pode ganhar.” “Se ‘nós’ pedirmos regulamentação, isso pode prejudicar ‘nossos’ relacionamentos com empresas de capacidades de IA.” Quem são esses “nós”? Por que as pessoas estão traçando estratégias para esses grupos em particular?
Ainda que a desaceleração da IA não fosse cooperativa, e fosse importante para a comunidade de Segurança da IA cooperar com a comunidade de capacidades de IA, uma das muitas pessoas que não fazem parte da comunidade de Segurança da IA não poderia trabalhar nisso?
Tenho uma irritação de longa data com conversas impensadas sobre o que “nós” devemos fazer, sem levar em conta por qual coletivo a pessoa está falando. Portanto, posso ser sensível demais com relação a isso aqui. Mas acho que as confusões decorrentes disso têm consequências genuínas.
Acho que quando as pessoas dizem “nós” aqui, geralmente imaginam que estão criando estratégias em nome a) da comunidade de segurança da IA, b) dos EUA, c) deles mesmos ou d) deles mesmos e seus leitores. Mas esses são um pequeno subconjunto de pessoas, e nem mesmo obviamente das que o falante pode mais influenciar (o fato de você estar nos EUA realmente torna os EUA mais propensos a ouvir seus conselhos do que, por exemplo, a Estônia? Sim, provavelmente na média, mas não infinitamente). Se esses grupos com os quais o falante se identifica naturalmente não têm boas opções, isso dificilmente significa que não há outras opções para ele ou para serem comunicadas a outras partes. O falante poderia falar com um “nós” diferente? Talvez alguém no “nós” que o falante tem em mente conheça alguém que não esteja nesse grupo? Se há uma estratégia para alguma pessoa no mundo, e vocês podem conversar, então provavelmente há uma estratégia para você.
A aparição mais gritante de erros como esse para mim está em descartar a desaceleração da IA como inerentemente destrutiva para as relações entre a comunidade de segurança da IA e outros pesquisadores de IA. Se admitirmos que tal atividade seria vista como uma traição (o que me parece irrazoável, mas talvez seja), certamente só poderia ser uma traição se realizada pela comunidade de segurança da IA. Há muitas pessoas que não estão na comunidade de segurança da IA e têm interesse nisso; então talvez algumas delas possam fazer algo. Parece um grande descuido desistir de toda a desaceleração do progresso da IA porque você só está considerando os recursos disponíveis para a Comunidade de Segurança da IA.
Outro exemplo: se o mundo estivesse na situação básica de corrida armamentista às vezes imaginada, e os Estados Unidos estariam dispostos a fazer leis para mitigar o risco da IA, mas não poderiam porque a China avançaria, isso significa que a China está em um ótimo lugar para mitigar o risco de IA. Ao contrário dos EUA, a China poderia propor uma desaceleração mútua, e os EUA acompanhariam. Talvez não seja impossível comunicar isso a pessoas relevantes na China.
Uma estranheza desse tipo de discussão que parece relacionada é a suposição persistente de que a capacidade de agir de alguém é restrita aos Estados Unidos. Talvez eu não consiga entender até que ponto a Ásia é uma terra alienígena e distante onde a agência não se aplica, mas, por exemplo, eu escrevi para mil pesquisadores de aprendizado de máquina de lá, e talvez cem escreveram de volta, e foi muito parecido com interagir com pessoas nos EUA.
Eu sou bastante ignorante sobre quais intervenções funcionarão em qualquer país em particular, incluindo os EUA, mas eu simplesmente acho estranho vir à mesa supondo que você pode essencialmente afetar as coisas em um país só, especialmente se a situação é que você acredita que tem um conhecimento único sobre o que é do interesse das pessoas em outros países. Tipo, é verdade que eu seria uma pessimista incorrigível se você quisesse que um governo asiático elegesse você como líder ou algo assim. Mas se você acha que a IA avançada tem grande probabilidade de destruir o mundo, incluindo outros países, então a situação é totalmente diferente. Se você estiver certo, então os incentivos de todos estão basicamente alinhados.
Suspeito mais fracamente que algum atalho mental relacionado esteja distorcendo a discussão sobre corridas armamentistas em geral. O pensamento de que algo é uma “corrida” parece muito mais grudento do que alternativas, mesmo que os verdadeiros incentivos não tornem a situação realmente uma corrida. Tipo, contra as leis da teoria dos jogos, as pessoas meio que esperam que o inimigo tente acreditar em falsidades, porque isso contribuirá melhor para que ele corra. E isso parece realismo. Os detalhes incertos de bilhões de pessoas que mal conhecemos, com todos os tipos de interesses e relacionamentos, simplesmente querem realmente se formar em um “nós” e um “eles” em batalha de soma zero. Esse é um atalho mental que pode realmente nos matar.
Minha impressão é que, na prática, para muitas das tecnologias desaceleradas por risco ou ética, mencionadas na seção “Tecnologias extremamente valiosas” acima, países com culturas bastante díspares convergiram para abordagens semelhantes de cautela. Considero isso como evidência de que nenhum pensamento ético, influência social, poder político ou racionalidade é realmente muito isolado em termos de país, e , em geral, o modelo de “países em disputa” de tudo não é muito bom.
Notas sobre tratabilidade
Convencer as pessoas não parece tão difícil
Quando digo que a “coordenação” pode se parecer apenas como a opinião popular punindo uma atividade, ou que outros países não têm muito incentivo real para construir máquinas que os matarão, acho que uma objeção comum é que não há esperança de convencer as pessoas da situação real. A imagem parece ser que o argumento a favor do risco da IA é extremamente sofisticado e só pode ser apreciado pela elite das elites intelectuais: p. ex., é difícil convencer os professores no Twitter, de modo que certamente as massas estão além de seu alcance, e os governos estrangeiros também.
Isso não condiz com a minha experiência geral em várias frentes.
Algumas observações:
- O pesquisador de aprendizado de máquina mediano parece acreditar que a IA destruirá a humanidade com 5-10% de chance, como mencionei.
- Muitas vezes as pessoas já estão intelectualmente convencidas, mas não integraram isso em seu comportamento, e não é difícil ajudá-las a se organizar para agir de acordo com suas crenças provisórias.
- Como observado por Scott, muitas pessoas da segurança da IA entraram na àrea das capacidades de IA, inclusive na direção de organizações de capacidades de IA, de modo que essas pessoas presumivelmente já consideram a IA arriscada.
- Não me lembro de ter tido problemas em discutir o risco da IA com estranhos aleatórios. Às vezes, eles também estão bastante preocupados (p. ex., uma maquiadora da Sephora deu um longo desabafo sobre os perigos da IA avançada, e meu motorista em Santiago concordou animadamente e me mostrou o Homo Deus aberto em seu banco da frente). A forma das preocupações são provavelmente um pouco diferentes das da comunidade de segurança da IA, mas acho que estão amplamente mais perto de “agentes de IA vão matar a todos nós” do que de “o viés algorítmico será ruim”. Não lembro quantas vezes já tentei isso, mas antes da pandemia eu conversava muito com os motoristas da Uber, por não fazer ideia de como evitar. Expliquei o risco da IA ao meu terapeuta recentemente, como um aparte em relação à sensação dele de que eu poderia estar catastrofizando, e sinto que deu tudo certo, embora possamos precisar discutir novamente.
- Minha impressão é que a maioria das pessoas nem sequer entrou em contato com os argumentos que podem levar alguém a concordar exatamente com a comunidade de segurança da IA. Por exemplo, meu palpite é que muitas pessoas supõem que alguém realmente programou sistemas de IA modernos, e se você lhes disser que, na verdade, são conexões aleatórias agitadas numa direção prestativa um número insondável de vezes, igualmente misteriosas para seus criadores, elas também podem temer o desalinhamento.
- Nick Bostrom, Eliezer Yudkokwsy e outros pensadores iniciais tiveram um sucesso decente em convencer um monte de outras pessoas a se preocuparem com esse problema, como, p. ex., a mim. E que eu saiba, isso foi sem escrever nenhuma explicação convincente e acessível de por que alguém deveria que levasse menos de duas horas para ler.
- Eu, arrogantemente, acho que poderia escrever uma defesa amplamente convincente e acessível do risco da IA
Meu palpite fraco é que os céticos do risco da IA estão concentrados em círculos intelectuais perto do pessoal do risco da IA, especialmente no Twitter, e que as pessoas menos interessadas na corrida pelo status intelectual estão mais prontas para reagir tipo “Ah, sim, robôs superinteligentes provavelmente são ruins”. Não está claro se a maioria das pessoas sequer precisam ser convencidas de que há um problema, embora não pareçam considerá-lo o problema mais urgente do mundo. (Embora tudo isso possa ser diferente em culturas das quais estou mais distante, como, p. ex., na China). Não estou muito confiante sobre isso, mas as evidências de pesquisas sugerem que há uma preocupação pública substancial, embora não esmagadora, sobre a IA nos EUA8.
Precisa convencer todo mundo?
Eu poderia estar errada, mas acho que convencer os dez líderes mais relevantes dos laboratórios de IA de que isso é muito grande coisa, que vale a pena priorizar, na verdade nos dá uma desaceleração decente. Não tenho muitas evidências disso.
Ganhar tempo é uma grande coisa
Provavelmente não vamos evitar a IGA para sempre, e talvez enormes esforços vão nos dar alguns anos9. Será que isso pode valer a pena?
Parece bastante plausível:
- Qualquer outro tipo de pesquisa de segurança da IA ou trabalho político que pessoas estivessem fazendo poderia estar acontecendo a uma taxa não desprezível por ano. (Junto com todos os outros esforços para melhorar a situação – se você conseguir um ano, são oito bilhões de anos-pessoa a mais, de modo que apenas um pouquinho precisa ser gasto de forma útil para que isso seja uma grande coisa. Se um monte de gente está preocupada, isso não parece loucura).
- A geopolítica muda com bastante frequência. Se você pensa seriamente que um grande determinante de quão mal as coisas vão é a incapacidade de se coordenar com certos grupos, então a cada ano você tem oportunidades não desprezíveis para que a situação mude de maneira favorável.
- A opinião pública pode mudar muito rápido. Se você só pode conseguir um ano, você ainda pode estar conseguindo uma chance decente de as pessoas concordarem com você e lhe conceder mais anos. Talvez especialmente se novas evidências estiverem ativamente se acumulando – as pessoas mudaram ideia bastante em fevereiro de 2020.
- Outras coisas acontecem ao longo do tempo. Se você pode tomar a sua ruína hoje ou depois de alguns anos de eventos aleatórios acontecendo, a última opção parece não desprezivelmente melhor em geral.
Também não é óbvio para mim que essas sejam as escalas de tempo sobre a mesa. Minha intuição é que coisas que são desaceleradas pela regulamentação ou pelo desgosto social geral muitas vezes são desaceleradas por muito mais do que um ou dois anos, e as histórias do Eliezer presumem que o mundo esteja cheio de coletivos ou bem tentando destruir o mundo, ou então muito equivocados sobre ele, o que não é uma conclusão óbvia.
O atraso provavelmente é finito por padrão
Enquanto algumas pessoas temem que qualquer atraso seja tão curto a ponto de ser desprezível, outras parecem temer que, se a pesquisa de IA fosse interrompida, ela nunca recomeçaria e não iríamos para o espaço ou algo assim. Isso me parece tão extravagante que acho que estou perdendo de vista muito do raciocínio para contra-argumentar.
A obstrução não necessita discernimento
Outro suposto risco de tentar retardar as coisas é que isso pode envolver reguladores, e eles podem ser bastante ignorantes sobre os detalhes da IA futurista, e assim fazer de forma tenaz as regulamentações erradas. Algo relacionado é que, se apelarmos ao público para se preocupar com isso, ele pode ter preocupações não rigorosas que exigem soluções impotentes e distraem do desastre real.
Não estou convencida. Se tudo o que você quer é retardar uma ampla área de atividade, meu palpite é que regulamentos ignorantes se saem muito bem nisso todos os dias (geralmente sem querer). Em particular, minha impressão é que, se você errar ao regulamentar as coisas, um resultado comum é que muitas coisas são aleatoriamente mais lentas do que o esperado. Se você quisesse acelerar uma coisa específica, isso é uma história muito diferente, e pode exigir a compreensão da coisa em questão.
O mesmo vale para a oposição social. Ninguém precisa entender os detalhes de como funciona a engenharia genética para que sua ascendência seja seriamente prejudicada por pessoas que não gostam dela. Talvez na opinião delas ela ainda não esteja idealmente prejudicada, mas ajuda muito simplesmente não gostar de nada nas proximidades.
Isso não tem nada a ver com regulamentação ou constrangimento social especificamente. Você precisa entender muito menos sobre um carro, ou um país, ou uma conversa, para arruinar do que para fazer funcionar bem. É uma consequência da regra geral que há muito mais maneiras de uma coisa ser disfuncional do que funcional: a destruição é mais fácil do que a criação.
De volta ao nível de objeto, minha expectativa provisória é que esforços para retardar amplamente as coisas nas proximidades do progresso da IA retardem o progresso da IA no cômputo geral, mesmo que mal direcionados.
Segurança a partir da velocidade, influência a partir da cumplicidade
Talvez, na realidade, seja melhor para a segurança que a IA vá rápido no momento, por vários motivos. Principalmente:
- Implementar o que pode ser implementado o mais rápido possível provavelmente significa um progresso mais fluido, o que provavelmente é mais seguro porque a) torna mais difícil para uma parte disparar à frente de todos e ganhar poder e b) as pessoas fazem escolhas melhores em todos os sentidos se estiverem corretas sobre o que está acontecendo (p. ex., não confiam em sistemas que acabam sendo muito mais poderosos do que o esperado).
- Se a principal coisa alcançada ao retardar o progresso da IA é mais tempo para a pesquisa de segurança, e a pesquisa de segurança é mais eficaz quando realizada no contexto da IA mais avançada, e há uma certa quantidade de desaceleração que pode ser feita (p. ex., porque você está de fato em uma corrida armamentista, mas tem alguma vantagem sobre os concorrentes), então talvez seja melhor usar o orçamento de lentidão mais tarde.
- Se houver alguma curva subjacente de potencial de progresso (p. ex., se o dinheiro que pode ser gasto em hardware crescer a uma certa quantia a cada ano), então talvez se avançarmos agora isso naturalmente exija que eles sejam mais lentos mais tarde, de modo que isso não afetará o tempo total até a IA poderosa, mas significará que passaremos mais tempo na era informativa pré-IA catastrófica.
- (Mais coisas vão aqui, eu acho)
E talvez valha a pena trabalhar em pesquisa de capacidades no momento, por exemplo, porque:
- Como pesquisador, trabalhar em capacidades prepara você para trabalhar em segurança
- Você acha que estar na sala onde a IA acontece oferecerá boas opções para uma pessoa que se preocupa com a segurança
Tudo isso parece plausível. Mas também plausivelmente errado. Não sei de uma análise decisiva de nenhuma dessas considerações, e não vou fazer uma aqui. Minha impressão é que elas poderiam basicamente ir todas para qualquer lado.
Na verdade, duvido particularmente do argumento final, porque se você acredita no que eu considero ser o argumento normal para o risco da IA – que agentes artificiais sobre-humanos não terão valores aceitáveis e manifestarão agressivamente quaisquer valores que tenham, levando à aniquilação da humanidade mais cedo ou mais tarde –, então os sentimentos das pessoas que ligam essas máquinas parecem um fator muito pequeno, desde que ainda liguem as máquinas. E suspeito que “ter uma pessoa com meus valores fazendo X” é algo comumente superestimado. Mas o mundo é mais complicado que esses modelos, e eu ainda pagaria muito para estar na sala para tentar.
Humores e filosofias, heurísticas e atitudes
Não está claro qual papel esses personagens psicológicos devem desempenhar em uma avaliação racional de como agir, mas acho que eles desempenham um papel; então quero discutir sobre eles.
Escolha tecnológica não é ludismo
Algumas tecnologias são melhores que outras [não carece de fontes]. As melhores visões pró-tecnologia devem envolver desproporcionalmente tecnologias incríveis e evitar tecnologias de merda, eu afirmo. Se você acha que a IGA tem grande probabilidade de destruir o mundo, então ela é o ápice da merda enquanto tecnologia. Opor-se a tê-la em sua tecnoutopia é tão ludita quanto recusar-se a ter pasta de dente radioativa lá. Coloquialmente, luditas são contra o progresso se ele vier como tecnologia10. Mesmo que essa seja uma posição terrível, a inversão sábia dela não é o endosso de toda “tecnologia”, independentemente de se ela virá como progresso.
Visões de prosperidade a curto prazo sem a IGA
Talvez retardar o progresso da IA signifique abrir mão da esperança de nossa própria geração por tecnologias que mudam vidas. Algumas pessoas, portanto, acham psicologicamente difícil almejar um menor progresso de IA (com seus custos pessoais reais), em vez de mirar no cenário talvez improvável de “IGA segura em breve”.
Não tenho certeza de que esse seja um dilema real. O progresso restrito da IA que já vimos – ou seja, novas aplicações de técnicas atuais nas escalas atuais – parece plausivelmente capaz de ajudar muito com a longevidade e outras medicinas, por exemplo. E na medida em que os esforços de IA poderiam ser focados em, por exemplo, sistemas restritos medicamente relevantes em vez de criar deuses-agentes maquinadores, não parece loucura imaginar fazer mais progresso no antienvelhecimento, etc., como resultado (mesmo antes de levar em conta a probabilidade de que o deus-agente maquinador não priorizará seu bem-estar físico como esperado). Outros discordam de mim aqui.
Probabilidades a priori resilientes versus modelos pseudoprofundos específicos
Há coisas que são resilientemente boas no mundo, e coisas que são boas em modelos de visão interna altamente específicos e terríveis se esses modelos estiverem errados. Retardar o desenvolvimento tecnológico perigoso parece ser o primeiro, enquanto avançar corridas armamentistas por uma tecnologia perigosa entre superpotências mundiais é mais parecido com o segundo11. Há uma questão geral sobre quanto confiar em seu raciocínio e arriscar o plano pseudoprofundo12. Mas, seja qual for a sua opinião sobre isso, acho que todos devemos concordar que quanto menos pensamento você tiver colocado nele, mais você deve regredir para as ações resilientemente boas. Tipo, se acabou de lhe ocorrer pegar um grande empréstimo para comprar um carro metido a besta, você provavelmente não deveria fazer isso porque na maioria das vezes é uma má escolha; ao passo que, se você está pensando sobre isso há um mês, você pode ter certeza o suficiente de que você está na rara situação em que vai valer a pena.
Neste tópico em particular, parece que as pessoas estão indo logo de cara com o modelo pseudoprofundo específico terrível se errado de visão interna, e então não refletindo mais.
Mentalidade de cheems/atitude do não posso
Suponha que você tenha um amigo e lhe diga “Vamos à praia”. Às vezes, a resposta do amigo é “Vambora!” e então, mesmo que não tenham toalhas ou um meio de transporte, tempo ou praia, vocês fazem acontecer. Outras vezes, mesmo que você tenha todas essas coisas, e seu amigo diga que quer ir à praia, ele observa que está esperando uma entrega, e que pode estar ventando, e que precisa lavar sua jaqueta. E quando você resolve esses problemas, ele observa que não vai demorar muito até a hora do jantar. Você pode inferir que, neste último caso, seu amigo simplesmente não quer ir à praia. E às vezes essa é a principal coisa acontecendo! Mas acho que também há diferenças mais amplas de atitudes: às vezes as pessoas estão procurando maneiras de fazer as coisas acontecerem e às vezes estão procurando razões pelas quais elas não podem acontecer. Esta às vezes é chamada de “atitude de cheems“, ou como eu gosto de chamá-la (mais acessivelmente), “atitude do não posso”.
Minha experiência em falar sobre retardar a IA com as pessoas é que elas parecem ter uma atitude do não posso. Elas não querem que seja um caminho razoável: eles querem descartá-lo.
Isso parece subótimo, e é estranho em contraste com as atitudes históricas à resolução de problemas mais técnica. (Conforme destacado no meu diálogo no início do post).
Parece-me que se o mesmo grau de atitude do não posso fosse aplicado à segurança técnica, não haveria comunidade de segurança da IA, porque em 2005 o Eliezer teria notado qualquer obstáculo ao alinhamento e desistido e ido para casa.
Citando um amigo sobre isso, como seria se nós *realmente tentássemos*?
Conclusão
Isso foi uma miscelânea de críticas contra uma pilha de razões que encontrei para não pensar em retardar o progresso da IA. Acho que não vimos muita razão aqui para sermos muito pessimistas em relação à desaceleração da IA, muito menos razão para nem pensar nisso.
Eu poderia ter qualquer conclusão sobre se uma intervenção qualquer para retardar a IA no curto prazo é uma boa ideia. Meu palpite é que sim, mas minha ideia principal aqui é apenas que devemos pensar sobre isso.
Muitas opiniões sobre este assunto me parecem mal pensadas e erradas e que elas repeliram erroneamente o pensamento a mais que poderia corrigi-las. Espero ter ajudado um pouco aqui, examinando algumas dessas considerações o suficiente para demonstrar que não há bons motivos para a rejeição imediata. Há dificuldades e perguntas, mas se os mesmos padrões de ambição fossem aplicados aqui como em outros lugares, acho que veríamos respostas e ações.
Agradecimentos
Agradeço a Adam Scholl, Matthijs Maas, Joe Carlsmith, Ben Weinstein-Raun, Ronny Fernandez, Aysja Johnson, Jaan Tallinn, Rick Korzekwa, Owain Evans, Andrew Critch, Michael Vassar, Jessica Taylor, Rohin Shah, Jeffrey Heninger, Zach Stein-Perlman, Anthony Aguirre, Matthew Barnett, David Krueger, Harlan Stewart, Rafe Kennedy, Nick Beckstead, Leopold Aschenbrenner, Michaël Trazzi, Oliver Habryka, Shahar Avin, Luke Muehlhauser, Michael Nielsen, Nathan Young e muitos outros pela discussão e/ou incentivo.
Notas de rodapé
1. Eu não ouvi isso recentemente, de modo que talvez as opiniões tenham mudado. Um exemplo de tempos anteriores: Nick Beckstead, 2015: “Uma ideia que às vezes ouvimos é que seria prejudicial acelerar o desenvolvimento da inteligência artificial porque não foi feito trabalho suficiente para garantir que, quando a inteligência artificial muito avançada for criada, ela seja segura. Esse problema, argumenta-se, seria ainda pior se o progresso no campo se acelerasse. No entanto, a inteligência artificial muito avançada pode ser uma ferramenta útil para superar outros potenciais riscos catastróficos globais. Se vier mais cedo – e o mundo conseguir evitar os riscos que ela apresenta diretamente –, o mundo passará menos tempo em risco por esses outros fatores. (…)
Descobri que acelerar a inteligência artificial avançada – de acordo com minha interpretação simples dos resultados da pesquisa – poderia facilmente resultar na redução da exposição líquida aos riscos catastróficos globais mais extremos. (…)”
2. Isso está intimamente relacionado com a conjectura da finalização tecnológica de Bostrom: “Se os esforços de desenvolvimento científico e tecnológico não cessarem efetivamente, todas as capacidades básicas importantes que poderiam ser obtidas por meio de alguma tecnologia possível serão obtidas”. (Bostrom, Superintelligence, pp. 228, capítulo 14, 2014)
Bostrom ilustra esse tipo de posição (embora aparentemente a rejeite; de Superintelligence, encontrado aqui): “Suponha que um formulador de políticas proponha cortar o financiamento para um determinado campo de pesquisa, por preocupação com os riscos ou consequências de longo prazo de alguma tecnologia hipotética que possa acabar crescendo de seu solo. Ele pode então esperar um uivo de oposição da comunidade de pesquisa. Os cientistas e seus defensores públicos costumam dizer que é inútil tentar controlar a evolução da tecnologia bloqueando a pesquisa. Se alguma tecnologia for viável (diz o argumento), ela será desenvolvida independentemente dos escrúpulos de qualquer formulador de políticas em particular sobre riscos futuros especulativos. De fato, quanto mais poderosas forem as capacidades que uma linha de desenvolvimento promete produzir, mais seguros podemos estar de que alguém, em algum lugar, será motivado a buscá-la. Os cortes de financiamento não impedirão o progresso nem evitarão seus perigos concomitantes.”
Esse tipo de coisa também é discutido por Dafoe Sundaram, Maas e Barba.
3. (Alguma inspiração da planilha de Matthijs Maas, de Paths Untaken e do GPT-3).
4. De uma conversa privada com Rick Korzekwa, que pode ter lido https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1139110/ e um rascunho interno da AI Impacts, provavelmente por vir.
5. Mais aqui aqui e aqui. Não li nada disso, mas tem sido um tópico de discussão há algum tempo.
6. “Para ajudar a promover o sigilo, foram criados esquemas para melhorar os incentivos. Um método às vezes usado era que os autores enviassem artigos a periódicos para estabelecer sua reivindicação pela descoberta, mas solicitassem que a publicação dos artigos fosse adiada indefinidamente.26,27,28,29 Szilárd também sugeriu oferecer financiamento em vez de crédito no curto prazo para cientistas dispostos a se submeter ao sigilo e organizar circulação limitada de artigos-chave.30” – Eu, anteriormente
7. “Trancamento” de valores é o ato de usar tecnologia poderosa, como a IA, para garantir que valores específicos controlem de forma estável o futuro.
8. E também na Grã-Bretanha:
“Este artigo discute os resultados de uma pesquisa nacionalmente representativa da população do Reino Unido sobre suas percepções da IA (…) as visões mais comuns do impacto da IA provocam ansiedade significativa. Apenas duas das oito narrativas provocaram mais animação do que preocupação (IA facilitando a vida e prolongando a vida). Os entrevistados sentiram que não tinham controle sobre o desenvolvimento da IA, citando o poder das corporações ou do governo, ou versões do determinismo tecnológico. Negociar a implementação da IA exigirá lidar com essas ansiedades.”
9. Ou assim se preocupa Eliezer Yudkowsky —
Em MIRI anuncia nova estratégia “Morte com Dignidade”:
- “… Isso não é primeiramente um problema político-social, de apenas fazer com que as pessoas escutem. Mesmo que a DeepMind escutasse, e a Anthropic soubesse, e ambas desistissem de destruir o mundo, isso significaria que a Facebook AI Research destruiria o mundo um ano (?) depois.”
Em Ruína da IGA: Uma Lista de Letalidades::
- “Não podemos simplesmente ‘decidir não construir a IGA’ porque as GPUs estão em todos os lugares e o conhecimento dos algoritmos está constantemente sendo aprimorado e publicado; 2 anos após o ator principal ter a capacidade de destruir o mundo, outros 5 atores terão a capacidade de destruir o mundo. O desafio letal dado é resolver dentro de um limite de tempo, impulsionado pela dinâmica em que, com o tempo, atores cada vez mais fracos, com uma fração cada vez menor do poder computacional total, tornam-se capazes de construir IGA e destruir o mundo. Se todos os atores poderosos se abstiverem em uníssono de fazer a coisa suicida, isso apenas atrasará esse limite de tempo — não o suspenderá, a menos que o progresso do hardware e do software de computador sejam levados a paradas severas em toda a Terra. O estado atual desta cooperação para que todos os grandes atores se abstenham de fazer a coisa estúpida é que atualmente alguns grandes atores com muitos pesquisadores e poder computacional são liderados por pessoas que desdenham sonoramente de toda conversa sobre segurança da IGA (p. ex., a Facebook AI Research). Observe que precisar resolver o alinhamento da IGA apenas dentro de um limite de tempo, mas com retentativas seguras ilimitadas para experimentação rápida no sistema com potência total, ou apenas na primeira tentativa crucial, mas com um limite de tempo ilimitado, seriam ambos desafios terrivelmente ameaçadores para a humanidade para os padrões históricos, individualmente.”
10. Eu diria que os luditas genuínos também pensavam que as mudanças tecnológicas que enfrentavam eram antiprogresso, mas naquele caso eles estavam errados em querer evitá-las?
11. Ouvi dizer que isto é uma elaboração sobre esse tema, mas não a li.
12. Leopold Aschenbrenner define parcialmente o “Longo Prazo Burkeano” assim: “Devemos ser céticos com relação a quaisquer esquemas radicais de visão interna para orientar positivamente o futuro de longo prazo, dada a espuma de incerteza sobre as consequências de nossas ações”.
Publicado originalmente em 22 de dezembro de 2022 aqui.
Autora: Katja Grace
Tradução: Luan Marques