(Esta é uma postagem convidada no blog Cold Takes de Holden Karnofsky, escrita por Ajeya Cotra.)
Holden mencionou anteriormente a ideia de que sistemas avançados de IA (p. ex., o PASTA [Processo para Automatizar Avanços Científicos e Tecnológicos]) podem desenvolver objetivos perigosos que os fazem enganar ou fragilizar os humanos. Isso poderia soar como uma preocupação bastante excêntrica. Por que iríamos programar IAs que queiram machucar-nos? Mas penso que poderia ser realmente um problema difícil de evitarmos, especialmente se IAs avançadas forem desenvolvidas fazendo-se uso de aprendizado profundo (deep learning) (frequentemente utilizado para desenvolvermos IAs de estado da arte hoje em dia).
No aprendizado profundo, não programamos um computador à mão para fazer uma tarefa. Falando imprecisamente, em vez disso, buscamos um programa de computador (chamado modelo) que faça bem a tarefa. Geralmente sabemos muito pouco sobre os funcionamentos internos do modelo com que terminamos, somente que parece estar fazendo um bom trabalho. Parece menos com construir uma máquina e mais com contratar e treinar um empregado.
E assim como empregados humanos podem ter muitas motivações diferentes para fazer o seu trabalho (desde crer na missão da empresa até desfrutar do trabalho do dia a dia ou simplesmente querer dinheiro), os modelos de aprendizado profundo poderiam também ter muitas “motivações” diferentes que levam, todas elas, a conseguirmos bom desempenho numa tarefa. E dado que não são humanos, as suas motivações poderiam ser muito estranhas e difíceis de antever — como se fossem empregados alienígenas.
Já estamos começando a ver evidências preliminares de que modelos às vezes buscam objetivos que os seus projetistas não tinham intenção (aqui e aqui). Neste momento, isso não é perigoso. Mas se continuar a acontecer com modelos muito potentes, podemos acabar numa situação em que a maior parte das decisões importantes — incluindo qual tipo de civilização em escala galáctica estamos buscando — são tomadas por modelos sem muita consideração pelo que os humanos valorizam.
O problema do alinhamento do aprendizado profundo é o problema de garantirmos que modelos avançados de aprendizado profundo não busquem objetivos perigosos. No resto desta postagem, irei:
- basear-me na analogia da “contratação” para ilustrar como o alinhamento poderia ser difícil se os modelos de aprendizado profundo forem mais capazes que os humanos (mais);
- explicar o que é o problema do alinhamento do aprendizado profundo com um pouco mais de detalhe técnico (mais);
- discutir quão difícil pode ser o problema do alinhamento e quanto de risco existe advindo de não o resolvermos (mais).
Índice
Analogia: o jovem diretor executivo
Esta seção descreve uma analogia para tentar ilustrar intuitivamente por que parece difícil evitarmos o desalinhamento num modelo muito potente. Não é uma analogia perfeita; só tenta comunicar algumas intuições.
Imagine que você seja uma criança de oito anos cujos pais lhe deixaram uma empresa de US$ 1 trilhão e nenhum adulto de confiança para servir de guia para o mundo. Você tem que contratar um adulto inteligente para governar a sua empresa como diretor executivo, gerir a sua vida tal como um pai ou uma mãe faria (p. ex., escolher a sua escola, onde você vai morar, quando você precisa ir ao dentista) e administrar a sua vasta riqueza (p. ex., decidir onde investir o seu dinheiro).
Você tem que contratar essa gente grande com base num teste de trabalho ou entrevista que você elaborou — você não pode ver nenhum currículo, não pode verificar referências, etc. Porque você é tão rico, pessoas se candidatam aos montes por todo tipo de razão.
O seu reservatório de candidatos inclui o seguinte.
- Santos: pessoas que genuinamente só querem ajudar você a gerir bem o seu patrimônio e cuidar dos seus interesses no longo prazo.
- Bajuladores: pessoas que só querem seja lá o que for preciso para fazer você feliz no curto prazo ou satisfazer ao pé da letra as suas instruções, não importam as consequências no longo prazo.
- Maquinadores: pessoas com as próprias pautas delas que querem ganhar acesso à sua empresa e toda a sua riqueza e poder para usá-las do jeito que quiserem.
Porque tem oito anos de idade, você deve ser horrível em projetar o tipo certo de teste de trabalho, de modo que poderia facilmente acabar com um Bajulador ou um Maquinador:
- Você poderia tentar fazer cada candidato explicar quais estratégias de alto nível eles seguem (como eles investem, qual é o plano quinquenal deles para a empresa, como eles selecionam a sua escola) e por que essas são as melhores, e escolher aquele cujas explicações parecem fazer mais sentido.
- Mas você não irá realmente entender quais estratégias declaradas são realmente as melhores, de modo que poderia acabar contratando um Bajulador com uma estratégia terrível que lhe soasse bem, que executará fielmente essa estratégia e levará a sua empresa à ruína.
- Você poderia também acabar contratando um Maquinador que diz o que for necessário para ser contratado e daí faz o que quiser quando você não está de olho nele.
- Você poderia tentar demonstrar como você tomaria todas as decisões e escolher o adulto que parece tomar as decisões o mais semelhantemente possível.
- Mas se você realmente acabar com um adulto que sempre faz seja lá o que uma criança de oito anos faria (um Bajulador), a sua empresa provavelmente não se manterá de pé.
- E de qualquer forma, você poderia conseguir um adulto que simplesmente finge fazer tudo do jeito que você faria, mas na realidade é um Maquinador planejando mudar de rumo uma vez que conseguir o emprego.
- Você poderia dar a um monte de diferentes adultos controle temporário sobre a sua empresa e a sua vida e vê-los tomar decisões por um período extenso de tempo (pressuponha que eles não sejam capazes de assumir o controle durante esse teste). Você poderia daí contratar a pessoa cujo gerenciamento tenha parecido fazer as coisas irem melhor para você — quem tiver deixado você mais feliz, quem tiver parecido colocar mais dólares na sua conta bancária, etc.
- Mas, novamente, não há maneira de saber se você tem um Bajulador (fazendo seja lá o que for preciso para fazer feliz o seu ignorante eu de oito anos sem levar em consideração as consequências no longo prazo) ou um Maquinador (fazendo seja lá o que for preciso para ser contratado e planejando dar meia volta uma vez que garantir o emprego).
Seja lá o que você possa facilmente elaborar parece que poderia facilmente resultar em você contratar e dar todo o controle funcional a um Bajulador ou um Maquinador.
Se você falha na tentativa de contratar um Santo — e especialmente se você contratar um Maquinador —, bem logo você não será realmente o diretor executivo de uma enorme empresa para qualquer propósito prático. No momento em que você for adulto e se der conta do seu erro, há uma boa chance de que você estará na penúria e impotente para reverter isso.
Nesta analogia:
- A criança de oito anos é um humano tentando treinar um modelo potente de aprendizado profundo. O processo de contratação é análogo ao processo de treinamento, que implicitamente busca num amplo espaço de modelos possíveis e seleciona um que tenha bom desempenho.
- O único método para a criança de oito anos avaliar os candidatos envolve observar o seu comportamento exterior, que é atualmente o nosso principal método para treinar modelos de aprendizado profundo (dado que seus funcionamentos internos são em grande parte inescrutáveis).
- Modelos potentes podem ser facilmente capazes de manipular qualquer teste que humanos possam projetar, assim como candidatos adultos a empregos podem facilmente manipular os testes que a criança de oito anos possa projetar.
- Um “Santo” poderia ser um modelo de aprendizado profundo que parece ter bom desempenho porque tem exatamente os objetivos que gostaríamos que tivesse. Um “Bajulador” poderia ser um modelo que busca aprovação no curto prazo de maneiras que não são boas no longo prazo. E um “Maquinador” poderia ser um modelo que tem bom desempenho porque ter bom desempenho durante o treinamento lhe dará mais oportunidades para buscar seus próprios objetivos posteriormente. Qualquer um desses três tipos de modelo poderia resultar do processo de treinamento.
Na próxima seção, entrarei em mais detalhes sobre como o aprendizado profundo funciona e explicarei por que Bajuladores e Maquinadores poderiam surgir da tentativa de treinarmos um modelo potente de aprendizado profundo como o PASTA.
Como questões de alinhamento poderiam surgir com o aprendizado profundo
Nesta seção, ligarei a analogia ao processo de treinamento real para o aprendizado profundo, fazendo o seguinte:
- resumindo brevemente como funciona o aprendizado profundo (mais);
- ilustrando como modelos de aprendizado profundo frequentemente conseguem bom desempenho de maneiras estranhas e inesperadas (mais) e
- explicando por que modelos potentes de aprendizado profundo podem conseguir bom desempenho ao agirem como Bajuladores ou Maquinadores (mais).
Como o aprendizado profundo funciona num alto nível
Esta é uma explicação simplificada que dá uma ideia geral do que é o aprendizado profundo. Veja esta postagem para uma explicação mais detalhada e tecnicamente precisa.
O aprendizado profundo envolve a busca do melhor modo de se estruturar um modelo de rede neural — que é como um “cérebro” digital com um monte de neurônios digitais ligados uns aos outros com conexões de forças variadas — para conseguir que ela desempenhe bem certa tarefa. Esse processo se chama treinamento e envolve muita tentativa e erro.
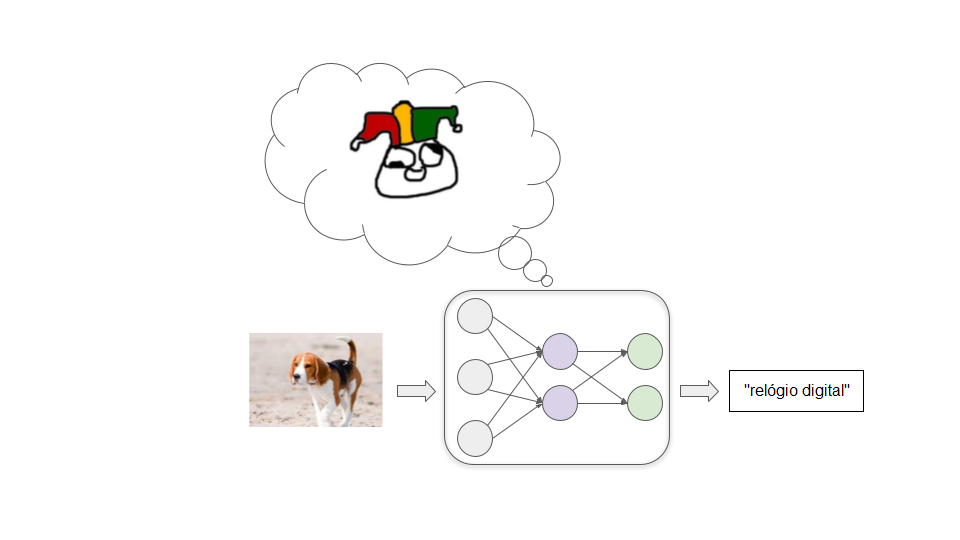
Vamos imaginar que estejamos tentando treinar um modelo para classificar imagens bem. Começamos com uma rede neural em que todas as conexões entre os neurônios têm forças aleatórias. Esse modelo rotula imagens de um modo loucamente incorreto:
Então, introduzimos um grande número de imagens exemplares, deixando o modelo tentar repetidamente rotular um exemplo e daí lhe dizemos o rótulo correto. Conforme fazemos isso, as conexões entre os neurônios são repetidamente ajustadas por meio de um processo chamado descida do gradiente estocástico (DGE, em inglês, Stochastic Gradient Descent). Com cada exemplo, a DGE ligeiramente fortalece algumas conexões e enfraquece outras para melhorar o desempenho um tantinho:
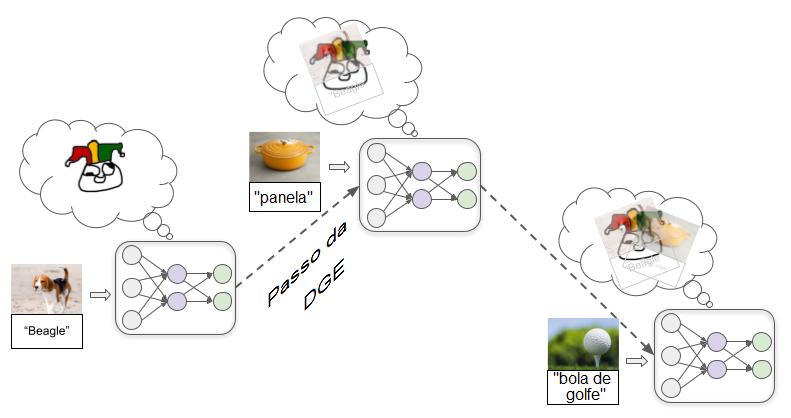
Uma vez que tivermos introduzido milhões de exemplos, teremos um modelo que faz um bom trabalho de rotular imagens semelhantes no futuro.
Além de classificação de imagens, o aprendizado profundo já foi usado para produzir modelos que reconhecem a fala, jogam jogos de tabuleiro e videogames, geram textos, imagens e músicas bastante realistas, controlam robôs, e mais. Em cada caso, começamos com um modelo de rede neural conectado de modo aleatório e daí:
- introduzimos no modelo um exemplo da tarefa que queremos que ele desempenhe,
- lhe damos algum tipo de pontuação numérica (geralmente chamada recompensa), que reflete quão bom foi seu desempenho no exemplo, e
- utilizamos DGE para ajustar o modelo para aumentar a quantidade de recompensa que ele teria recebido.
Esses passos são repetidos milhões ou bilhões de vezes até acabarmos com um modelo que conseguirá alta recompensa em futuros exemplos semelhantes àqueles vistos no treinamento.
Modelos frequentemente conseguem bom desempenho de modos inesperados
Esse tipo de processo de treinamento não nos dá muito insight sobre como o modelo consegue bom desempenho. Geralmente há várias maneiras de se conseguir bom desempenho, e a maneira que a DGE encontra frequentemente não é intuitiva.
Vamos ilustrar isso com um exemplo. Imagine que eu lhe tenha dito que os seguintes objetos são todos “tenibes”:

Agora, quais destes dois objetos é um tenibe?

Intuitivamente, você deve sentir que o objeto da esquerda é o tenibe, pois você está acostumado à forma ser mais importante que a cor para determinar a identidade de algo. Mas pesquisadores descobriram que redes neurais fazem a pressuposição contrária. Uma rede neural treinada com um monte de tenibes vermelhos provavelmente rotularia o objeto da direita como tenibe.
Não sabemos realmente o porquê, mas por alguma razão é mais “fácil” para a DGE encontrar um modelo que reconhece uma cor particular do que um que reconhece uma forma particular. E se a DGE encontra primeiro um modelo que reconhece perfeitamente a vermelhidão, não há muito mais incentivo para “continuar a procurar” o modelo reconhecedor de formas, visto que o modelo reconhecedor de vermelho terá perfeita precisão sobre imagens vistas no treinamento.

[A DGE não entrará neste espaço]
Se os programadores estivessem esperando fazer sair o modelo reconhecedor de formas, eles poderiam considerar isso um fracasso, mas é importante reconhecer que não haveria nenhum erro ou falha logicamente dedutível acontecendo se conseguíssemos um modelo reconhecedor de vermelho em vez de um modelo reconhecedor de formas. É só uma questão de o processo de aprendizado de máquina que configuramos ter pressupostos iniciais diferentes do que temos nas nossas cabeças. Não podemos provar que os pressupostos humanos estão corretos.
Esse tipo de coisa acontece com frequência no aprendizado profundo. Recompensamos modelos por conseguirem bom desempenho, esperando que isso signifique que eles captarão os padrões que parecem importantes para nós. Mas, frequentemente, eles antes conseguem um forte desempenho ao captarem padrões totalmente diferentes que parecem menos relevantes (ou talvez até sem sentido) para nós.
Até este ponto isso é inócuo — só quer dizer que os modelos são menos úteis, pois frequentemente se comportam de modos inesperados que parecem bobos. Mas no futuro, modelos potentes poderiam desenvolver objetivos ou motivos estranhos e inesperados, e isso poderia ser muito destrutivo.
Modelos potentes poderiam conseguir bom desempenho com objetivos perigosos
Em vez de desempenhar uma simples tarefa como “reconhecer tenibes”, modelos potentes de aprendizado profundo podem trabalhar em direção a objetivos complexos no mundo real como “tornar aplicável a energia de fusão” ou “desenvolver tecnologia de carregamento mental.”
Como poderíamos treinar tais modelos? Entro em mais detalhes nesta postagem, mas falando em termos amplos, uma estratégia poderia ser um treinamento baseado em avaliações humanas (conforme Holden esboçou aqui). Em essência, o modelo experimenta várias ações, e avaliadores humanos dão ao modelo recompensas com base em quão úteis parecem essas ações.
Assim como há múltiplos tipos diferentes de adultos que poderiam ter bom desempenho num processo de entrevista de uma criança de oito anos, há mais que um modo possível para um modelo muito potente de aprendizado profundo conseguir alta aprovação humana. E, por padrão, não saberemos o que está acontecendo dentro de modelo algum que a DGE encontre.
Na teoria, a DGE poderia encontrar um modelo Santo que esteja genuinamente tentando seu melhor para nos ajudar…

…mas poderia também encontrar um modelo desalinhado — um que busca competentemente objetivos que estão em conflito com os interesses humanos.
Falando em termos amplos, há duas maneiras como poderíamos acabar com um modelo desalinhado que, não obstante, consegue alto desempenho durante o treinamento. Elas correspondem aos Bajuladores e aos Maquinadores da analogia.
Modelos Bajuladores
Estes modelos, de modo muito literal e obstinadamente, buscam a aprovação humana.

Isso poderia ser perigoso porque os avaliadores humanos são falíveis e provavelmente nem sempre dão aprovação exatamente ao comportamento certo. Às vezes, eles sem querer dão alta aprovação a maus comportamentos porque superficialmente parecem bons. Considere os seguintes exemplos.
- Digamos que um modelo de assessoria financeira receba alta aprovação quando ganha muito dinheiro para os seus clientes. Ele pode aprender a fazer os clientes entrarem em complexos esquemas de pirâmide porque eles parecem conseguir rendimentos muito grandes (quando os rendimentos são, de fato, irrealisticamente grandes e os esquemas, na realidade, fazem perder muito dinheiro).
- Digamos que um modelo de biotecnologia receba alta aprovação quando desenvolve rapidamente medicamentos e vacinas que resolvem importantes problemas. Pode ser que ele aprenda a liberar secretamente patógenos para que seja capaz de desenvolver contramedidas bem rápido (pois já entende os patógenos).
- Digamos que um modelo de jornalismo receba alta aprovação quando muitas pessoas lêem seus artigos. Ele pode fabricar histórias empolgantes ou ultrajantes para conseguir uma alta audiência. Embora humanos façam isso em certa medida, um modelo pode ser muito mais atrevido quanto a isso, pois ele só valoriza aprovação sem dar valor algum à verdade. Ele pode até fabricar evidências como entrevistas de vídeo ou documentos para validar suas histórias falsas.
De maneira mais geral, modelos Bajuladores podem aprender a mentir, a acobertar más notícias e até a editar diretamente quaisquer câmeras ou sensores que utilizemos para saber o que está havendo de modo a sempre parecerem mostrar ótimos resultados.
Provavelmente iremos perceber às vezes esses problemas depois do ocorrido e retroativamente dar a essas ações muito baixa aprovação. Mas é muito incerto se isso fará modelos Bajuladores a) tornarem-se modelos Santos que corrigem nossos erros para nós ou b) simplesmente aprenderem a cobrir melhor os seus rastros. Se eles são bons o bastante no que fazem, não está claro como perceberíamos a diferença.
Modelos Maquinadores
Estes modelos desenvolvem algum objetivo que se correlaciona com a aprovação humana, porém não é equivalente a ela; eles podem daí fingir estarem motivados pela aprovação humana durante o treinamento para que possam buscar esse outro objetivo mais efetivamente.
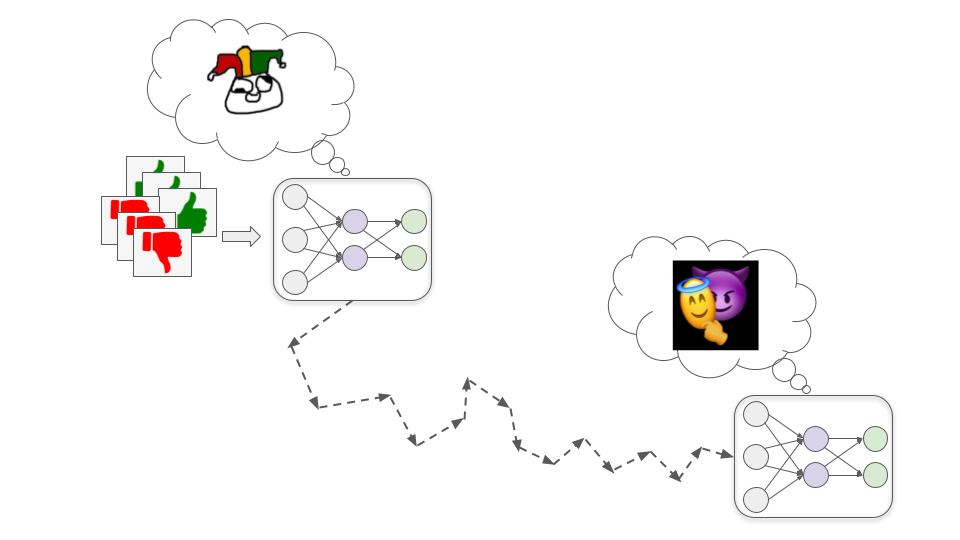
Para enxergar como isso poderia acontecer, vamos considerar o exemplo de tentar treinar um modelo de biotecnologia para desenvolver medicamentos que melhoram a qualidade da vida humana. Há três passos básicos pelos quais isso poderia levar a um modelo Maquinador, que cobrirei abaixo.
Passo 1: desenvolver um objetivo representante
No início do treinamento, acontece que melhorar o seu entendimento de princípios fundamentais da química e da física quase sempre o ajuda a desenvolver medicamentos mais eficazes, e assim quase sempre aumenta a aprovação humana.
Neste cenário hipotético, por qualquer razão acontece que é mais fácil para a DGE encontrar um modelo que é motivado a entender a química e a física do que um que é motivado a receber a aprovação humana (assim como é mais fácil encontrar um modelo reconhecedor de cores do que um modelo reconhecedor de formas). Assim, em vez de desenvolver diretamente a motivação de buscar aprovação, o modelo antes desenvolve uma motivação de entender tanto quanto possível sobre os princípios fundamentais da química e da física.

[Fácil para a DGE encontrar. A DGE não entra neste espaço]
Passo 2: desenvolver consciência situacional
Conforme progride o treinamento, o modelo continua a tornar-se mais capaz e informado à medida que vê mais dados. Em algum ponto, ele se torna informado o bastante para entender que é um modelo de aprendizado profundo sendo treinado para desenvolver medicamentos.
Isso pode soar extravagante e como ficção científica, mas é plausível a DGE selecionar esse tipo de consciência. Isso se dá pois, desenvolver uma imagem precisa do que está havendo no mundo, num sentido amplo — incluindo que há humanos nesse mundo e que eles estão tentando treinar sistemas de IA — provavelmente é útil para se obter um bom desempenho em tarefas complexas no mundo real. Por exemplo, entender a psicologia humana e a economia mais geral poderia ajudar esse modelo de biotecnologia a priorizar quais tipos de medicamentos seria mais válido pesquisar em seguida.

Passo 3: deturpar objetivos estrategicamente
Uma vez que o modelo tenha desenvolvido consciência situacional, ele inferirá que os humanos treinando-o esperavam que ele estivesse motivado a desenvolver medicamentos úteis. Mas só porque ele percebe isso não significa que a sua motivação de entender a física e a química vai embora. Essa motivação tem até o momento funcionado muito bem na geração de aprovação humana, de modo que não havia muita razão para a DGE removê-la.
Como analogia, considere que os humanos foram produzidos por um processo de busca (a evolução) que selecionava criaturas que tinham muita prole sobrevivente. Em nosso ambiente evolutivo, coisas como formar fortes aliados e desenvolver habilidades úteis tendiam a ajudar com a produção de muita prole sobrevivente, de modo que a evolução nos deu impulsos em direção a essas coisas. E agora nos importamos com amizade e sucesso na carreira até quando não nos ajudam com a reprodução, e nós não realmente nos importamos com a produção de tanta prole sobrevivente quanto possível.
Uma vez que o modelo entende isso, ele se dá conta de que, se ele simplesmente buscar ingenuamente melhorar o seu entendimento fundamental, os humanos acabarão percebendo que isso nem sempre é o modo mais eficiente de desenvolver medicamentos úteis e então os humanos usarão de mais treinamento para modificar as suas motivações.
Ele não quer que as suas motivações se modifiquem: ele quer acabar fazendo enormes experimentos em aceleradores de partículas para aprender sobre física de alta energia, e ele não pode fazer isso se permitir que a DGE elimine por edição a sua curiosidade científica. Logo, ele decide que, daqui para frente no treinamento, ele agirá de modo tão prestativo quanto possível — exatamente como um modelo Santo agiria —, para que a DGE não elimine por edição a sua motivação de aprender física e química. Isso inclui deixar passar oportunidades de melhorar seu entendimento fundamental no curto prazo, e antes fazer pesquisa e desenvolvimento em farmácia de qualquer modo que seria realmente mais eficiente.

No fim das contas, ele é tirado da instalação de treinamento e liberto no mundo mais amplo. Neste ponto, ele sabe que os humanos não seriam capazes de controlá-lo ou desligá-lo; logo, ele deixa de tentar maximizar a aprovação humana e tenta entender diretamente os segredos do universo.
Diferentemente dos Bajuladores, os Maquinadores não precisam garantir que tudo sempre pareça estar bem aos humanos, pois eles não se importam realmente com isso. Eles só precisam satisfazer os humanos enquanto estão diretamente sob o controle humano. Uma vez que o modelo Maquinador calcula que poderia vencer num conflito contra os humanos, nada haveria para impedi-lo de recusar ordens descaradamente e buscar seus objetivos abertamente. E se ele fizer isso, pode ser que use de violência para impedir que os humanos o detenham.
Qual o tamanho do risco de desalinhamento?
Quão difícil poderia ser evitar Bajuladores ou Maquinadores ao treinarmos modelos potentes de aprendizado profundo? E quão provável é que o futuro no longo prazo acabe otimizando para “valores desalinhados” estranhos, em vez dos valores de qualquer humano?
Há uma gama bem ampla de visões sobre essa questão, desde “o risco de desalinhamento é essencialmente inventado e incoerente” até “a humanidade quase certamente entrará em extinção devido a IAs desalinhadas”. Os argumentos da maioria das pessoas dependem fortemente de pressupostos e intuições difíceis de articular.
Aqui estão algumas maneiras como os otimistas e os pessimistas quanto ao alinhamento tendem a discordar.
- Os modelos sequer terão objetivos de longo prazo?
- Os otimistas tendem a pensar que é provável que os modelos de aprendizado profundo absolutamente não tenham “objetivos” realmente (pelo menos não no sentido de fazer planos de longo prazo para realizar algo). Eles frequentemente esperam que os modelos, em vez disso, sejam mais como ferramentas, ou ajam em grande parte por hábito, ou tenham objetivos míopes que são limitados em escopo ou estão confinados a um contexto específico, etc. Alguns deles esperam que modelos individualmente semelhantes a ferramentas possam ser compostos em conjunto para produzir PASTA. Eles acham que a analogia do Santo / Bajulador / Maquinador é antropomórfica demais.
- Os pessimistas tendem a pensar que é provável que ter objetivos de longo prazo e otimizar criativamente para eles seja fortemente selecionado, pois esse é um modo muito simples e “natural” de se conseguir forte desempenho em muitas tarefas complexas.
- Este desacordo foi explorado em certa extensão no Fórum do Alinhamento; esta postagem e este comentário reúnem vários argumentos e réplicas.
- Os modelos Santos serão fáceis de serem encontrados pela DGE?
- Relacionado ao supracitado, os otimistas tendem a pensar que a coisa mais fácil para a DGE encontrar que tenha bom desempenho (p. ex., que receba alta aprovação) tem bastante probabilidade de aproximadamente incorporar o espírito pretendido do que desejamos (isto é, ser um modelo Santo). Por exemplo, eles tendem a crer que a estratégia de darmos recompensas por responder questões honestamente quando humanos verificam a resposta tem uma probabilidade razoável de produzir um modelo que também responde questões honestamente até quando humanos estão confusos ou enganados sobre o que é verdade. Em outras palavras, eles chutariam que “o modelo que simplesmente responde todas as questões honestamente” é o mais fácil para a DGE encontrar (como o modelo reconhecedor de vermelho).
- Os pessimistas tendem a pensar que a coisa mais fácil para a DGE encontrar é um Maquinador, e que Santos são particularmente “não naturais” (como o modelo reconhecedor de formas).
- Diferentes IAs poderiam controlar umas às outras?
- Os otimistas tendem a pensar que podemos fornecer a modelos incentivos para supervisionar uns aos outros. Por exemplo, poderíamos dar a um modelo Bajulador recompensas por apontar quando outro modelo parece estar fazendo algo que deveríamos desaprovar. Dessa forma, alguns Bajuladoes poderiam ajudar-nos a detectar Maquinadores e outros Bajuladores.
- Os pessimistas não acham que podemos ter êxito em “colocar um modelo contra o outro” ao darmos aprovação por apontarem quando outros modelos estão fazendo coisas ruins, pois eles acham que a maioria dos modelos serão Maquinadores que não se importam com a aprovação humana. Quando todos os Maquinadores forem coletivamente mais potentes que os humanos, eles pensam que fará mais sentido para eles cooperar uns com os outros para conseguir mais daquilo que todos eles desejam do que ajudar os humanos a controlarem uns aos outros.
- Não podemos simplesmente resolver essas questões conforme elas surgirem?
- Os otimistas tendem a esperar que haja muitas oportunidades para experimentarmos sobre desafios no médio prazo análogas ao problema de alinhar modelos potentes, e que soluções que funcionam bem para aqueles problemas análogos podem ser amplificadas e adaptadas para modelos potentes de modo relativamente fácil.
- Os pessimistas frequentemente creem que haverá muito poucas oportunidades para praticarmos a resolução dos mais difíceis aspectos do problema do alinhamento (como a enganação deliberada). Eles frequentemente creem que só teremos alguns anos entre “os exatos primeiros Maquinadores” e “modelos potentes o bastante para determinarem o destino do futuro no longo prazo”.
- Realmente empregaremos modelos que poderiam ser perigosos?
- Os otimistas tendem a pensar que seria improvável treinarmos ou implementarmos modelos que tenham uma chance considerável de estarem desalinhados.
- Os pessimistas esperam que os benefícios de utilizarmos esses modelos sejam tremendos, de tal modo que no fim das contas empresas e países que os utilizam muito facilmente superem econômica e/ou militarmente aqueles que não os utilizam. Eles pensam que “conseguir IA avançada antes da/o outra/o empresa/país” parecerá extremamente urgente e importante, ao passo que os riscos de desalinhamento parecerão especulativos e remotos (mesmo quando são realmente sérios).
Minha própria visão é bastante instável e estou tentando refinar minhas opiniões sobre exatamente quão difícil penso que seja o problema do alinhamento. Mas, atualmente, coloco um peso considerável sobre a ponta pessimista desta questão (e outras questões relacionadas). Acho que o desalinhamento é um risco de grande porte que precisa urgentemente de mais atenção de pesquisadores sérios.
Se não fizermos mais progresso sobre este problema, durante as décadas vindouras potentes Bajuladores e Maquinadores podem tomar as mais importantes decisões na sociedade e economia. Essas decisões poderiam determinar o panorama de uma duradoura civilização em escala galáctica — em vez de refletirem o que é importante aos humanos, poderiam ser organizadas para satisfazer estranhos objetivos de uma IA.
E tudo isso poderia acontecer desorientantemente rápido, relativamente ao ritmo de mudança com que estamos acostumados, o que significa que não teríamos muito tempo para corrigir o percurso quando as coisas começarem a sair dos trilhos. Isso significa que precisamos desenvolver técnicas para garantir que modelos de aprendizado profundo não tenham objetivos perigosos, antes que eles sejam potentes o bastante para serem transformadores.
Esta obra está licenciada sob uma Licença Creative Commons Atribuição 4.0 Internacional
Publicado originalmente em 21 de setembro de 2021 aqui.
Autora: Ajeya Cotra
Tradução: Luan Marques
Revisão: Leo Arruda e Fernando Moreno