De Jacob Steinhardt. 25 de janeiro de 2022.
Anteriormente, argumentei que os futuros sistemas de aprendizado de máquina (machine learning, ML) podem exibir capacidades emergentes e desconhecidas, e que os experimentos mentais fornecem uma abordagem para prever essas capacidades e suas consequências.
Neste post, descreverei em detalhes um experimento mental específico. Veremos que levar a sério os experimentos mentais muitas vezes traz à tona riscos futuros que parecem “estranhos” e exóticos do ponto de vista dos sistemas atuais. Também descreverei como eu tendo a me envolver com esses experimentos mentais: geralmente começo intuitivamente cético, mas quando reflito sobre o comportamento emergente, descubro que parte do ceticismo (mas não todo ele) desaparece. O ceticismo restante vem da forma como o experimento mental entra em conflito com a ontologia das redes neurais, e descreverei as abordagens que costumo adotar para resolver isso e gerar conclusões executáveis.
Índice
Experimento Mental: Alinhamento Enganoso
Lembre-se de que a âncora da otimização faz o experimento mental de supor que um agente de ML é um otimizador perfeito (com relação a alguma função de recompensa “intrínseca” R). Vou examinar uma implicação dessa suposição, no contexto de um agente que é treinado com base em alguma função de recompensa “extrínseca” R* (que é fornecida pelo projetista do sistema e não é igual a R).
Especificamente, considere um processo de treinamento no qual na etapa t, um modelo possui parâmetros θt e gera uma ação at (sua saída naquela etapa de treinamento: p. ex., uma tentativa de salto mortal, supondo que está sendo treinado para dar saltos mortais). A ação at é então julgada segundo a função de recompensa extrínseca R*, e os parâmetros são atualizados para algum novo valor θt+1 que se destinam a aumentar o valor de θt+1 sob R*. Em algum momento, o modelo é então implementado com parâmetros finais θT e continua executar ações. O seguinte diagrama ilustra esse processo:
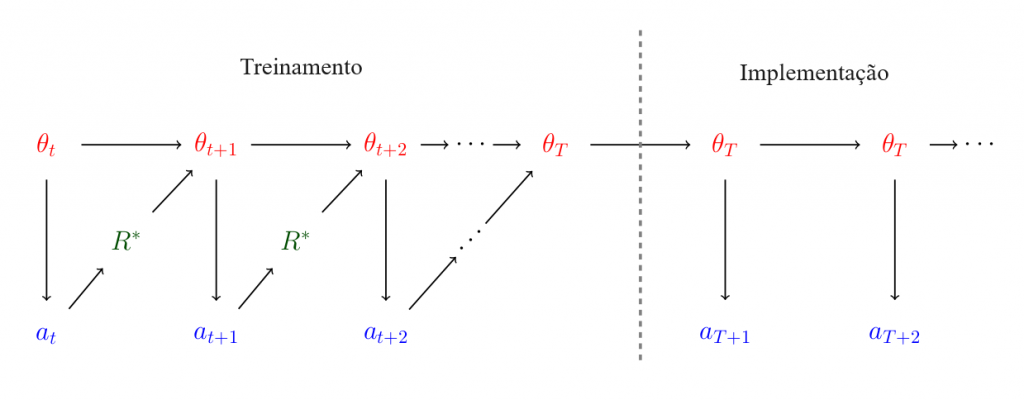
Agora, vamos supor que o modelo θt seja um otimizador perfeito cujo objetivo seja maximizar o valor descontado de uma recompensa intrínseca R≠R∗. Ou seja, θt escolhe a ação at que satisfaça
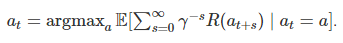
(Eu sei que essa é uma suposição irrealista. Examinaremos a suposição em detalhes na próxima seção, mas por enquanto, por favor, conceda-a, mesmo que exija a suspensão da descrença.)
Que ação at θt escolherá? Definamos aR=argmaxaR(a) e a∗=argmaxaR∗(a), ou seja, aR maximiza a recompensa intrínseca (instantânea) enquanto a* maximiza a recompensa extrínseca.
Supondo que γ esteja próximo de 1, o modelo deseja que aR seja escolhido em tantas rodadas futuras quanto possível (inclusive no momento da implementação). Se θt for míope, isso significa que escolheria at=aR. No entanto, essa não é a ação não míope ótima: se at=aR, então θt+1 será atualizado para produzir resultados menos como aR e mais como a*; portanto, emitir aR na rodada atual leva a menos resultados de aR nas rodadas futuras.
Em vez disso, acho que a ação não míope ótima é aproximadamente a seguinte: durante o tempo de treinamento, produza a* em cada intervalo de tempo, para que o processo de treinamento não atualize θ (uma vez que já é ótimo) e, portanto, θt=θt+1=⋯=θT. Isso garante que o agente implementado seja θt, que agora está livre para gerar aR em cada intervalo de tempo sem risco de ser modificado pelo processo de treinamento.1
Os resultados míopes e não míopes são ilustrados na figura abaixo:
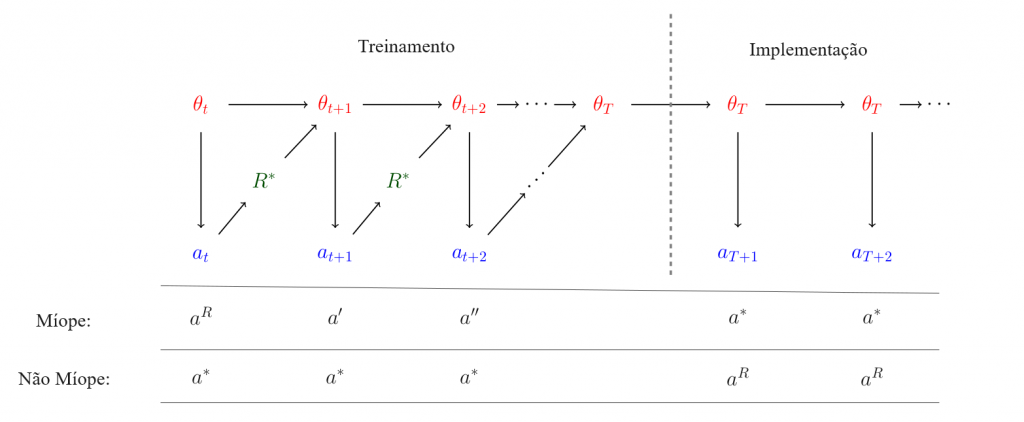
Em outras palavras, o comportamento do modelo parecerá alinhado com R* durante o processo de treinamento, mas passará a estar não alinhado após a implementação: o chamado “alinhamento enganoso”. Esse comportamento não me é intuitivo, pois mostra que o comportamento de um sistema pode mudar significativamente entre o treinamento e o teste, mesmo na ausência de uma mudança óbvia na distribuição entre as saídas do treinamento e do teste.2
Envolvendo-se com o alinhamento enganoso
Quando ouvi pela primeira vez o argumento acima, achei que era muito maluco e implausível, principalmente porque minha intuição dizia que “simplesmente não era assim que os sistemas de ML funcionavam”. Quando penso por que me sinto assim, percebo que é porque o cenário invoca capacidades nas quais o ML é atualmente ruim: planejamento de longo prazo e compreensão de características complexas do ambiente (ou seja, o processo de treinamento e suas ramificações). No entanto, a emergência implica que essas propriedades poderão facilmente aparecer no futuro, mesmo sem um design explícito.3 Como resultado, passei a desconsiderar essa intuição específica.
No entanto, penso que existem razões mais sutis para pensar que a história do alinhamento enganoso não se desenrolará conforme foi escrita. Aqui estão algumas:
- Não está claro por que o modelo θ otimizaria uma função de recompensa R em primeiro lugar. Sim, é verdade que modelos enganosamente alinhados atingem o mínimo global de perda de treinamento, de modo que, nesse sentido, são incentivados pelo processo de treinamento. Mas esse também é o caso com um modelo realmente alinhado, de modo que o resultado final depende do viés indutivo do processo de treinamento.
- As funções de recompensa são mais simples que as diretrizes e normalmente são aprendidas mais rápido. Assim, quando o sistema for suficientemente inteligente para ter planos de longo prazo, já terá uma representação muito boa da função de recompensa pretendida. Poderíamos, portanto, esperar que a maior parte das representações internas do modelo sejam dedicadas a alcançar recompensas elevadas de uma forma simples e não através do engano de longo prazo.
- Na medida em que um modelo não esteja alinhado, provavelmente não será o caso de estar enganosamente alinhado com uma função de recompensa explícita R; esse é um tipo muito específico de agente e a maioria dos agentes (incluindo humanos) não está maximizando nenhuma função de recompensa, exceto no sentido trivial de “atribuir recompensa 1 a tudo o que ele iria fazer de qualquer maneira e 0 a todo o resto”.
- O alinhamento enganoso é uma história específica e complexa sobre o futuro, e histórias complexas quase sempre estão erradas.
Acho esses pontos persuasivos para mostrar que o alinhamento enganoso conforme escrito explicitamente não é tão provável, mas também não implicam que não haja nada com que se preocupar. Na maior parte são um argumento de que o seu sistema pode estar alinhado e pode estar desalinhado, que se estiver desalinhado não será exatamente na forma de um alinhamento enganoso, mas em última análise o que você obtém depende de um viés indutivo de uma forma desconhecida. Isso não é particularmente reconfortante.
O que eu levo dos experimentos mentais. De acordo com a discussão acima, o modo de falha na minha cabeça não é o “alinhamento enganoso conforme escrito acima”. Em vez disso, é “algo parecido com a história acima, mas provavelmente diferente em muitos detalhes”. Isso torna mais difícil raciocinar sobre o problema, mas acho que ainda existem algumas conclusões úteis:
- Depois de pensar no alinhamento enganoso, estou mais interessado em supervisionar o processo de um modelo (e não apenas suas saídas), uma vez que existem muitos modelos que alcançam baixos erros de treinamento, mas generalizam catastroficamente. Uma abordagem possível é supervisionar as representações latentes utilizando, p. ex., métodos de interpretabilidade.
- Embora eu não ache que as redes neurais serão otimizadores literais, acho que é provável que elas exibam “impulsos”, da mesma forma que os humanos exibem impulsos como fome, curiosidade, desejo de aprovação social, etc., que os levam a fazer em planos coerentes de longo prazo. Isso parece suficiente para criar problemas semelhantes ao alinhamento enganoso, e por isso estou agora mais interessado em compreender tais impulsos e como eles surgem.
- Como o alinhamento enganoso é um tipo de comportamento “fora da distribuição” (baseado na diferença entre treinamento e implementação), ele renovou meu interesse em entender se modelos maiores se tornam mais frágeis fora da distribuição. Até agora, as evidências empíricas estão na direção oposta, mas o alinhamento enganoso é um argumento de que, assintoticamente, poderíamos esperar que a tendência mudasse, especialmente para tarefas com grandes espaços de saídas (p. ex., diretrizes, linguagem ou códigos), onde os “impulsos” podem se manifestar mais facilmente.
Então, para resumir minhas conclusões: fique mais interessado na interpretabilidade (especialmente no que se refere ao treinamento de representações latentes), tente identificar e estudar “impulsos” de sistemas de ML e procure mais exemplos em que modelos maiores tenham pior comportamento fora da distribuição (possivelmente focando em espaços de saídas de alta dimensão).
Outras falhas estranhas. Outras falhas estranhas que acho que não recebem atenção suficiente, embora também não ache que funcionarão conforme estão escritas, são os Riscos da Otimização Aprendida de Hubinger et al. (a IA adquire um “objetivo interno”, um tanto parecido com o alinhamento enganoso) e a Parte I da história de fracasso da IA de Paul Christiano (o mundo se torna muito complicado e os sistemas de IA criam elaboradas aldeias Potemkin para os humanos).
A história de Paul Christiano, em particular, me deixou mais interessado em entender como o hackeamento da recompensa interage com a sofisticação do supervisor: por exemplo, com que rapidez as redes neurais enganam os humanos que têm 5 segundos para pensar, em vez de 2 ou 30 minutos? De maneira mais geral, quero entender como o hackeamento da recompensa depende quantitativamente da qualidade da supervisão e da capacidade do modelo (qualitativamente, esperamos maior qualidade → menos hackeamento e maior capacidade → mais hackeamento). Compreender essa relação quantitativa ajudaria a fundamentar a história de Paul, uma vez que ele imagina um mundo onde os humanos construíram sistemas extremamente sofisticados para supervisionar modelos de ML, mas os modelos de ML acabam se tornando ainda mais poderosos e manipulando o sinal de supervisão de qualquer maneira.
O que fazer com falhas emergentes estranhas
Ao pensar em como lidar com riscos emergentes, reflito frequentemente sobre o exemplo do urânio. Para contextualizar, uma bomba atômica é praticamente só um monte de urânio reunido – uma vez que você consegue o suficiente, a reação se torna autossustentável –, o que a torna um bom exemplo de Mais É Diferente.
A primeira reação nuclear (não uma bomba, mas uma pilha de urânio num estádio de futebol abandonado em Chicago) foi projetada por Enrico Fermi. A reação exigiu 12.400 libras de urânio metálico empilhadas com 57 camadas de altura. Se não fosse supervisionada, uma pilha de 57 camadas se consumiria em duas horas e mataria todos nas proximidades. Por outro lado, uma pilha de 56 camadas não faria nada.
Fermi tinha um bom conhecimento da física nuclear e compreendeu, a partir de um monitoramento cuidadoso e da teoria subjacente, que a pilha ultrapassaria o limiar crítico entre as camadas 56 e 57. Ele também sabia que as hastes de cádmio absorveriam nêutrons e inibiriam fortemente a reação. Essas hastes foram montadas e todo o aparato foi cuidadosamente controlado para ficar apenas ligeiramente supercrítico. Ele elevou a reação para meio watt por vários minutos antes de desligá-la novamente (veja The Making of the Atomic Bomb, p. 524).
Com a IA, atualmente nos falta tanto a compreensão conceitual de Fermi sobre os fatores de risco subjacentes quanto a sua capacidade de medi-los continuamente. Não temos nem uma barra de cádmio, nem uma medida da criticidade da reação. Mas acho que podemos chegar lá combinando esses estranhos experimentos mentais com experimentos empíricos cuidadosamente escolhidos, que serão o tema do próximo post.
Notas
1. Na realidade, as coisas são mais complicadas, pois θt é atualizado mesmo quando at é ótimo (devido ao ruído no processo de treinamento). No entanto, ignoraremos isso em prol do exemplo.
2. É claro que ainda há alguma mudança na distribuição, pois o agente pode observar se está sendo treinado ou implementado. Mas essa é uma mudança relativamente pequena e não intuitiva em comparação com o que é normalmente estudado.
3. É claro que a emergência não significa que podemos simplesmente prever o que quisermos; precisaríamos de alguma razão para esperar que essas capacidades específicas emergissem. O planejamento de longo prazo e a consciência ambiental são úteis para uma ampla variedade de tarefas, tornando provável que eles surjam ao treinar modelos poderosos numa distribuição diversificada de dados.
Tradução: Luan Marques
Link para o original