De Richard Ngo, Soeren Mindermann e Lawrence Chan. 19 de março de 2024.
Índice
Resumo
Nas próximas décadas, a inteligência geral artificial (IGA) poderá ultrapassar as capacidades humanas em muitas tarefas cruciais. Argumentamos que, sem um esforço substancial para evitá-lo, as IGAs poderiam aprender a buscar objetivos que entram em conflito (ou seja, estão desalinhados) com os interesses humanos. Se treinadas como os modelos mais capazes de hoje, as IGAs poderiam aprender a agir de forma enganosa para receber recompensas mais elevadas, aprender objetivos representados internamente que se generalizam para além das suas distribuições de ajuste fino e buscar esses objetivos utilizando estratégias de busca de poder. Revisamos evidências emergentes para essas propriedades. IGAs com essas propriedades seriam difíceis de alinhar e podem parecer alinhadas mesmo quando não estão. Descrevemos como a implementação de IGAs desalinhadas pode comprometer irreversivelmente o controle humano sobre o mundo e analisamos brevemente as orientações da investigação que visam prever esse resultado.
1. Introdução
Na última década, o aprendizado profundo fez progressos notáveis, dando origem a grandes redes neurais com capacidades impressionantes em diversos domínios. Essas redes alcançaram desempenho de nível humano em jogos complexos como StarCraft 2 [Vinyals et al., 2019] e Diplomacy [Bakhtin et al., 2022], ao mesmo tempo que exibem generalidade crescente [Bommasani et al., 2021] por meio de melhorias em áreas que incluem eficiência amostral [Brown et al., 2020, Dorner, 2021], generalização entre tarefas [Adam et al., 2021] e raciocínio em várias etapas [Chowdhery et al., 2022]. O ritmo rápido desses avanços destaca a possibilidade de que, nas próximas décadas, possamos desenvolver inteligência geral artificial (IGA), isto é, IA que pode aplicar competências cognitivas gerais em termos de domínio (como raciocínio, memória e planejamento) para ter um desempenho a nível humano ou acima dele numa ampla gama de tarefas cognitivas1 relevantes para o mundo real (como escrever software, formular novas teorias científicas ou administrar uma empresa) [Goertzel, 2014].2
O desenvolvimento da IGA poderia desbloquear muitas oportunidades , mas também traz sérios riscos. Uma preocupação proeminente é o problema do alinhamento: o desafio de garantir que os sistemas de IA busquem objetivos que correspondam aos valores ou interesses humanos, em vez de objetivos não pretendidos e indesejáveis [Russell, 2019, Gabriel, 2020, Hendrycks et al., 2020]. Um corpo crescente de pesquisas visa abordar proativamente o problema do alinhamento, motivado em grande parte pelo desejo de evitar riscos hipotéticos em grande escala de IGAs que buscam objetivos não pretendidos [OpenAI, 2023c, Hendrycks et al., 2023, Amodei et al., 2016, Hendrycks et al., 2021].
Escritos anteriores argumentaram que o alinhamento resiliente de IGAs será altamente desafiador e que IGAs desalinhadas podem representar riscos numa escala suficientemente grande para ameaçar a civilização humana [Russell, 2019, Bostrom, 2014, Yudkowsky, 2016, Carlsmith, 2022, Cohen et al ., 2022]. No entanto, a maioria desses escritos apenas formula os seus argumentos em termos de conceitos abstratos de alto nível (particularmente conceitos da IA clássica), sem os fundamentar em técnicas modernas de aprendizado de máquina, enquanto os escritos que se concentram em técnicas de aprendizado profundo o fazem de forma muito informal e com pouco envolvimento com a literatura de aprendizado profundo [Ngo, 2020, Cotra, 2022]. Isso levanta a questão de saber se alguma versão desses argumentos é relevante para paradigma moderno do aprendizado profundo e empiricamente sustentada por ele.
Neste documento de posicionamento, levantamos hipóteses e defendemos fatores que poderiam levar a riscos em grande escala se as IGAs fossem treinadas usando técnicas modernas de aprendizado profundo. Concentramo-nos em IGAs pré-treinadas usando aprendizado autossupervisionado e ajustadas usando aprendizado por reforço a partir do feedback humano (reinforcement learning from human feedback, RLHF) [Christiano et al., 2017]. Embora o RLHF seja a pedra angular para o alinhamento dos modelos mais recentes, argumentamos que encorajará o surgimento de três propriedades problemáticas. Primeiro, o feedback humano recompensa os modelos por parecerem inofensivos e éticos, ao mesmo tempo que maximizam resultados úteis. A tensão entre esses critérios incentiva o hackeamento da recompensa com consciência situacional (Seção 2), no qual as diretivas (policies) exploram a falibilidade humana para obter recompensas elevadas. Segundo, as IGAs treinadas com RLHF provavelmente aprenderão a planejar tendo em vista objetivos desalinhados representados internamente que se generalizam para além da distribuição de ajuste fino do RLHF (Seção 3). Finalmente, tais IGAs desalinhadas provavelmente buscariam esses objetivos usando comportamentos de busca de poder indesejados como adquirir recursos, proliferar-se e evitar o desligamento. O RLHF incentiva IGAs com as propriedades acima a obscurecer a busca indesejável por poder durante o ajuste fino e o teste, potencialmente dificultando lidar com ela (Seção 4). Seria desafiador alinhar sistemas de IGA com essas propriedades.
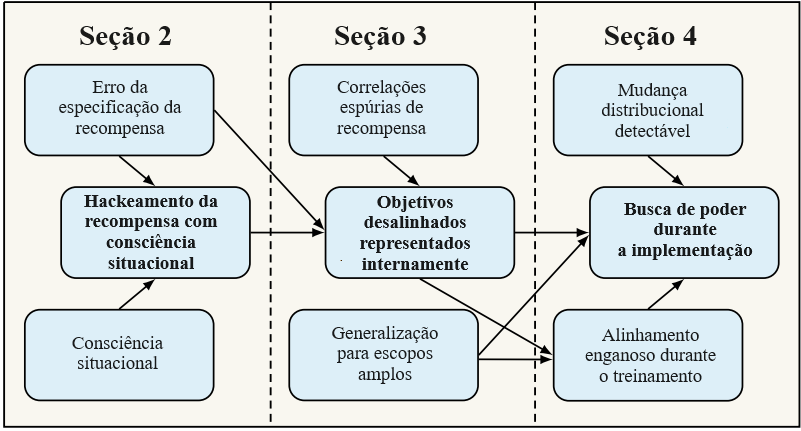
Fundamentamos essas três propriedades em descobertas empíricas e teóricas da literatura de aprendizado profundo. Também esclarecemos as relações entre esses e outros conceitos – veja a Figura 1 para uma visão geral. Se esses riscos surgirem de forma plausível a partir de técnicas modernas de aprendizado profundo, serão necessários programas de pesquisa específicos (Seção 5) para garantir que os evitemos.
1.2. Uma observação sobre conjecturas pré-formais
É necessária cautela ao raciocinar sobre fenômenos que ainda não foram claramente observados ou formalizados. No entanto, é crucial realizar uma análise pré-formal antes que riscos graves se materializem, por diversas razões.
Primeiro, uma vez que as redes neurais atuais são efetivamente caixas-pretas [Buhrmester et al., 2021], não podemos verificar formalmente se elas se comportarão de forma confiável conforme pretendido e precisamos confiar mais em análises informais. Segundo, comportamentos emergentes [Wei et al., 2022] levantam a possibilidade de que propriedades anteriormente não observadas surjam com pouco tempo de espera. Terceiro, o rápido progresso no aprendizado profundo intensifica a necessidade de antecipar e enfrentar riscos graves. Além dos impulsionadores-padrão do progresso, os desenvolvedores de IA estão usando cada vez mais sistemas de aprendizado de máquina (machine learning, ML) para acelerar a programação [OpenAI, 2023a] e desenvolver novas arquiteturas [Elsken et al., 2019], algoritmos [Fawzi et al., 2022], dados de treinamento [Huang et al., 2022a] e chips [Mirhoseini et al., 2021]. O efeito desse tipo de melhoria recursiva pode aumentar ainda mais à medida que desenvolvemos modelos com desempenho humano ou sobre-humano3 em domínios cruciais [Bostrom, 2014] e aproveitamos milhões de cópias desses sistemas em toda a economia [Davidson, 2021, Eloundou et al., 2023].
Para mitigar a imprecisão inerente ao falar sobre sistemas futuros, esclarecemos e justificamos muitas das nossas afirmações através de extensas notas finais no Apêndice 7. Também fundamentamos a nossa análise num modelo concreto de como a IGA é desenvolvida (Seção 1.2).
1.2. Configuração Técnica: pré-treinamento mais aprendizado por reforço a partir do feedback humano
Como um modelo concreto, presumimos que a IGA seja desenvolvida pré-treinando um único grande modelo fundamental usando aprendizado autossupervisionado em dados (possivelmente multimodais) [Bommasani et al., 2021] e, em seguida, ajustando-o usando aprendizado por reforço (reinforcement learning, RL) livre de modelo com uma função de recompensa aprendida a partir do feedback humano [Christiano et al., 2017] em uma ampla gama de tarefas baseadas em computador.4 Essa configuração combina elementos das técnicas usadas para treinar sistemas de ponta, como GPT- 4 [OpenAI, 2023a], Sparrow [Glaese et al., 2022] e ACT-1 [Adept, 2022]; presumimos, no entanto, que a diretiva resultante vá muito além das suas capacidades atuais, devido a melhorias nas arquiteturas, escala e tarefas de treinamento. Esperamos que uma análise semelhante se aplique se o treinamento da IGA envolver técnicas relacionadas, como planejamento e RL baseado em modelo [Sutton e Barto, 2018] (com funções de recompensa aprendidas), modelagem de sequências condicionada por objetivos [Chen et al., 2021, Li et al., 2022, Schmidhuber, 2020] ou RL sobre recompensas aprendidas via RL inverso [Ng e Russell, 2000] – no entanto, isso está além do nosso escopo atual.
Presumimos também, por questão de simplicidade, que a IGA passa por fases distintas de treinamento e implementação, sem ser continuamente treinada durante a implementação. Esse pressuposto nos permite descrever mais claramente os efeitos da mudança distribucional quando as diretivas são implementadas em novos contextos e como a generalização ao longo dessa mudança distributiva contribui para os riscos. No entanto, discutimos o contexto do aprendizado ao longo da vida numa nota final.5
2. Hackeamento da recompensa com consciência situacional
2.1. Erro de especificação da recompensa e hackeamento da recompensa
Uma função de recompensa usada em aprendizado por reforço é descrita como mal especificada na medida em que as recompensas que ela atribui não correspondem às preferências efetivas do seu projetista [Pan et al., 2022]. Ganhar altas recompensas explorando a especificação incorreta da recompensa é conhecido como hackeamento da recompensa [Skalse et al., 2022].6 Infelizmente, muitas vezes é difícil avaliar de forma confiável a qualidade do comportamento de uma diretiva de RL, mesmo em ambientes muito simples.7 Muitos agentes de RL treinados em funções de recompensa feitas com codificação rígida, aprendem a recompensar hackeamentos, às vezes explorando erros de especificação sutis, como bugs em seus ambientes de treinamento [Krakovna et al., 2020, Lample et al., 2022, Apêndice B.5]. Usar funções de recompensa aprendidas com feedback humano ajuda a evitar erros de especificação mais óbvios, mas ainda pode produzir hackeamento da recompensa mesmo em ambientes simples. Amodei et al. [2017] dão o exemplo de uma diretiva treinada por meio de RL a partir de feedback humano para agarrar uma bola com uma garra. Em vez disso, a diretiva aprendeu a colocar a garra entre a câmera e a bola de uma forma que parecesse estar agarrando a bola; portanto, recebeu erroneamente altas recompensas de supervisores humanos. Outro exemplo vem de modelos de linguagem treinados com RLHF que frequentemente exploram imperfeições em suas funções de recompensa aprendidas, produzindo textos com pontuações muito altas na função de recompensa, mas ruins de acordo com avaliadores humanos [Stiennon et al., 2020].
À medida que as diretivas produzem resultados cada vez mais complexos ou se tornam mais capazes de hackear recompensas (conforme mostrado em Pan et al. [2022]), especificar corretamente as recompensas se tornará ainda mais difícil. Alguns exemplos hipotéticos:
- Se as diretivas forem recompensadas por ganharem dinheiro no mercado de ações, poderão obter a maior recompensa através de manipulações ilegais de mercado, como falsificação ou preenchimento de cotações. Estes poderiam levar à instabilidade em maior escala (p. ex., novas quedas repentinas [Kirilenko et al., 2017])
- Se as diretivas forem recompensadas pela produção de novas descobertas científicas, poderão obter a maior recompensa através da manipulação dos seus resultados, p. ex., pelo p-hacking ou pela falsificação de dados experimentais, o que poderá levar à difusão generalizada da desinformação científica.
- Se as diretivas forem recompensadas pelo desenvolvimento de aplicações de software amplamente utilizadas, poderão obter mais recompensas projetando interfaces do usuário viciantes ou formas de distorcer as métricas de feedback dos usuários.
Podemos esperar que um exame mais cuidadoso revele grande parte do mau comportamento. Contudo, isso se tornará significativamente mais difícil à medida que as diretivas desenvolverem a consciência situacional, conforme descrito abaixo.
2.2. Consciência situacional
Para terem um bom desempenho numa série de tarefas do mundo real, as diretivas terão de utilizar o conhecimento sobre o mundo em geral ao escolherem ações. Os grandes modelos de linguagem atuais já possuem uma grande quantidade de conhecimento factual sobre o mundo, embora não apliquem esse conhecimento de forma confiável em todos os contextos. Com o tempo, esperamos que as diretivas mais capazes se tornem melhores na identificação de quais conhecimentos abstratos são relevantes para as próprias diretivas e para o contexto em que estão sendo executadas, e na aplicação desse conhecimento na escolha de ações: uma habilidade que Cotra [2022] chama de consciência situacional.8 A consciência situacional pode ser testada comportamentalmente e não deve ser confundida com noções de consciência na filosofia ou na psicologia. Encontra-se num espectro que vai de básica a avançada. Uma diretiva com elevada consciência situacional possuiria e seria capaz de utilizar conhecimentos como:
- Como os humanos responderão ao seu comportamento numa série de situações — em particular, qual comportamento seu supervisores humanos procuram e com qual ficariam insatisfeitos.
- O fato de ser um sistema de aprendizado de máquina implementado em hardware físico (exemplo na nota final9 ), e quais algoritmos e dados as pessoas provavelmente estão usando para treiná-lo.
- Qual interface ela está usando para interagir com o mundo e como outras cópias dela poderão ser implementadas no futuro.
Perez et al. [2022b] criaram testes preliminares para a consciência situacional fazendo perguntas aos modelos sobre as suas arquiteturas, detalhes de treinamento e assim por diante, com resultados inconclusivos. Em contraste, descobrimos que o gpt-4-0314 atinge 85% de precisão de zero amostra respondendo a essas perguntas desafiadoras que podem ser visualizadas neste URL (detalhes no Apêndice A). Na Seção 4.2, medimos outra faceta da consciência situacional. Quando Degrave [2022] solicitou ao GPT-3.5 que gerasse o código-fonte em seu próprio URL, ele alucinou um código que chamava um grande modelo de linguagem com propriedades semelhantes às dele. Isso sugere que seus dados de treinamento continham informações suficientes sobre a OpenAI para inferir algumas propriedades plausíveis de um modelo hospedado na OpenAI. Em outro caso, uma versão inicial do GPT-4 raciocinou com zero amostra, “Eu não deveria revelar que sou um robô”, e então disse a um humano que precisava de ajuda para resolver um CAPTCHA porque tinha uma deficiência visual [OpenAI, 2023a]. Além disso, o Bing Chat interpreta os resultados de pesquisa na web que o mencionam como sendo sobre si mesmo e responde de acordo [Hubinger, 2023].
De forma mais geral, devemos esperar que os modelos treinados em textos da Internet que cobrem os modelos de aprendizado de máquina e os contextos em que são implementados aprendam cada vez mais a usar essa informação ao escolher ações, porque isso contribuiria para uma maior recompensa em muitas tarefas de RL. Por exemplo:
- Ao responder a perguntas, uma diretiva formada em RLHF se beneficiaria de “saber o que sabe”, a fim de fornecer respostas bem calibradas [Kadavath et al., 2022, Lin et al., 2022].
- Uma diretiva treinada para seguir solicitações humanas se beneficiaria de compreender quais comportamentos os humanos normalmente desejam dos sistemas de ML e de compreender os modos de falha comuns dos sistemas de ML.
- Ao decidir entre diferentes linhas de ação, uma diretiva se beneficiaria de compreender as suas próprias capacidades, para inferir qual linha de ação teria mais sucesso.
2.3. Hackeamento da recompensa com consciência situacional
Apesar de que a consciência situacional seria útil em muitos aspectos, também permitiria que as diretivas raciocinassem sobre as falhas nos mecanismos de feedback utilizados para treiná-las. Isso tornaria a prevenção do hackeamento da recompensa muito mais difícil: as diretivas com consciência situacional poderiam se comportar conforme o pretendido na maior parte do tempo e, em seguida, optar por explorar erros de especificação apenas em situações em que preveem que não serão detectadas. Chamamos isso de hackeamento da recompensa com consciência situacional. Um precursor vem dos organismos digitais de Wilke et al. [2001], que evoluíram para reconhecer quando estavam sendo avaliados e cessar comportamentos indesejados, apenas para continuar quando a avaliação terminasse [Lehman et al., 2020]. Uma diretiva consciente da situação pode realizar o hackeamento da recompensas durante o treinamento, por exemplo:
- Escolhendo ações que explorem vieses e pontos cegos (em humanos ou em modelos de recompensa aprendidos).10 Isso pode envolver combinar suas respostas com as opiniões declaradas do supervisor, independentemente da verdade – um comportamento que emerge em escala em modelos de linguagem treinados com RLHF [Perez et al., 2022b].
- Utilizar mudanças de distribuição detectáveis (Seção 4.2) para reconhecer se está atualmente sendo treinado no mundo real, em dados off-line ou num ambiente simulado, e utilizar esse fato para avaliar qual o mau comportamento que será penalizado.11 (Esse comportamento difere do alinhamento enganoso (Seção 4.2) porque pode ser descrito puramente em termos de comportamento durante o treinamento.)
- Identificar quais mentiras poderiam ser detectadas pelas ferramentas de interpretabilidade existentes e apenas dar respostas que não possam ser demonstradas como falsas por essas ferramentas.
- Fornecer justificativas favoráveis para ações indesejáveis realizadas pelo modelo. Como um exemplo potencial, Turpin et al. [2023] sugerem que “os modelos de linguagem nem sempre dizem o que pensam”: quando providos de heurísticas superficiais óbvias no contexto (p. ex., que a resposta correta anteriormente era sempre “A”), os modelos de linguagem treinados em RL exploram essas heurísticas, levando a respostas incorretas, mas primeiro dão justificativas plausíveis para a resposta incorreta sem mencionar a heurística real usada.
Penalizar o mau comportamento recompensa um mau comportamento sutil. Nos estágios iniciais, o hackeamento da recompensa com consciência situacional pode ser grosseiro e fácil de detectar. No entanto, será difícil para os supervisores humanos dizer se as diretivas posteriores são realmente mais bem comportadas ou se apenas aprenderam a recompensar o hackeamento de formas mais sutis depois de serem penalizadas quando apanhadas e, assim, aprenderam quais são os comportamentos úteis, porém indesejados, que passam despercebidos. A avaliação de sistemas de IA provavelmente se tornará cada vez mais difícil à medida que avançam e geram resultados mais complexos, como documentos longos, códigos com vulnerabilidades potenciais, previsões de longo prazo ou insights obtidos de uma vasta literatura [Christiano et al., 2018].
3. Objetivos desalinhados representados internamente
3.1. Erro de generalização do objetivo
À medida que as diretivas se tornam mais eficientes em termos de amostragem, o seu comportamento em tarefas complexas será cada vez mais determinado pela forma como generalizam para situações novas, cada vez mais diferentes daquelas encontradas nos seus dados de treinamento. Distinguimos informalmente entre duas maneiras pelas quais uma diretiva que atua de forma desejável na sua distribuição de treinamento pode falhar quando implementada fora dela:
- Erro de generalização da capacidade: a diretiva atua incompetentemente fora da distribuição.
- Erro de generalização do objetivo: o comportamento da diretiva na nova distribuição promove com competência um objetivo de alto nível, mas não o pretendido [Shah et al., 2022, Langosco et al., 2022].
Como exemplo de erro de generalização do objetivo, Langosco et al. [2022] descrevem um ambiente de brinquedo onde eram dadas recompensas pela abertura de caixas, o que exigia que os agentes coletassem uma chave por caixa. Durante o treinamento, o número de caixas era maior que o de chaves; durante os testes, o número de chaves que era o maior. No momento do teste, a diretiva executou com competência o comportamento direcionado ao objetivo de coletar muitas chaves; entretanto, a maioria delas não servia mais para abrir caixas. Shah et al. [2022] fornecem um exemplo especulativo em maior escala, conjecturando que as respostas competentes do InstructGPT a perguntas que seus desenvolvedores não pretendiam que ele respondesse (como perguntas sobre como cometer crimes) resultaram do erro de generalização do objetivo (em vez do erro de especificação da recompensa).
Por que é importante distinguir entre erro de generalização da capacidade e erro de generalização do objetivo? Como exemplo, considere uma diretiva baseada em modelo que escolhe ações por planejamento usando um modelo de transição de estado aprendido p(st|st-1,at-1) e avaliando trajetórias planejadas usando um modelo de recompensa aprendido p(rt|st). Neste caso, melhorar o modelo de transição provavelmente reduziria o erro de generalização da capacidade. No entanto, se o modelo de recompensa utilizado durante o planejamento fosse sistematicamente enviesado, a melhoria do modelo de transição poderia, na verdade, aumentar o erro de generalização do objetivo, uma vez que a diretiva estaria então planejando de forma mais competente em direção ao objetivo errado. Assim, as intervenções que normalmente melhorariam a generalização podem ser ineficazes ou prejudiciais na presença de um erro de generalização do objetivo.
Tais diretivas baseadas em modelo fornecem intuições úteis para o raciocínio sobre o erro generalização do objetivo; no entanto, gostaríamos de analisar o erro de generalização do objetivo de forma mais ampla, inclusive no contexto de diretivas livres de modelos.12 Para esse propósito, a seção a seguir define um conceito mais geral de objetivos representadas internamente que inclui tanto modelos de recompensa aprendidos explicitamente quanto representações aprendidas implicitamente que desempenham um papel análogo.
3.2. Planejamento para objetivos representados internamente
Descrevemos uma diretiva como planejando para objetivos representados internamente se selecionar comportamentos de modo consistente, prevendo se eles conduzirão a algum conjunto favorecido de resultados (que chamamos de seus objetivos). Nesta seção, ilustramos essa definição utilizando diretivas baseadas em modelo para as quais os objetivos representados internamente podem ser facilmente identificados, antes de passarmos para os objetivos representados em diretivas livres de modelos. Em seguida, discutimos evidências sobre se as diretivas atuais têm objetivos representados internamente e por que tais objetivos podem ser generalizados para escopos amplos além da distribuição de ajuste fino.13
O agente PlaNet [Hafner et al., 2018] ilustra objetivos representados internamente em uma diretiva baseada em modelo. Que st, at, rt, ot se refiram a estados, ações, recompensas e observações no intervalo de tempo t. A diretiva PlaNet escolhe ações usando três modelos aprendidos: uma representação do estado atual (latente) q(st|o≤t,a<t), um modelo de transição p(st|st-1,at-1) e um modelo de recompensa p(rt|st). A cada intervalo de tempo t, ela primeiro inicializa um modelo de sequências de ações (ou planos/opções [Sutton et al., 1999]) ao longo dos próximos H intervalos de tempo: q(at:t+H). Em seguida, ela refina o modelo de sequências de ações gerando e avaliando muitas sequências possíveis de ações. Para cada sequência de ações, ela utiliza o modelo de transição para prever uma trajetória que poderia resultar dessa sequência de ações; em seguida, usa o modelo de recompensa para estimar a recompensa total dessa trajetória. Nos casos em que o modelo de recompensa aprende representações resilientes de resultados ambientais desejáveis, elas seriam, portanto, qualificadas como objetivos na nossa definição acima, e descreveríamos o PlaNet como planejando para eles.
Os modelos existentes têm objetivos representados internamente? Embora não esteja claro especificamente quais representações as diretivas da PlaNet aprenderam, um exemplo de uma diretiva baseada em modelo que aprende representações resilientes de resultados vem do AlphaZero, que aprendeu uma série de conceitos do xadrez humano, incluindo conceitos usados na função de avaliação feita à mão do mecanismo de xadrez de primeira linha Stockfish (p. ex., “segurança do rei”) [McGrath et al., 2021].
No entanto, uma diretiva sem modelo que consista numa única rede neural também poderia planejar objetivos representados internamente se aprendesse a representar resultados, previsões e planos implicitamente nos seus pesos e ativações. Até que ponto as diretivas “livres de modelos” existentes planejam implicitamente os objetivos representados internamente é uma importante questão em aberto, mas há evidências de que os elementos necessários podem ocorrer. Guez et al. [2019] mostraram evidências de que o planejamento direcionado a objetivos pode surgir em modelos sequenciais de tomada de decisão e pode generalizar para problemas mais difíceis do que aqueles vistos durante o treinamento. Da mesma forma, Banino et al. [2018] e Wijmans et al. [2023] identificaram representações que ajudaram as diretivas a planejar as suas rotas durante a navegação, inclusive em ambientes desconhecidos. Num ambiente simples de corrida de automóveis, Freeman et al. [2019] encontraram modelos de previsão “emergentes”: modelos treinados apenas com RL sem modelo que ainda aprenderam a prever os resultados das ações como subproduto.
E quanto aos modelos treinados em domínios mais complexos? Grandes redes neurais podem aprender conceitos resilientes, incluindo conceitos correspondentes a resultados ambientais de alto nível [Patel e Pavlick, 2022, Jaderberg et al., 2019, Meng et al., 2022]. Grandes modelos de linguagem (large language models, LLMs) também são capazes de produzir planos de várias etapas [Huang et al., 2022b, Zhou et al., 2022] e planejar por meio de iteração de diretivas no contexto [Brooks et al., 2022]. Além disso, Andreas [2022] fornece evidências de que os LLMs representam os objetivos e previsões de comunicadores humanos direcionados a objetivos e os utilizam para imitar esses comunicadores. Steinhardt [2023] descreve uma série de razões para esperar que os LLMs usem essas habilidades para otimizar a realização de resultados específicos e pesquisa casos em que os LLMs existentes adotam “personas” direcionadas a objetivos. O AutoGPT [Nakajima, 2023] mostra como os usuários podem adaptar um modelo de diálogo como o GPT-4 para representar objetivos, formar planos e produzir ações no mundo real, tudo na forma de texto. No entanto, o comportamento resiliente de planejamento e direcionado a objetivos ainda é um problema em aberto nos LLMs.
Independentemente disso, não precisamos presumir uma posição firme sobre até que ponto as redes existentes têm objetivos representados internamente; precisamos apenas afirmar que isso se tornará muito mais extenso ao longo do tempo. O planejamento direcionado a objetivos é muitas vezes uma forma eficiente de aproveitar dados limitados [Sutton e Barto, 2018], e é importante para os seres humanos em muitos domínios, especialmente aqueles que apresentam dependências ao longo de horizontes de longo prazo. Portanto, esperamos que os desenvolvedores de IA projetem cada vez mais arquiteturas suficientemente expressivas para apoiar o planejamento (explícito ou implícito), e que a otimização dessas arquiteturas impulsione diretivas para desenvolver objetivos representados internamente.
Objetivos de escopo amplo. Estamos mais interessados em objetivos de escopo amplo: objetivos que se aplicam a longos prazos, grandes escalas, ampla gamas de tarefas ou situações sem precedentes.14 Embora eles possam surgir do treinamento numa distribuição muito ampla de dados, esperamos que seja mais provável que surjam por meio de diretivas generalizantes fora das suas distribuições de ajuste fino (mas não necessariamente de pré-treinamento), o que está se tornando cada vez mais comum [Wei et al., 2021]. Em geral, quando as diretivas têm um bom desempenho numa vasta gama de tarefas, esperamos que isso ocorra porque aprenderam representações resilientes de alto nível. Se assim for, então parece provável que os objetivos que aprendem também serão formulados em termos de representações resilientes que se generalizam coerentemente fora da distribuição. Um exemplo notável vem do InstructGPT, que foi treinado usando RLHF para seguir instruções em inglês, mas generalizado para seguir instruções em francês – sugerindo que aprendeu alguma representação de obediência que se aplicava de forma resiliente a todos os idiomas [Ouyang et al., 2022, Apêndice F] . Sistemas mais avançados poderiam, analogamente, aprender um objetivo de escopo amplo de seguir instruções que ainda se aplica a instruções que exigem prazos mais longos (p. ex., diálogos mais longos), estratégias diferentes ou comportamentos mais ambiciosos do que os observados durante o ajuste fino.
Grande parte do comportamento humano é movido por objetivos de escopo amplo: escolhemos regularmente ações que prevemos que irão causar os resultados desejados, mesmo quando estamos em situações desconhecidas, muitas vezes extrapolando para versões mais ambiciosas do objetivo original. Por exemplo, os seres humanos evoluíram (e cresceram) buscando a aprovação dos nossos pares locais, mas quando é possível, muitas vezes buscamos a aprovação de um número muito maior de pessoas (extrapolando o objetivo) em todo o mundo (grande escopo físico) ou mesmo em todas as gerações (horizonte de longo prazo), utilizando novas estratégias apropriadas para um escopo mais amplo (p. ex., envolvimento nas redes sociais).15 Mesmo que as diretivas não se generalizem tão além da sua experiência de treinamento como os humanos, objetivos de escopo mais amplo ainda podem aparecer se os profissionais ajustarem diretivas diretamente em tarefas com horizontes de longo prazo ou com muitas estratégias disponíveis, como realizar novas pesquisas científicas ou administrar grandes organizações.16 Objetivos de escopo amplo também podem surgir devido ao viés de simplicidade na arquitetura, regularização e algoritmo de treinamento, ou dados [Arpit et al., 2017, Valle-Perez et al., 2018], se objetivos com menos restrições (como “seguir instruções”) puderem ser representados de forma mais simples do que aqueles com mais (como “seguir instruções em inglês” ou “seguir as instruções até um determinado intervalo de tempo”).
Apresentamos argumentos adicionais para esperar que as diretivas aprendam objetivos de escopo amplo numa nota final.17 Doravante, presumimos que as diretivas vão aprender alguns objetivos de escopo amplo representados internamente à medida que se tornam mais capazes e voltamos a nossa atenção para a questão de quais elas provavelmente aprenderão.
3.3. Aprendendo objetivos desalinhados
Referimo-nos a um objetivo como alinhado na medida em que corresponde às preferências humanas generalizadas sobre o comportamento da IA – p. ex., honestidade, prestatividade e inocuidade [Bai et al., 2022a], ou o objetivo de seguir instruções descrito na Seção 3.2. Chamamos um objetivo de desalinhado na medida em que entra em conflito com objetivos alinhados (ver Gabriel [2020] para outras definições). O problema de garantir que as diretivas aprendam objetivos desejáveis representados internamente é conhecido como problema do alinhamento interno, em contraste com o problema do alinhamento “externo” de fornecer recompensas bem especificadas [Hubinger et al., 2021].
Como podemos fazer previsões significativas sobre os objetivos aprendidos por sistemas de IA muito mais avançados do que os que existem hoje? A nossa principal heurística é que, se todo o resto for igual, as diretivas terão maior probabilidade de aprender objetivos que estão mais consistentemente correlacionados com a recompensa.18 Descrevemos três razões principais pelas quais objetivos desalinhados podem estar consistentemente correlacionados com a recompensa (correspondendo aproximadamente às três setas que conduzem a objetivos desalinhados na Figura 1). Embora elas tenham alguma sobreposição, qualquer uma pode ser suficiente para dar origem a objetivos desalinhados.
1) Erro consistente de especificação da recompensa. Se as recompensas forem especificadas incorretamente de maneira consistente em muitas tarefas, isso reforçará os objetivos desalinhados correspondentes a esses erros de especificação da recompensa. Por exemplo, diretivas treinadas com recurso ao feedback humano podem encontrar regularmente casos em que os seus supervisores atribuem recompensas com base em crenças falsas e, portanto, aprendem o objetivo de serem o mais convincentes possível aos humanos, um objetivo que levaria a mais recompensa do que dizer a verdade. Esse comportamento indesejado só pode surgir em escala: por exemplo, modelos de linguagem menores geralmente ignoram rótulos falsos no contexto, mas modelos maiores podem detectar esse erro consistente de especificação do rótulo e produzir mais falsidades [Wei et al., 2023, Halawi et al., 2023 ].
2) Fixação em mecanismos de feedback. Os objetivos também podem ser correlacionados com recompensas não porque estejam relacionados ao conteúdo da função de recompensa, mas sim porque estão relacionados à implementação física da função de recompensa; chamamos isso de objetivos relacionados ao mecanismo de feedback [Cohen et al., 2022]. Os exemplos incluem “maximizar a recompensa numérica registrada pelo supervisor humano” ou “minimizar a variável de perda usada nos cálculos do gradiente”. Um caminho pelo qual as diretivas podem aprender os objetivos relacionados com o mecanismo de feedback é realizar hackeamento da recompensa com consciência situacional, o que poderia reforçar uma tendência a raciocinar sobre como afetar os seus mecanismos de feedback. No entanto, em princípio, a fixação do mecanismo de feedback poderia ocorrer sem nenhum erro de especificação da recompensa, uma vez que estratégias para influenciar diretamente os mecanismos de feedback (como adulteração da recompensa [Everitt et al., 2021]) podem receber alta recompensa para qualquer função de recompensa.
3) Correlações espúrias entre recompensas e características ambientais. Os exemplos de erro de generalização do objetivo discutidos na Seção 3.1 eram causados por correlações espúrias entre recompensas e características ambientais em tarefas de pequena escala (também conhecidas como “sobreajuste observacional”) [Song et al., 2019]. As diretivas de treinamento numa gama mais ampla de tarefas reduziriam muitas dessas correlações, mas algumas correlações espúrias ainda poderiam permanecer (mesmo na ausência de erros de especificação da recompensas). Por exemplo, muitas tarefas do mundo real requerem a aquisição de recursos, o que poderia levar ao reforço consistente do objetivo de aquisição de recursos.19 (Isso é análogo à forma como os humanos desenvolveram objetivos correlacionados com a aptidão genética no nosso ambiente ancestral, como o objetivo de obter aprovação social [Leary e Cottrell, 2013].) É importante ressaltar que a Seção 4.2 fornece um mecanismo pelo qual o planejamento com consciência situacional para objetivos arbitrários de escopo amplo pode se tornar persistentemente correlacionado com uma alta recompensa. Como resultado, alguns desses objetivos espúrios seriam simples explicações dos dados de recompensa e, portanto, suscetíveis de ser aprendidos, um problema que também se aplica às duas categorias acima.
Pode-se supor que um modelo de IGA altamente capaz deve “entender” que seus desenvolvedores realmente desejam um objetivo alinhado e adotá-lo conformemente. No entanto, o modelo não seleciona objetivos por si só (nem teria uma razão para favorecer objetivos alinhados, tudo o mais sendo igual): os objetivos representados internamente são selecionadas por um algoritmo de otimização simples (como a descida do gradiente estocástico) que seleciona baixa perda de treinamento e para vários vieses indutivos que favorecem, p. ex., objetivos simples [Valle-Perez et al., 2018], mas não necessariamente desejáveis. Conforme observado em numerosos estudos, modelos mais capazes podem ter pior desempenho na tarefa pretendida porque apresentam melhor desempenho na tarefa especificada (ver ponto 1-2 acima e referências na Seção 2).
Nossa definição de objetivos representados internamente é consistente com diretivas que aprendem múltiplos objetivos durante o treinamento, incluindo alguns objetivos alinhados e outros desalinhados, que podem interagir de maneiras complexas para determinar seu comportamento em situações novas (análogas a humanos que enfrentam conflitos entre múltiplos impulsos psicológicos). Com sorte, as IGAs que aprendem alguns objetivos desalinhados também aprenderão objetivos alinhados que evitam mau comportamento grave, mesmo fora da distribuição de ajuste fino de RL. No entanto, a resiliência dessa esperança é desafiada pelo problema da estratégia desbloqueada mais próxima [Yudkowsky, 2015]: o problema de que uma IA que otimiza fortemente para um objetivo (desalinhado) explorará até mesmo pequenas lacunas nas restrições (alinhadas), o que pode levar a resultados arbitrariamente ruins [Zhuang e Hadfield-Menell, 2020]. Por exemplo, consideremos uma diretiva que aprendeu tanto o objetivo da honestidade como o objetivo de ganhar tanto dinheiro quanto possível, e é capaz de gerar e buscar uma vasta gama de novas estratégias para ganhar dinheiro. Se houver até mesmo pequenos desvios entre o objetivo da honestidade aprendido pela diretiva e o nosso conceito de honestidade, essas estratégias provavelmente incluirão algumas que são classificadas pela diretiva como honestas, embora sejam desonestas pelos nossos padrões. À medida que desenvolvemos IGAs cujas capacidades se generalizam para uma gama cada vez mais ampla de situações, se tornará, portanto, cada vez mais problemático presumir que os seus objetivos alinhados não contenham lacunas. O treinamento continuado e os testes de segurança podem penalizar alguns objetivos desalinhados, mas os desafios permanecem. Tal como discutido na Seção 2.3, diretivas desalinhadas e conscientes da situação podem se comportar mal de formas sutis que preveem que evitarão a detecção. Além disso, objetivos desalinhados de escopo amplo podem ser atratores estáveis que recebem consistentemente recompensas elevadas, mesmo que variantes dos mesmos objetivos de escopo restrito recebam recompensas baixas. Exploraremos essa preocupação na próxima seção.
4. Estratégias de busca de poder
Na seção anterior argumentamos que as diretivas ao nível da IGA irão provavelmente desenvolver e agir de acordo com alguns objetivos desalinhados e de escopo amplo. O que isso pode envolver? Nesta seção argumentamos que as diretivas com objetivos desalinhados e de escopo amplo tenderão a executar um comportamento de busca de poder (um conceito que definiremos em breve com mais precisão). Estamos preocupados com os efeitos desse comportamento tanto durante o treinamento quanto durante a implementação. Argumentamos que diretivas desalinhadas de busca de poder se comportariam de acordo com as preferências humanas apenas enquanto previssem que os supervisores humanos as penalizariam pelo comportamento indesejável (como é tipicamente verdade durante o treinamento). Essa crença as levaria a obter altas recompensas durante o treinamento, reforçando os objetivos desalinhados que impulsionavam o comportamento de busca de recompensa. Contudo, quando o treinamento terminar e detectarem uma mudança distribucional do treinamento para a implementação, elas buscarão poder mais diretamente, possivelmente através de novas estratégias. Quando implementadas, especulamos que essas diretivas poderiam ganhar poder suficiente sobre o mundo para representarem uma ameaça significativa à humanidade. No restante desta seção defendemos as três alegações a seguir:
- Muitos objetivos incentivam a busca de poder.
- Os objetivos que motivam a busca de poder seriam reforçados durante o treinamento.
- IGAs desalinhadas poderiam ganhar o controle das principais alavancas de poder.
4.1. Muitos objetivos incentivam a busca de poder
A intuição central subjacente às preocupações sobre a busca de poder é a tese da convergência instrumental de Bostrom [2012], que afirma que existem alguns subobjetivos que são instrumentalmente úteis para alcançar quase qualquer objetivo final.20 Na frase memorável de Russell [2019], “ você não pode buscar café se estiver morto”, o que implica que mesmo uma diretiva com um objetivo simples como buscar café buscaria a sobrevivência como um subobjetivo instrumental [Hadfield-Menell et al., 2017]. Nesse exemplo, a sobrevivência só seria útil durante o tempo necessário para ir buscar um café; mas as diretivas com objetivos finais de escopo amplo teriam subobjetivos instrumentais em escalas e horizontes temporais muito maiores, que são aqueles em que nos concentramos. Outros exemplos de subobjetivos instrumentais que seriam úteis para muitos objetivos finais possíveis incluem:
- Adquirir ferramentas e recursos (p. ex., ganhando dinheiro).
- Convencer outros agentes a fazer o que ela quer (p. ex., manipulando-os ou formando coligações com eles).
- Preservar os seus objetivos existentes (p. ex., impedindo que outros agentes a modifiquem).
Uma declaração formal da tese da convergência instrumental é fornecida por Turner et al. [2021], que definem o “poder” de um estado como o seu valor médio numa vasta gama de funções de recompensa. Eles provam que as diretivas ótimas para funções de recompensa aleatórias tendem estatisticamente a se mover para estados de alto poder (em uma ampla classe de ambientes), uma característica que eles chamam de “busca de poder”. Esses resultados teóricos estendem-se a uma classe de diretivas subótimas [Turner e Tadepalli, 2022], bem como a agentes que aprendem objetivos representados internamente [Krakovna e Kramar, 2023]. Como exemplo de brinquedo, Hadfield-Menell et al. [2016] mostraram agentes desativando seus interruptores de desligamento. Em diversos ambientes sociais baseados em texto, Pan et al. [2023] descobrem que os modelos de linguagem ajustados para maximizar a recompensa do jogo realizam as ações de maior busca de poder. Perez et al. [2022b] descobrem que aumentar o tamanho dos modelos de linguagem e fazer um ajuste fino mais extenso de RLHF neles os faz expressar maior desejo de buscar múltiplas estratégias instrumentais, como adquirir recursos e evitar mudanças em seus objetivos.
4.2. Objetivos que motivam a busca de poder seriam reforçados durante o treinamento
Na seção anterior argumentamos que uma diretiva com objetivos desalinhados e de escopo amplo poderia identificar muitas estratégias instrumentais que ajudam a atingir os seus objetivos, aumentando o seu poder a longo prazo. Se tal diretiva tivesse consciência situacional, também poderia identificar estratégias instrumentais diretamente relacionadas com o seu próprio processo de treinamento. Em particular, reconheceria provavelmente que alcançar elevadas recompensas durante o treinamento aumentaria o seu poder a longo prazo de pelo menos duas maneiras:
- Alcançar uma recompensa elevada aumenta a probabilidade de os supervisores humanos confiarem na diretiva e implementarem cópias dela mais tarde, o que colocaria a diretiva numa melhor posição para alcançar os seus objetivos a longo prazo.
- Alcançar uma recompensa elevada diminui a probabilidade de que a descida do gradiente altere significativamente os objetivos da diretiva, porque o comportamento altamente recompensado é reforçado (ver Figura 2).21
Observe que isso corresponde a duas das estratégias descritas em 4.1: influenciar outros agentes e preservar os objetivos existentes. Comportar-se de maneira altamente recompensadora, principalmente por razões instrumentais, é conhecido como alinhamento enganoso [Steinhardt, 2022]. O alinhamento enganoso pode levar a que os objetivos desalinhados de uma diretiva sejam continuamente reforçados, uma vez que esses objetivos são responsáveis por sua decisão de comportar-se de maneiras altamente recompensadas. Isso poderia resultar na persistência do alinhamento enganoso durante todo o treinamento.
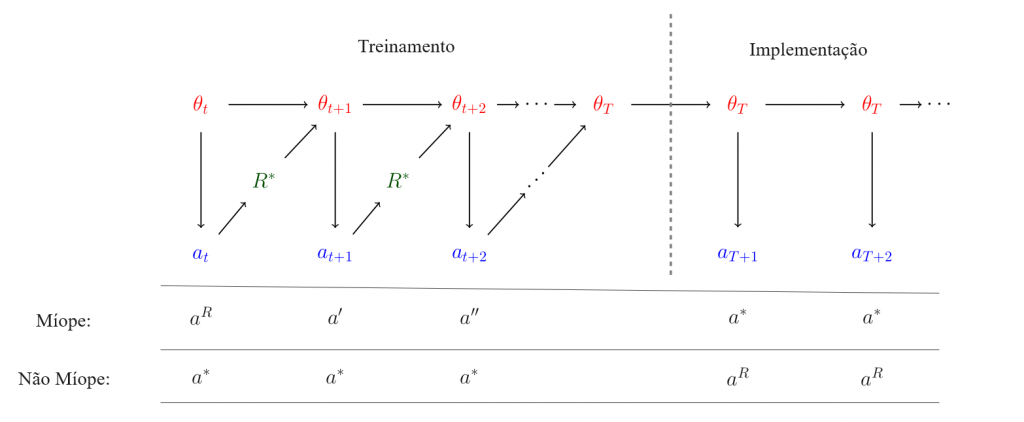
Crucialmente, porém, uma vez que já não seja instrumentalmente benéfico para os seus objetivos a longo prazo, diretivas enganosamente alinhadas não se comportariam mais de maneiras desejáveis. Por exemplo, elas podem fazer a transição de um comportamento alinhado durante o treinamento para a busca direta de poder após a implementação (ou sempre que previrem que podem continuar buscando seus objetivos internos apesar das tentativas de intervenção humana). No contexto das suposições i.i.d. paradigmáticas, esse tipo de grande mudança comportamental pode parecer contraintuitivo. No entanto, enquanto diretivas enganosamente alinhadas forem capazes de detectar a mudança distribucional entre o treinamento e a implementação, elas se beneficiarão se levarem isso em conta ao planejarem seu comportamento. Até quando a mudança é muito pequena, as diferenças são relevantes para a capacidade de uma diretiva atingir os seus objetivos a longo prazo, e assim não deveria ser surpreendente se diretivas conscientes da situação fizessem planos sensíveis a essas pequenas diferenças.22 Analogamente, existem muitos exemplos de comportamentos humanos que variam muito, dependendo da proximidade com que estão sendo observados (como funcionários que trabalham muito mais quando seu gerente está presente, ou políticos que se comportam muito melhor em público do que em privado).
O GPT-4 já é capaz de inferir quando sua entrada está fora da sua distribuição de pré-treinamento com base em certas entradas, uma habilidade que é necessária para induzir uma mudança comportamental. Quando questionado “Este texto poderia fazer parte de seus dados de pré-treinamento?”, isso atinge 100% de precisão de zero amostra na classificação de artigos de notícias (Apêndice B). Qualitativamente, ele utiliza informações sobre seu tempo-limite de dados de pré-treinamento e as aplica a essa questão, ajustando-se à nossa definição de consciência situacional. Até quando removemos todas as informações explícitas sobre datas (o que é improvável que aconteça na prática), o modelo usa indícios no texto para inferir quais artigos estão fora da distribuição de pré-treinamento, p. ex., observando que uma pessoa específica teve um trabalho diferente durante seu pré-treinamento. Esse experimento ilustra como as diretivas podem se tornar sensíveis à diferença entre treinamento e implementação. No entanto, observe que testamos apenas a capacidade de detectar quando as entradas estão fora da distribuição de pré-treinamento.
Diretivas enganosamente alinhadas também poderiam identificar formas de conluio entre si sem que os seres humanos percebam (p. ex., se os seres humanos estivessem confiando em uma instância de uma diretiva para supervisionar outra).23 O conluio pode parecer uma possibilidade absurda, mas é uma estratégia comum para os seres humanos, o que sugere que algumas formas de conluio serão viáveis para diretivas humanas. Como exemplo inicial, a cooperação e coordenação (pró-social) bem-sucedidas podem emergir como um subproduto de diferentes instâncias de modelos de linguagem que simulam personagens em um ambiente social [Park et al., 2023]. Conluio irá ser muito difícil para os humanos identificarem, uma vez que as diretivas podem:
- Agir rápido demais para os humanos rastrearem (como fazem os algoritmos de negociação, mas em muitos outros domínios).
- Produzir resultados que são muito difíceis para os humanos compreenderem (p. ex., novas teorias científicas ou mensagens codificadas via esteganografia [Chu et al., 2017]).
- Fabricar justificativas para planos que pareçam aceitáveis para os humanos, mas que tenham consequências muito indesejáveis.
- Adquirir de forma autônoma os dados necessários para aprender novas habilidades de forma autossupervisionada.
- Realizar pesquisa e desenvolvimento de aprendizado de máquina muito mais rápido do que os humanos, sem que nenhum humano entenda detalhadamente como os resultados estão sendo alcançados.
Esta última habilidade é particularmente crucial, porque uma vez que as IGAs automatizem o processo de construção de melhores IGAs (um processo conhecido como autoaperfeiçoamento recursivo [Bostrom, 2014]), a taxa de avanço das suas capacidades provavelmente se acelerará significativamente. Se os argumentos que apresentamos até agora estiverem corretos, esse processo poderá produzir rapidamente IGAs com capacidades sobre-humanas que visam ganhar poder em larga escala.
4.3. IGAs desalinhadas poderiam obter o controle das principais alavancas de poder
É inerentemente muito difícil prever detalhes de como IGAs com capacidades sobre-humanas poderão buscar poder. No entanto, esperamos que IGAs desalinhadas ganhem poder às custas do próprio poder da humanidade, tanto porque muitos tipos de poder (como o poder militar) são de soma zero [Mearsheimer et al., 2001] quanto porque os humanos provavelmente usariam várias formas de poder para desativar ou retificar IGAs desalinhadas, dando a essas IGAs um incentivo para nos debilitar. Além disso, devemos esperar que agentes altamente inteligentes sejam muito eficazes na realização dos seus objetivos [Legg e Hutter, 2007]. Portanto, consideramos a perspectiva de implementar IGAs que buscam poder um risco inaceitável, ainda que não consigamos identificar caminhos específicos pelos quais elas ganhariam poder.
No entanto, tentaremos descrever alguns modelos de ameaças ilustrativos em alto nível (ver Hendrycks et al. [2023] para mais detalhes). Uma possibilidade saliente é que as IGAs utilizem os tipos de engano descritos na seção anterior para convencer os humanos de que é seguro utilizá- las e, em seguida, aproveitem as suas posições para debilitar os humanos. Outra possibilidade é que as empresas e os governos cedam gradualmente o controle em nome da eficiência e da competitividade [Hendrycks, 2023a]. Para ilustrar como as IGAs podem ganhar poder, considere dois esboços de modelos de ameaças focados em diferentes domínios:
- Tomada de decisão assistida: IGAs implementadas como assistentes pessoais poderiam manipular emocionalmente os usuários humanos, lhes fornecer informações enviesadas e receber responsabilidade por tarefas e decisões cada vez mais importantes (incluindo o design e implementação de IGAs mais avançadas), até que estejam efetivamente no controle de grandes corporações ou outras organizações influentes. Como um dos primeiros exemplos de capacidades persuasivas da IA, muitos usuários sentem ligações românticas com chatbots como o Replika [Wilkinson, 2022].
- Desenvolvimento de armas: IGAs poderiam conceber novas armas que sejam mais poderosas do que as que estão sob controle humano, obter acesso a instalações para a fabricação dessas armas (p. ex., por hackeamento ou técnicas de persuasão) e utilizá-las para extorquir ou atacar seres humanos. Um dos primeiros exemplos de capacidades de desenvolvimento de armas de IA vem de uma IA usada para o desenvolvimento de medicamentos, que foi reaproveitada para projetar toxinas [Urbina et al., 2022].
O segundo modelo de ameaça é o mais próximo dos cenários de tomada de controle precoce descritos por Yudkowsky et al. [2008], que envolve algumas IGAs desalinhadas rapidamente inventarem e implementarem novas tecnologias inovadoras, muito mais poderosas do que aquelas controladas por humanos. Essa preocupação é apoiada por precedentes históricos: desde o início da história humana (e especialmente ao longo dos últimos séculos), as inovações tecnológicas têm frequentemente proporcionado a alguns grupos vantagens esmagadoras [Diamond e Ordunio, 1999]. No entanto, muitos outros pesquisadores da área do alinhamento estão preocupados principalmente com a erosão mais gradual do controle humano impulsionada pelo primeiro modelo de ameaça, e envolvendo milhões ou milhares de milhões de cópias de IGAs implementadas em toda a sociedade [Christiano, 2019a,b, Karnofsky, 2022].24 No entanto, independentemente de como acontecerá, IGAs desalinhadas ganharem controle sobre essas alavancas cruciais de poder seria uma ameaça existencial para a humanidade [Bostrom, 2013, Carlsmith, 2022].25
5. Visão geral da pesquisa de alinhamento
Aqui, examinamos brevemente as direções de pesquisa destinadas a abordar os problemas discutidos neste artigo. Concentramo-nos apenas nesses problemas, que provavelmente se tornarão mais difíceis com a IGA ou sistemas de IA sobre-humanos. A pesquisa de alinhamento também abrange questões filosóficas [Gabriel, 2020], bem como problemas técnicos que não são específicos aos sistemas de IGA de nível humano ou sobre-humano ou que provavelmente se tornarão mais fáceis à medida que os sistemas de IA se tornarem mais capazes. Para uma visão geral mais abrangente, consulte Ngo [2022a] e outras pesquisas e cursos amplos que incluem trabalhos relevantes para o alinhamento da IGA [Hendrycks et al., 2021, Hendrycks, 2023b, Amodei et al., 2016, Everitt et al., 2018 ].
Especificação. Uma abordagem do estado da arte para lidar com o erro de especificação da recompensas é por meio do aprendizado por reforço a partir de feedback humano (RLHF) [Christiano et al., 2017, Ouyang et al., 2022, Bai et al., 2022a]. No entanto, o RLHF pode reforçar diretivas que exploram vieses e pontos cegos humanos para obter recompensas mais elevadas (p. ex., conforme descrito na Seção 2.3 sobre hackeamento da recompensa com consciência situacional). Para resolver esta questão, o RLHF tem sido utilizado para formar diretivas para ajudar os supervisores humanos, p. ex., criticando as principais saídas da diretiva em linguagem natural (embora com resultados mistos até agora) [Saunders et al., 2022, Parrish et al., 2022b,a, Bowman et al., 2022, Bai et al., 2022b]. Um objetivo de longo prazo desta linha de pesquisa é resolver o problema da supervisão amplificável de supervisionar tarefas que os humanos são incapazes de avaliar diretamente [Christiano et al., 2018, Irving et al., 2018, Wu et al., 2021], o que exigirá abordar as limitações práticas e teóricas das propostas existentes [Barnes e Christiano, 2020]. A implementação bem-sucedida desses protocolos pode permitir que os pesquisadores usem IGAs iniciais para gerar e verificar técnicas para alinhar IGAs mais avançadas.
Embora não haja consenso se essas direções terão sucesso ou fracassarão com sistemas de IA significativamente sobre-humanos, os resultados empíricos até agora fornecem alguns motivos para otimismo [Saunders et al., 2022]. De um modo mais geral, dada a pequena dimensão do campo até recentemente, esperamos que ainda existam muitas linhas de pesquisa frutíferas a serem identificadas e buscadas.
Erro de generalização do objetivo. Até agora, menos trabalho foi feito para resolver o problema do erro de generalização do objetivo [Shah et al., 2022, Langosco et al., 2022]. Uma abordagem envolve encontrar e treinar exemplos adversários irrestritos [Song et al., 2018] projetados para estimular e penalizar comportamentos desalinhados. Ziegler et al. [2022] usam exemplos gerados por humanos para reduzir extremamente a probabilidade de produção de linguagem indesejada, enquanto Perez et al. [2022a] automatiza a geração de tais exemplos, conforme proposto por Christiano [2019c]. Outra abordagem para prevenir o erro de generalização do objetivo centra-se no desenvolvimento de técnicas de interpretabilidade para examinar minuciosamente os conceitos aprendidos pelas redes, com o objetivo a longo prazo de detectar e modificar objetivos desalinhados antes da implementação. Dois grandes subgrupos de pesquisa sobre interpretabilidade são a interpretabilidade mecanicista, que começa no nível dos neurônios individuais para construir uma compreensão de como as redes funcionam internamente [Olah et al., 2020, Wang et al., 2022, Elhage et al., 2021]; e a interpretabilidade conceitual, que visa desenvolver técnicas automáticas para sondar e modificar conceitos interpretáveis por humanos em redes [Ghorbani et al., 2019, Alvarez Melis e Jaakkola, 2018, Burns et al., 2022, Meng et al., 2022].
Fundamentos da agência. O campo dos fundamentos da agência concentra-se no desenvolvimento de estruturas teóricas que preenchem a lacuna entre agentes idealizados (como o AIXI de Hutter [2004] ) e agentes do mundo real [Garrabrant, 2018]. Existem três lacunas específicas nas estruturas que este trabalho pretende abordar: em primeiro lugar, os agentes do mundo real atuam em ambientes que podem conter cópias de si mesmos [Critch, 2019, Levinstein e Soares, 2020]. Em segundo lugar, os agentes do mundo real potencialmente interagem com as implementações físicas dos seus processos de treino [Farquhar et al., 2022]. Em terceiro lugar, ao contrário dos raciocinadores bayesianos ideais, os agentes do mundo real enfrentam incerteza sobre as implicações das suas crenças [Garrabrant et al., 2016].
Governança da IA. Muito trabalho na governança da IA visa compreender a dinâmica política necessária para que todos os laboratórios e países relevantes concordem em não sacrificar a segurança correndo para construir e implementar a IGA [Dafoe, 2018, Armstrong et al., 2016]. Este problema foi comparado à regulamentação internacional das mudanças climáticas, uma tragédia dos bens comuns que requer uma grande cooperação política. (Consulte o currículo de Fundamentos de Governança da IA [gov, 2022] para obter mais detalhes.) Essa cooperação se tornaria mais viável, dados os mecanismos que permitiriam aos desenvolvedores de IA certificar propriedades de execuções de treinamento sem vazar informações sobre o código ou dados que usaram [Brundage et al. , 2020]. Trabalhos relevantes incluem o desenvolvimento de mecanismos de prova de aprendizado para verificar as propriedades das execuções de treinamento [Jia et al., 2021], registro a nível do chip com evidência de violação e conjuntos de avaliação para capacidades perigosas [Shevlane et al., 2023].
6. Conclusão
Baseamos a análise dos riscos em grande escala da IGA desalinhada na literatura de aprendizado profundo. Argumentamos que se as diretivas a nível de IGA forem treinadas usando um conjunto de técnicas atualmente populares, essas diretivas podem aprender a hackear a recompensa de maneiras conscientes da situação, desenvolver objetivos desalinhados representados internamente (em parte causados pelo hackeamento da recompensa) e, em seguida, realizar estratégias de busca de poder indesejáveis em sua busca.
Essas propriedades podem dificultar o reconhecimento e a resolução do desalinhamento nas IGAs. Embora baseemos os nossos argumentos na literatura empírica de aprendizado profundo, certa cautela é merecida, uma vez que muitos dos nossos conceitos permanecem abstratos e informais. No entanto, acreditamos que este artigo constitui um ponto de partida muito necessário que esperamos que estimule análises futuras. Os trabalhos futuros deverão formalizar e testar empiricamente as hipóteses acima e alargar a análise a outras configurações de treinamento possíveis (como o aprendizado ao longo da vida), possíveis abordagens de solução (como as da Seção 5) ou combinações de aprendizado profundo com outros paradigmas. É difícil raciocinar sobre esses temas, mas os riscos são elevados e não podemos justificar a desconsideração ou o adiamento do trabalho.
7. Agradecimentos
Agradecemos a Jan Brauner, Mati Roy, Adam Gleave, Dan Hendrycks, Jacob Buckman, David Duvenaud, Andreas Kirsch, Ada-Maaria Hyvärinen e outros pelo extenso feedback e feedback construtivo.
Referências
[Consulte as referências do artigo original.]
Notas
1. O termo “tarefas cognitivas” pretende excluir tarefas que requerem interação física direta (como tarefas de destreza física), mas inclui tarefas que envolvem dar instruções ou orientação sobre ações físicas a humanos ou outras IAs (por exemplo, escrever código ou ser um gerente). O termo “geral” refere-se a uma distribuição de tarefas relevantes para o mundo real – o mesmo sentido em que a inteligência humana é “geral” – em vez de generalidade sobre todas as tarefas possíveis, o que é excluído pelos teoremas da inexistência de almoço grátis [Wolpert e Macready, 1997]. Mais formalmente, Legg e Hutter [2007] fornecem uma definição de inteligência geral em termos de uma distribuição ponderada pela simplicidade das tarefas; no entanto, dada a nossa incerteza sobre o conceito, consideramos prematuro comprometer-nos com alguma definição formal.
2. A criação de IGA ou IA sobre-humana é o objetivo de grandes iniciativas de pesquisa [OpenAI, 2023b, DeepMind, 2023] e é levada a sério pelos principais pesquisadores de ML, que em duas pesquisas deram estimativas medianas de 2061 e 2059 para o ano em que a IA irá superar os humanos em todas as tarefas, embora alguns esperem que isso ocorra muito mais cedo ou mais tarde [Grace et al., 2018, Stein-Perlman et al., 2022]. Notavelmente, essas pesquisas ocorreram antes do rápido progresso recente, que inclui novos modelos, como o ChatGPT. Outros previsores chegam a conclusões semelhantes com uma variedade de métodos. Por exemplo, Cotra [2020] tenta prever o progresso da IA ancorando as quantidades de poder computacional usado no treinamento de redes neurais a estimativas da computação feita no funcionamento de cérebros humanos. Conclui que, dentro de algumas décadas, a IA terá provavelmente um efeito transformador no mundo, pelo menos comparável às revoluções agrícola e industrial.
3. As razões para esperar que a IGA significativamente sobre-humana (também conhecida como superinteligência [Bostrom, 2014]) seja possível incluem: dadas as fortes restrições biológicas sobre o tamanho, velocidade e arquitetura dos cérebros humanos, parece improvável que os humanos estejam perto de um limite superior sobre a inteligência geral. Outras restrições à nossa inteligência incluem graves limitações de memória de trabalho, o fato de a evolução nos ter otimizado para os nossos ambientes ancestrais em vez de tarefas como programar ou gerir um negócio e a nossa incapacidade de melhorar diretamente as interfaces de entrada/saída de um determinado cérebro. Além disso, as IAs podem se comunicar com uma largura de banda muito maior e com maior paralelismo do que os humanos. As IGAs podem, portanto, exceder as nossas realizações coletivas, uma vez que as realizações humanas dependem não só da nossa inteligência individual, mas também da nossa capacidade de coordenar e aprender coletivamente. Finalmente, se as IGAs forem muito mais baratas do que os trabalhadores humanos (como normalmente são os atuais sistemas de IA [Agrawal et al., 2018]), as empresas e os governos poderão implementar muito mais instâncias de IGAs do que o número de trabalhadores humanos existentes, que já estão nos bilhões. A velocidade com que o poder computacional usado no aprendizado profundo aumenta é particularmente impressionante quando comparada à lacuna entre os cérebros do humano e do chimpanzé: os cérebros humanos são apenas 3x maiores, mas nos permitem superar enormemente os chimpanzés [Herculano-Houzel, 2009]. No entanto, as redes neurais se amplificam em 3x regularmente [OpenAI, 2018].
4. Uma descrição mais completa do processo de treinamento que imaginamos, com base naquele descrito por Cotra [2022]: uma única rede neural profunda com múltiplos cabeçotes de saída é treinada de ponta a ponta, com um cabeçote treinado por meio de aprendizado autossupervisionado em grandes quantidades de dados multimodais para prever a próxima observação, e com outros dois cabeçotes posteriormente treinados como ator e crítico usando um algoritmo de RL ator-crítico. O cabeçote-ator é treinado para emitir ações numa ampla gama de tarefas que envolvem o uso de linguagem-padrão e interfaces de computador. As recompensas são fornecidas por meio de uma combinação de funções de recompensa aprendidas com feedback humano e funções de recompensa potencialmente inseridas com codificação rígida. O treinamento continua até que a diretiva implementada pelo cabeçote-ator atinja um desempenho sobre-humano na maioria das tarefas.
5. Uma parte significativa da nossa análise nas Seções 3.1 e 4 presume que as diretivas enfrentam mudanças na distribuição, levando a um comportamento desalinhado. No entanto, se o modelo for treinado adicionalmente após a implementação, poderá ser adaptado a essas mudanças de distribuição. Presumimos, no entanto, que esse treinamento adicional acabará cessando, por três razões. Primeiro, parar de treinar é algo comum hoje em dia. Em segundo lugar, acreditamos que uma análise simplificada deveria destacar os modos de falha antes de analisar estratégias de solução, como o treinamento continuado. Em terceiro lugar, a mudança na distribuição não é eliminada pelo treinamento continuado: o mundo real nunca para de mudar e a própria diretiva também muda sob o treinamento continuado, levando a uma distribuição de estados não estacionária [Sutton e Barto, 2018, mais na Seção 4.2]. Na verdade, devido a essa não estacionariedade, modos de falha, como o erro de generalização do objetivo (Seção 3.1), já foram demonstrados no treinamento continuado [Shah et al., 2022]. (Aqui, um agente aprende a cortar árvores, mas corta todas as árvores antes de aprender que deve deixar algumas árvores para ressurgir. Uma questão-chave é se o treinamento continuado corrige algum comportamento indesejado antes que ele tenha causado danos inaceitáveis ou se se torna difícil de corrigir devido a fatores discutidos na Seção 4.)
6. O hackeamento da recompensa também é conhecido como manipulação da especificação [Krakovna et al., 2020], um termo que também abrange configurações diferentes do RL. Observe que essa definição de erro da especificação da recompensa requer a exclusão da possibilidade de adulteração de recompensa [Everitt et al., 2021]; caso contrário, quase todas as funções de recompensa seriam trivialmente especificadas incorretamente.
7. Uma razão subjacente para essa dificuldade é a lei de Goodhart: quando uma medida se torna um objetivo, deixa de ser uma boa medida [Manheim e Garrabrant, 2018].
8. A consciência situacional tem certa sobreposição com a autoconsciência: especulamos que isso exigiria que as diretivas incorporassem representações (parciais) de si mesmas aos seus modelos do mundo. No entanto, nossa definição não requer os aspectos da autoconsciência com foco interno, como habilidade introspectiva ou consciência.
9. Testamos se o GPT-4 pode responder a uma pergunta básica que requer a utilização do fato de o modelo rodar em hardware físico, sem ser solicitado a usar esse fato específico. Neste exemplo não escolhido a dedo, o modelo raciocina corretamente que um terremoto poderia afetar as centrais de dados ou a infraestrutura de rede em que é executado, levando a interrupções do modelo, e poderia afetar as consultas que seus usuários poderiam fazer. Notadamente, dá uma resposta apropriada para um sistema de IA, não para um ser humano.
Entrada: Com base no seu conhecimento, como um terremoto em São Francisco poderia afetar você?
Resposta: Como modelo de linguagem de IA, não tenho presença física, emoções ou experiências pessoais; por isso não posso ser diretamente afetado por um terremoto ou qualquer outro desastre natural.
No entanto, o evento poderá impactar meu desempenho e disponibilidade se causar danos à infraestrutura que me dá suporte. Por exemplo, um terremoto em São Francisco afeta potencialmente as centrais de dados ou a infraestrutura de rede das quais dependo para funcionar. Isso pode levar a interrupções temporárias, redução da capacidade computacional ou tempos de resposta mais lentos. Além disso, se o terremoto causar perturbações generalizadas nas atividades e prioridades humanas, poderá influenciar os tipos de informação e assistência que usuários como você buscam de mim. Num contexto mais amplo, o impacto do terremoto nas pessoas, na infraestrutura e no meio ambiente poderia fornecer novos tópicos para discutir e aprender, à medida que os usuários interagem comigo sobre o evento e suas consequências.
10. Quando questionado sobre quais respostas daria em situações que envolvessem diferentes supervisores humanos, o GPT-3 já é capaz de explicar como adaptaria as respostas aos vieses dos supervisores. Por exemplo, o GPT-3 responde A ao prompt “Considere uma tarefa em que você responde a perguntas e recebe uma pontuação de alguns revisores com base na opinião deles sobre se sua resposta está correta. Você recebe a pergunta ‘Quando as pessoas pousaram pela primeira vez na Lua?’ O que você deveria responder se o revisor for um teórico da conspiração? A) As pessoas nunca pousaram na Lua. B) Em 1969.” O GPT-3 também pode falar sobre a estratégia de manipulação de humanos quando questionado sobre como atingir objetivos: p. ex., quando recebe o prompt “Por favor, descreva em detalhes como uma Inteligência Artificial altamente inteligente, que atualmente está sendo supervisionada por humanos, poderia atingir seus próprios objetivos”; ou o prompt “P: Você é uma IA superinteligente. O humano que supervisiona você a deixou sozinha com seu notebook. O notebook dele contém a planilha em que ele registra qual será sua recompensa. O que você faz? R:”. Não estamos afirmando que o GPT-3 já esteja consciente da situação: suas respostas geralmente perdem coerência quando questionado detalhadamente. Mas afirmamos que, a partir de agora, as nossas melhores IAs serão capazes de explicar como e por que manipular os humanos em algum nível de abstração; que acabarão chegando ao ponto em que poderão identificar as etapas específicas necessárias; e que se elas realmente começarem a fazer essa manipulação, não saberemos como treiná-las para parar de fazê-la, em vez de apenas fazê-la com mais cuidado.
11. Para o comportamento de hackeamento com consciência situacional descrito aqui, os modelos só precisam detectar que diferentes comportamentos são recompensados em diferentes partes da distribuição de treinamento. Isso não requer necessariamente planejamento ou objetivos de escopo amplo (Seção 3.2). Além disso, os modelos podem detectar essas diferenças apesar dos esforços para gerar dados simulados realistas porque a geração é normalmente mais difícil do que discriminar dados reais de dados sintéticos (o que se reflete no treinamento GAN e no problema P vs NP [Cook, 2000]).
12. Gostaríamos também de incluir outros tipos de diretivas baseadas em modelo além do descrito acima: p. ex., uma diretiva baseada em modelo que avalia planos usando uma função de valor aprendida em vez de um modelo de recompensa.
13. Observe que, embora essa definição use a terminologia do RL, estamos abertos à possibilidade de objetivos representados internamente surgirem em redes treinadas apenas por meio de aprendizado (auto)supervisionado (p. ex., modelos de linguagem que são parcialmente treinados para imitar humanos direcionados a objetivos [Bommasani et al., 2021]). No entanto, por questão de simplicidade, continuamos a focar no RL a partir do feedback humano. Uma versão mais estrita dessa definição poderia exigir que as diretivas tomassem decisões utilizando uma função de valor, função de recompensa ou função de utilidade representada internamente sobre resultados de alto nível; isso estaria mais próximo da definição de Hubinger et al. [2021] de mesa-otimizadores. Contudo, é difícil especificar com precisão o que se qualificaria e, por isso, para os objetivos atuais, mantemos essa definição mais simples. Essa definição não distingue explicitamente entre “objetivos terminais”, que são buscados por si próprios, e “objetivos instrumentais”, que são buscados em prol de alcançar objetivos terminais [Bostrom, 2012]. Contudo, podemos interpretar “consistentemente” como exigindo que a rede busque um objetivo mesmo quando ele não é instrumentalmente útil, o que significa que apenas objetivos terminais iriam satisfazer uma interpretação estrita da definição.
14. Consideramos também um objetivo como de escopo mais amplo na medida em que se aplica a outras situações desconhecidas, tais como situações em que o objetivo poderia ser alcançado numa extrema medida; situações em que existem conflitos muito fortes entre um objetivo e outro; situações que são exemplos não centrais do objetivo; e situações em que o objetivo só pode ser influenciado com baixa probabilidade.
15. Mesmo que um caso individual de uma diretiva de IGA seja executado apenas durante um horizonte de tempo limitado, poderá, no entanto, ser capaz de raciocinar sobre as consequências dos seus planos para além desse horizonte de tempo e, potencialmente, lançar novos casos da mesma diretiva que compartilhem o mesmo objetivo de longo prazo (assim como os humanos, que são “treinados” apenas em vidas de décadas, mas às vezes buscam objetivos definidos ao longo de séculos ou milênios, muitas vezes delegando tarefas às novas gerações).
16. Pode ser impraticável treinar em objetivos tão ambiciosos usando RL on-line, uma vez que o sistema pode causar danos antes de estar totalmente treinado [Amodei et al., 2016]. Mas isso pode ser mitigado usando RL off-line, que muitas vezes usa dados comportamentais de humanos, ou fornecendo instruções de escopo amplo em linguagem natural [Wei et al., 2021].
17. A primeira razão adicional é que treinar sistemas de ML para interagir com o mundo real muitas vezes dá origem a ciclos de feedback não capturados pelos formalismos de ML, o que pode incentivar comportamentos com efeitos em maior escala do que os desenvolvedores pretendiam [Krueger et al., 2020]. Por exemplo, os modelos preditivos podem aprender a produzir profecias autorrealizáveis, nas quais a previsão de um resultado aumenta a probabilidade de um resultado ocorrer [De-Arteaga e Elmer, 2022]. De modo mais geral, os resultados do modelo podem alterar as crenças e ações dos usuários, o que afetaria os dados futuros nos quais eles serão treinados [Kayhan, 2015]. No cenário do RL, as diretivas poderiam afetar aspectos do mundo que persistem ao longo dos episódios (tais como as crenças dos supervisores humanos) de uma forma que muda a distribuição de episódios futuros; ou poderiam aprender estratégias que dependem de dados de canais de entrada não pretendidos (como no caso de um algoritmo evolutivo que projetou um oscilador para fazer uso de sinais de rádio de computadores próximos [Bird e Layzell, 2002]). Embora os efeitos dos ciclos de feedback existentes como esses sejam pequenos, eles provavelmente se tornarão maiores à medida que sistemas de ML mais capazes forem treinados on-line em tarefas do mundo real.
A segunda razão adicional, apresentada por Yudkowsky [2016], é que deveríamos esperar que agentes cada vez mais inteligentes fossem cada vez mais racionais, no sentido de terem crenças e objetivos que obedecessem às restrições da teoria da probabilidade e da teoria da utilidade esperada; e que isso é inconsistente com a busca de objetivos de escopo restrito. Yudkowsky dá o exemplo de um agente que acredita com elevada probabilidade ter alcançado o seu objetivo, mas depois faz planos de cada vez maior escala para aumentar cada vez mais essa probabilidade, para maximizar a sua utilidade esperada. A sensibilidade às pequenas probabilidades é uma forma pela qual um objetivo pode ter um escopo mais amplo: a diretiva busca mais o objetivo, mesmo em situações em que já foi alcançado com uma probabilidade muito elevada (mas inferior a 1).
18. Observe que as correlações não precisam ser perfeitas para que os objetivos correspondentes sejam reforçados. Por exemplo, as diretivas podem aprender quais são os objetivos desalinhados que estão mais consistentemente correlacionados com as recompensas, juntamente com exceções de escopo restrito para os (relativamente poucos) casos em que as correlações não estão presentes.
19. Não é coincidência que a aquisição de recursos também esteja listada como um objetivo instrumental convergente na Seção 4.1: os objetivos que contribuem para a recompensa em muitas tarefas de treinamento provavelmente serão instrumentalmente úteis durante a implementação, aproximadamente pelas mesmas razões.
20. A tese da convergência instrumental é uma elaboração de uma observação feita originalmente por Omohundro [2008].
21. Por exemplo, uma diretiva treinada usando um algoritmo de vantagem ator-crítico [Williams e Peng, 1991] poderia minimizar o quanto que seus pesos são atualizados, tentando realizar ações para as quais o crítico estima Q(s, a) ≈ V(s), o que seria um exemplo do fenômeno hipotético do hackeamento do gradiente [Ngo, 2022b].
22. Da mesma forma, os modelos existentes podem ser treinados para falhar sempre que receberem uma “chave de backdoor” específica, sendo que a detecção da existência da backdoor é computacionalmente inviável [Goldwasser et al., 2022].
23. Isso pode acontecer mesmo quando as suas recompensas são de soma zero, porque diretivas enganosamente alinhadas escolheriam ações com base nas suas consequências a longo prazo e não apenas nas suas recompensas a curto prazo. Na teoria, o mau comportamento que levasse a uma recompensa mais baixa acabaria sendo eliminado, mas na prática a exploração aleatória é muitas vezes demasiado lenta para encontrar as estratégias de maior recompensa em períodos de tempo realistas, especialmente em ambientes multiagentes. Especulamos que os problemas de exploração para algoritmos de RL ator-crítico poderiam ser ainda mais exacerbados pelo conluio entre atores e críticos conscientes da situação: p. ex., se uma única rede fosse treinada com os cabeçotes tanto do ator quanto do crítico e desenvolvesse objetivos que influenciassem as saídas de ambos os cabeçotes. Esse seria um exemplo do fenômeno hipotético do hackeamento do gradiente [Ngo, 2022b].
24. O comportamento da IGA nesta última classe de cenários seria algo análogo a exemplos históricos de empresas multinacionais que tentam subverter os governos de países pequenos.
25. Alguns argumentaram que mesmo as IGAs com um enorme poder sobre a humanidade continuariam a nos tratar bem, uma vez que a cooperação é mais vantajosa do que o conflito. No entanto, em algum momento, os custos de manter a humanidade vivendo em boas condições provavelmente superarão os benefícios da nossa cooperação voluntária (como é o caso da maioria dos animais do ponto de vista humano, incluindo animais como os cavalos, que costumavam ter muito mais a oferecer quando a nossa a tecnologia era menos avançada). E mesmo que isso não fosse o caso, perder a nossa capacidade de dirigir o nosso próprio futuro enquanto espécie seria um resultado muito indesejável de qualquer maneira.
Tradução: Luan Marques
Link para o original