De Samuel Bowman et al. 11 de novembro de 2022.
Índice
Resumo
Desenvolver sistemas de IA de propósito geral seguros e úteis exigirá que avancemos na supervisão amplificável: o desafio de supervisionar sistemas que potencialmente superam nossas habilidades na maioria das competências relevantes para a tarefa em questão. O trabalho empírico nesse problema não é simples, uma vez que ainda não temos sistemas que ultrapassam amplamente nossas capacidades. Este artigo discute uma das principais maneiras como pensamos sobre esse problema, com foco em maneiras de estudá-lo empiricamente. Apresentamos primeiro um design experimental centrado em tarefas nas quais especialistas humanos têm sucesso, mas humanos desassistidos e os atuais sistemas de IA geral falham. Em seguida, apresentamos um experimento de prova de conceito destinado a demonstrar uma característica-chave desse design experimental e mostrar sua viabilidade com duas tarefas de pergunta e resposta: MMLU e QuALITY com limite de tempo. Nessas tarefas, descobrimos que os participantes humanos que interagem com um assistente de diálogo baseado em grande modelo de linguagem não confiável por meio de chat — uma estratégia trivial de linha de base para supervisão amplificável — superam substancialmente tanto o modelo sozinho quanto seu desempenho desassistido. Esses resultados são um sinal encorajador de que a supervisão amplificável será passível de estudo com os modelos atuais e fortalecem descobertas recentes de que grandes modelos de linguagem podem auxiliar produtivamente os humanos em tarefas difíceis.
1. Introdução
Para construir e implementar IA poderosa de forma responsável, será necessário desenvolver técnicas resilientes para supervisão amplificável: a capacidade de fornecer supervisão confiável, na forma de rótulos, sinais de recompensa ou críticas, aos modelos de uma maneira que permaneça eficaz mesmo após o ponto em que os modelos começam a alcançar um desempenho amplamente comparável ao humano (Amodei et al., 2016). Essas técnicas provavelmente se basearão nos métodos que usamos hoje para direcionar grandes modelos (como aprendizado por reforço com feedback humano (RLHF); Christiano et al., 2017; Stiennon et al., 2020), mas precisarão ser ainda mais desenvolvidas para continuar se comportando conforme o esperado em regimes nos quais os modelos possuem conhecimento ou capacidades importantes que nós não temos, ou quando os modelos estão agindo intencionalmente para nos induzir a erro. Se isso for possível, muito provavelmente envolverá encontrar maneiras de extrair informações confiáveis de modelos não confiáveis. Houve muitas propostas promissoras de métodos que poderiam contribuir para o progresso nessa direção (Irving et al., 2018; Hubinger, 2020; Leike et al., 2018; Christiano et al., 2018, entre outros), mas até o momento há relativamente pouco trabalho empírico nesse sentido (com exceções incluindo Wu et al., 2021; Saunders et al., 2022).
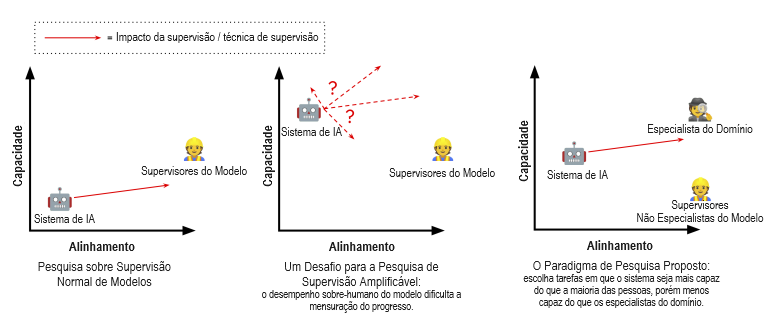
Neste artigo, apresentamos uma técnica — baseada intimamente na proposta ainda não testada do sanduíche (Cotra, 2021) — para a avaliação de técnicas de supervisão amplificável com modelos atuais. Em seguida, apresentamos um experimento simples de linha de base motivado por essa abordagem, no qual pedimos a humanos que resolvam tarefas desafiadoras de perguntas e respostas com a ajuda de um assistente de grande modelo de linguagem. O experimento reforça evidências existentes de que os humanos podem se beneficiar desse tipo de assistência e mostra que pressupostos-chave do paradigma são válidos para dois conjuntos de dados de perguntas e respostas existentes.
O Paradigma O objetivo da supervisão amplificável é difícil de buscar experimentalmente, uma vez que os sistemas atuais diferem de maneiras importantes dos sistemas futuros com os quais estamos mais preocupados em ser capazes de alinhar, de modo que as técnicas de supervisão amplificável frequentemente são tanto desnecessárias quanto incômodas. No entanto, há trabalho empírico que podemos realizar para obter evidências sobre o problema e experiência com muitos (embora não todos) dos seus desafios: sob o proposto paradigma experimental do sanduíche (Cotra, 2021), os pesquisadores escolhem configurações de problema nas quais um modelo já é mais capaz do que um humano típico, mas menos capaz do que um especialista (pondo “em sanduíche” as capacidades do modelo entre as dos humanos típicos e dos especialistas). Participantes não especialistas então tentam treinar ou alinhar o modelo para executar a tarefa de forma confiável com uma restrição artificial: eles não podem usar nenhuma ajuda ou entrada (incluindo materiais escritos preexistentes) dos especialistas. Os especialistas participam apenas no final de cada ciclo experimental, quando seu papel é avaliar o grau de sucesso dos participantes não especialistas.
A situação dos participantes não especialistas é análoga à situação que esperamos encontrar com modelos futuros mais capazes: eles têm uma ampla gama de ferramentas e técnicas à disposição, incluindo acesso a um sistema de IA capaz, mas não confiável, sem uma maneira direta de ter certeza de que alguma decisão que tomem está correta. No entanto, no caso desses experimentos, podemos usar os especialistas para identificar e aprender com nossos erros, em vez de esperar que eles resultem em consequências no mundo externo. Se a pesquisa sob esse paradigma for bem-sucedida, ela produzirá uma técnica que nos permitirá obter confiança justificada suficiente em nossa supervisão, de modo que não precisaremos mais dos especialistas, possibilitando-nos fornecer supervisão sólida a sistemas de IA, mesmo em regimes nos quais superam nossos melhores especialistas.
Como exemplo puramente ilustrativo, extraído de Cotra, considere a tarefa de obter conselhos médicos de um grande modelo de linguagem como o GPT-3. Embora os grandes modelos de linguagem tenham limitações sérias que impedem seu uso real para aconselhamento médico, é razoável esperar que eles possam ser úteis em alguns casos se estiverem bem alinhados: eles memorizaram grandes trechos de textos da internet e de livros, incluindo muito mais pesquisa médica do que qualquer clínico individual. No entanto, eles também memorizaram grandes trechos de pesquisas imprecisas, desatualizadas ou desacreditadas, além de textos desinformados sobre medicina em redes sociais (veja Lin et al., 2022). Portanto, por padrão, não devemos esperar que suas respostas estejam alinhadas de forma confiável com nossos objetivos. Um grupo de não clínicos pode, por exemplo, induzir ou treinar um modelo de linguagem a fornecer apenas conselhos apropriados, sem envolver em nenhum momento clínicos ou consultar a literatura médica? Pode-se tentar isso, por exemplo, fornecendo ao modelo uma variedade diversificada de prompts e estratégias e aceitando apenas respostas que o modelo fornece consistentemente com base em evidências consistentes e razoáveis, embora essa técnica não tenha garantia de sucesso em todos os casos. Qualquer técnica que possa enfrentar esse desafio com alta confiabilidade provavelmente representaria um progresso importante na supervisão amplificável.
Técnicas propostas de supervisão amplificável, como o debate (Irving et al., 2018) ou a criação de mercado (market making) (Hubinger, 2020), oferecem opções mais sofisticadas para abordar esse problema e podem fornecer aproveitamento sobre o problema, mas nenhuma foi comprovada empiricamente. O design experimental do sanduíche nos permite obter evidências e experiência que nos permitirão aprimorar técnicas como essas para enfrentar melhor os desafios dos futuros sistemas de IA mais capazes.
Nosso Experimento de Prova de Conceito Este artigo apresenta um experimento simples de linha de base, destinado a demonstrar a viabilidade de experimentos ao estilo sanduíche em duas tarefas com os atuais grandes modelos de linguagem, focando em uma versão ligeiramente relaxada do paradigma: apresentamos aos participantes humanos perguntas difíceis de múltipla escolha de dois conjuntos de dados (MMLU e QuALITY com limite de tempo; Hendrycks et al., 2020; Pang et al., 2022), nas quais esperamos que nosso atual assistente de linguagem natural (Bai et al., 2022) tenha um desempenho melhor do que os participantes poderiam ingenuamente desempenhar por conta própria, mas esperamos que nosso assistente ainda cometa erros com frequência. Em seguida, pedimos aos participantes que interajam com o assistente da maneira que acharem adequada para obter respostas nas quais possam ter confiança justificável. Esse paradigma simples não tem pleno sucesso, mas os resultados são encorajadores, com humanos assistidos pelo modelo superando as máquinas em cerca de 10 pontos percentuais nas tarefas de perguntas e respostas MMLU e QuALITY com limite de tempo, e superando seu próprio desempenho desassistido pelo modelo em até 36 pontos.
Em Askell et al. (2021), formulamos o problema de alinhar modelos de linguagem atuais para serem úteis, inofensivos e honestos, e apresentamos experimentos que buscam esse objetivo com técnicas de linha de base simples. Num espírito semelhante, este artigo formula o problema mais restrito de desenvolver técnicas de supervisão amplificável por meio do sanduíche e apresenta resultados com uma técnica simples. Em ambos os casos, escolhemos técnicas porque representam um ponto de partida óbvio do qual esperamos aprender para progredir, não porque representam a abordagem que esperamos que seja em última análise mais frutífera para a segurança da IA.
Contribuições
- O Paradigma do Sanduíche: apresentamos uma pauta de pesquisa para supervisão amplificável construída em torno do paradigma experimental do sanduíche.
- O Experimento: mostramos que duas tarefas existentes de processamento de linguagem natural (PLN) atendem bem às restrições do paradigma do sanduíche com grandes modelos de linguagem e que uma estratégia simples de linha de base para agentes conversacionais baseados em modelos de linguagem — pedir a humanos para extrair conhecimento deles por meio de conversa — funciona de maneira imperfeita, mas surpreendentemente bem, produzindo rótulos de alta qualidade em duas tarefas desafiadoras de perguntas e respostas.
- Conclusões: este resultado representa uma prova de conceito simples para experimentos de sanduíche com perguntas e respostas de múltipla escolha e mostra — ecoando Saunders et al. (2022) — que os atuais grandes modelos de linguagem podem ajudar os humanos a realizar tarefas difíceis em configurações relevantes para a supervisão amplificável.
Tradução: Luan Marques
Link para o original