De Kevin Meng, David Bau, Alex Andonian e Yonatan Belinkov. 2022.
Índice
Onde estão os fatos dentro de um modelo de linguagem?
Conhecer difere de dizer: proferir palavras mecanicamente é diferente de conhecer um fato, porque o conhecimento de um fato generaliza-se entre contextos. Neste projeto, mostramos que o conhecimento factual dentro do GPT também corresponde a uma computação localizada que pode ser editada diretamente. Por exemplo, podemos fazer uma pequena alteração em um pequeno conjunto de pesos do GPT-J para ensinar a ele o contrafactual “A Torre Eiffel fica localizada na cidade de Roma”. Em vez de apenas regurgitar a nova frase, ele generalizará esse conhecimento contrafactual específico e o aplicará em contextos linguísticos muito diferentes.

Por que localizar fatos?
Estamos interessados em como e onde um modelo armazena suas associações factuais, por duas razões:
- Para entender enormes redes neurais opacas. Os cálculos internos de grandes modelos de linguagem são obscuros. Esclarecer o processamento dos fatos é um passo na compreensão das redes massivas de transformadores.
- Corrigir erros. Os modelos frequentemente são incorretos, tendenciosos ou privados, e gostaríamos de desenvolver métodos que permitam a depuração e correção de erros factuais específicos.
Os fatos que estudamos assumem a forma de tuplas de conhecimento t = (s, r, o) , sendo s e o entidades sujeito e objeto, respectivamente, e r a relação que conecta as duas. Por exemplo, (s= Megan Rapinoe , r= pratica esporte profissionalmente, o= futebol ) indica que Rapinoe ganha a vida jogando futebol. Cada variável representa uma entidade ou relação que pode ser encontrada em um gráfico de conhecimento e que pode ser escrita como uma string de linguagem natural.
Para consultar o GPT quanto ao conhecimento de um fato, expressamos (s, r) como um prompt de texto (expandindo um modelo (template) do conjunto de dados CounterFact) e verificamos se a continuação gerada corresponde a o.
O que encontramos?
Nos modelos de transformadores ao estilo GPT, descobrimos duas coisas:
1. As associações factuais podem ser localizadas ao longo de três dimensões, para (1) parâmetros do módulo de MLP (2) em uma faixa de camadas intermediárias e (3) especificamente durante o processamento do último token do assunto.

O rastro causal acima revela um pequeno número de estados que contêm informações que podem mudar o modelo de uma previsão factual para outra. Nossos estudos utilizam tais rastros causais e encontram evidências de que a recuperação de conhecimento ocorre em módulos de MLP no local inicial (em (a) na figura); então, os mecanismos de atenção no local final (em (b) na figura) trazem a informação para o final do cálculo, onde a palavra específica pode ser prevista.
2. As associações factuais individuais podem ser alteradas fazendo pequenas alterações de classificação um em um único módulo de MLP. Podemos distinguir entre mudanças no conhecimento e mudanças superficiais na linguagem medindo a generalização para outras formulações do mesmo fato.

O exemplo acima mostra que a alteração do processamento do modelo de uma única declaração sobre a Torre Eiffel, se feita através da alteração correta dos parâmetros selecionados, resultará na expressão de uma mudança no conhecimento numa variedade de contextos não triviais.
Em (a) na figura, uma única declaração direta de um contrafactual é apresentada e é usada para calcular uma mudança de parâmetro de classificação um em um único módulo de MLP. Apesar da simplicidade da mudança, os resultados apresentados em (b) mostram que, para um prompt mais complexo sobre viagens a partir de Berlim, o modelo trata a Torre Eiffel como se estivesse em Roma; da mesma forma em (c), quando questionado sobre locais próximos, o modelo sugere locais em Roma antes de mencionar explicitamente Roma. As mudanças nas previsões em contextos tão diferentes são uma prova de que a mudança se generaliza: o modelo não apenas aprendeu a repetir a sequência exata de palavras no cenário contrafactual, mas também aplica o novo conhecimento em frases que são muito diferentes do exemplo original.
Como localizar a recuperação factual
Para identificar cálculos decisivos, introduzimos um método chamado Rastreamento Causal. Ao isolar o efeito causal de estados individuais dentro da rede durante o processamento de uma declaração factual, podemos rastrear o caminho seguido pela informação através da rede.

Rastreamentos causais funcionam executando uma rede várias vezes, introduzindo corrupções para frustrar a computação e, em seguida, restaurando estados individuais para identificar as informações que restauram os resultados. O rastreamento pode ser usado para testar qualquer estado individual ou combinações de estados. Usamos rastreamentos cuidadosamente projetados para identificar um pequeno conjunto específico de cálculos do módulo de MLP que medeiam a recuperação de associações factuais.
Em seguida, verificamos essa descoberta perguntando: os cálculos do módulo de MLP podem ser alterados para editar a crença de um modelo num fato específico?
Como editar o armazenamento factual
Para modificar fatos individuais dentro de um modelo de GPT, introduzimos um método chamado ROME, ou Rank-One Model Editing (Edição de Modelo de Classificação Um). Ele trata um módulo de MLP como um simples armazenamento de valor-chave: por exemplo, se a chave codifica um assunto e o valor codifica o conhecimento sobre o assunto, então o MLP pode recuperar a associação recuperando o valor correspondente à chave. A ROME usa uma modificação de classificação um dos pesos de MLP para escrever diretamente em um novo par de valores-chave.

A figura acima ilustra um único módulo de MLP dentro de um transformador. O vetor D-dimensional em (b) atua como a chave que representa um assunto a ser conhecido, e a saída H-dimensional em (c) atua no valor que codifica as propriedades aprendidas sobre o assunto. A ROME insere uma nova associação fazendo uma alteração de classificação um na matriz (d) que mapeia a partir de chaves para valores.
Observe que a ROME pressupõe uma visão linear da memória dentro de uma rede neural, em vez de uma visão de neurônios individuais. Essa perspectiva linear vê as memórias individuais como fatias de classificação um do espaço de parâmetros. Os experimentos confirmam essa visão: quando fazemos uma atualização de classificação um para um módulo de MLP no centro computacional identificado pelo rastreamento causal, descobrimos que as associações de fatos individuais podem ser atualizadas de uma forma que é ao mesmo tempo específica e generalizada.
Como distinguir entre saber um fato e dizer um fato
Saber é diferente de dizer. Uma variedade de métodos de ajuste fino pode fazer com que um modelo de linguagem papagueie uma nova frase específica, mas treinar um modelo para ajustar o seu conhecimento de um fato é diferente de meramente ensiná-lo a regurgitar uma sequência específica de palavras.
Podemos perceber a diferença entre saber e dizer medindo duas características do conhecimento: especificidade e generalização.
- Especificidade significa que, quando o seu conhecimento de um fato muda, isso não muda outros fatos. Por exemplo, depois de saber que a Torre Eiffel fica em Roma, você não deve pensar também que todas as outras atrações turísticas também ficam em Roma.
- Generalização significa que o seu conhecimento de um fato é resistente a mudanças na formulação e no contexto. Depois de saber que a Torre Eiffel fica em Roma, você também deve saber que visitá-la exigirá uma viagem a Roma.
Nosso novo conjunto de dados CounterFact inclui milhares de contrafactuais junto com textos que permitem testes quantitativos de especificidade e generalização ao aprender um contrafactual.
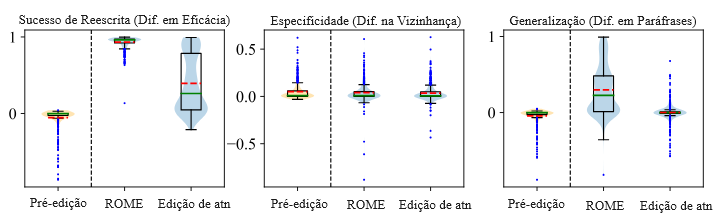
Acima estão os resultados de um experimento que usa o CounterFact para confirmar a distinção entre conhecer e dizer parâmetros no GPT-2 XL. A ROME, que edita o local causal inicial (a), alcança excelente eficácia (medida pelo desempenho no próprio prompt contrafactual), especificidade (desempenho em assuntos da vizinhança que não deveriam mudar) e generalização (desempenho em paráfrases). Por outro lado, se modificarmos o mecanismo de atenção no local posterior (b), o modelo alcança eficácia e especificidade razoáveis, mas falha completamente na generalização.
Trabalhos relacionados
Nosso trabalho se baseia em insights de outros trabalhos que examinaram grandes modelos de linguagem de transformadores e grandes redes neurais de várias outras perspectivas:
Mecanismos de transformadores
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, Chris Olah. Uma estrutura matemática para circuitos transformadores. Anthropic 2021.
Notas: Analisa mecanismos internos de componentes de transformadores, desenvolvendo ferramentas matemáticas para a compreensão de padrões de cálculos. Observa o comportamento de cópia de informações na autoatenção e o implica no forte desempenho dos transformadores.
Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy. As camadas de feed-forward de transformadores são memórias de valor-chave. EMNLP 2021.
Notas: Propõe a visão de que os módulos de transformadores de MLP atuam como memórias de valor-chave semelhantes às estruturas de dados de memória baseadas em softmax de duas camadas. Analisa a contribuição desses módulos para representações de tokens em cada camada.
Sumu Zhao, Damián Pascual, Gino Brunner, Roger Wattenhofer. Da não linearidade e comutatividade no BERT. IJCNN 2021.
Notas: Realiza uma série de experimentos de cálculos de modelos de transformadores, incluindo um experimento que mostra que a troca de camadas adjacentes de um transformador tem impacto mínimo em seu comportamento.
Extraindo Conhecimento de LMs
Fabio Petroni, Tim Rocktaschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. Modelos de linguagem como bases de conhecimento? EMNLP-IJCNLP 2019.
Notas: Propõe o uso de prompts de preenchimento para extrair conhecimento de grandes modelos de linguagem.
Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig. Como podemos saber o que os modelos de linguagem sabem? TACL 2020.
Notas: Discute várias maneiras de diversificar prompts para melhorar a extração de conhecimento de modelos de linguagem.
Adam Roberts, Colin Raffel, Noam Shazeer. Quanto conhecimento você pode incluir nos parâmetros de um modelo de linguagem? EMNLP 2020.
Notas: Propõe o ajuste fino de um modelo de linguagem de transformador pré-treinado para expandir sua capacidade de responder a questões factuais sem depender de uma fonte externa de conhecimento.
Zexuan Zhong, Dan Friedman, Danqi Chen. A sondagem factual é [MÁSCARA]: aprender vs. aprender a recordar. NAACL 2021.
Notas: Examina o uso de sondas de conhecimento aprendido para extrair conhecimento e também observa os riscos de alucinar novos conhecimentos em vez de extrair conhecimento ao usar essa técnica.
Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, Yoav Goldberg. Medindo e melhorando a consistência em modelos de linguagem pré-treinados. TACL 2021.
Notas: Examina a generalização consistente de modelos de linguagem, ou seja, se eles predizem os mesmos fatos sob paráfrases. O fato de os modelos serem frequentemente inconsistentes sob paráfrases pode ser visto como evidência de que não têm conhecimento generalizável de alguns fatos. Usamos o conjunto de dados ParaRel como base para o CounterFact .
Efeitos causais dentro de redes neurais
Yash Goyal, Amir Feder, Uri Shalit, Been Kim. Explicando classificadores com o efeito do conceito causal (CaCE). 2019.
Notas: Da visão computacional; observa que explicações causais podem chegar a conclusões diferentes de uma análise correlativa e propõe maneiras de construir explicações contrafactuais em visão computacional.
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, Stuart Shieber. Investigando o viés de gênero em modelos de linguagem usando análise de mediação causal. NeurIPS 2020.
Notas: Aplica análise de mediação causal para identificar neurônios decisivos e cabeçotes de atenção responsáveis pelo viés de gênero em grandes modelos de linguagem. Identifica um pequeno grupo de cabeçotes de atenção decisivas nesse caso.
Amir Feder, Nadav Oved, Uri Shalit, Roi Reichart. CausaLM: explicação do modelo causal por meio de modelos de linguagem contrafactual. CL 2021.
Notas: Elabora uma estrutura para compreender a estrutura de um modelo de linguagem, construindo contrafactuais baseados em representações e testando a resposta causal do modelo a eles.
Yanai Elazar, Shauli Ravfogel, Alon Jacovi, Yoav Goldberg. Sondagem amnésica: explicação comportamental com contrafactuais amnésicos. TACL 2021.
Notas: Propõe medir a importância de informações específicas dentro de um modelo, introduzindo uma intervenção causal para apagar essas informações e, em seguida, observando os efeitos causais.
Edição de conhecimento
Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh Bhojanapalli, Daliang Li, Felix Yu, Sanjiv Kumar. Modificando memórias em modelos de transformadores. 2020.
Notas: Constata que um ajuste fino restringido simples, no qual os pesos são restringidos para ficarem próximos de seus valores pré-treinados, é muito eficaz na modificação do conhecimento aprendido dentro de um transformador.
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Furu Wei. Neurônios de conhecimento em transformadores pré-treinados. 2021.
Notas: Com base em Geva (2021), propõe que neurônios individuais dentro de camadas de MLP codificam fatos individuais. Descreve um método de atribuição para encontrar os neurônios de um fato e conduz experimentos manipulando esses neurônios para editar fatos armazenados.
Nicola De Cao, Wilker Aziz, Ivan Titov. Editando Conhecimento Factual em Modelos de Linguagem. EMNLP 2021.
Notas: Desenvolve uma hiper-rede “KnowledgeEditor” (KE) para ajustar um modelo para incorporar um novo fato dado por uma descrição textual do fato. A hiper-rede é uma rede neural recorrente que processa a descrição e também os gradientes de uma perda para propor uma mudança complexa em múltiplas camadas na rede.
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, Christopher D. Manning. Edição rápida de modelos em escala. ICLR 2022.
Notas: Desenvolve uma hiper-rede (MEND) para ajustar um modelo para alterar suas previsões para corresponder a uma única execução de texto. A hiper-rede usa gradientes dentro da rede para inferir uma pequena atualização de classificação um no modelo; o método é mostrado em escala para transformadores muito grandes.
Edição de modelos em visão computacional
Métodos de edição de modelos que usam poucos ou nenhum dado de treinamento também foram estudados em visão computacional.
David Bau, Steven Liu, Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba. Reescrevendo um modelo generativo profundo. ECCV 2020.
Notas: Demonstra a edição direta de regras associativas dentro de camadas de uma rede adversária generativa (GAN), permitindo que um usuário altere a aparência de objetos em um modelo sem fornecer novas imagens de treinamento. Em nosso trabalho atual, adotamos a estrutura de edição de memória de classificação um e a aplicamos a transformadores de grandes modelos de linguagem.
Sheng-Yu Wang, David Bau, Jun-Yan Zhu. Esboce sua própria GAN. ICCV 2021.
Notas: Desenvolve um método para alterar um modelo usando apenas um pequeno número de esboços fornecidos pelo usuário e sem novas fotos de treinamento. Aborda o desafio de ter orientação do usuário fornecida por exemplos em um domínio de dados muito mais simples do que os dados de saída.
Rinon Gal, Or Patashnik, Haggai Maron, Amit Bermano, Gal Chechik, Daniel Cohen-Or. StyleGAN-NADA: Adaptação de domínio guiada por CLIP de geradores de imagens.
Notas: Introduz o uso de orientação em texto para alterar um modelo generativo sem fornecer novas imagens de treinamento. Altera os parâmetros do stylegan usando uma objetiva CLIP direcional que orienta as imagens do modelo modificado para terem diferenças específicas com as imagens do modelo original e seleciona camadas específicas para modificar com base em seu efeito na objetiva.
Como citar
Este trabalho apareceu no NeurIPS 2022. Pode ser citado da seguinte forma.
Bibliografia
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. “Locating and Editing Factual Associations in GPT.” Advances in Neural Information Processing Systems 36 (2022).
Bibtex
@article{meng2022locating,
title={Locating and Editing Factual Associations in {GPT}},
author={Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2022}
}
Tradução: Luan Marques
Link para o orginal