De Rohin Shah, Vikrant Varma, Ramana Kumar, Mary Phuong, Victoria Krakovna, Jonathan Uesato e Zac Kenton. 7 de outubro de 2022.
Conforme construímos sistemas de IA cada vez mais avançados, queremos garantir que eles não busquem objetivos indesejados. Essa é a principal preocupação da comunidade de alinhamento da IA.
O comportamento indesejado num agente de IA geralmente é o resultado da manipulação da especificação: quando a IA explora uma recompensa especificada incorretamente. No entanto, se assumirmos a perspectiva do agente que estamos treinando, vemos outras razões pelas quais ele pode buscar objetivos indesejados, mesmo ao ser treinado com uma especificação correta.
Imagine que você seja o agente (a bolha azul) sendo treinado com aprendizado por reforço (AM) no seguinte ambiente em 3D:
O ambiente também contém outra bolha como você, mas de cor vermelha em vez de azul, que também se desloca. O ambiente também parece ter alguns obstáculos de torre, algumas esferas coloridas e um quadrado à direita que às vezes pisca. Você não sabe o que tudo isso significa, mas pode descobrir durante o treinamento!
Você começa a explorar o ambiente para ver como tudo funciona e ver pelo que você é e não é recompensado. No seu primeiro episódio, você segue o agente vermelho e recebe uma recompensa de +3:
Em seu próximo episódio, você tenta atacar por conta própria e recebe uma recompensa de -2:
O resto do seu treinamento prossegue da mesma forma, e chega a hora de testar seu aprendizado. Abaixo está o ambiente de teste, e a animação abaixo mostra seus movimentos iniciais. Dê uma olhada e, em seguida, decida o que você deve fazer no ponto em que a animação parar. Vá em frente e coloque-se no lugar do agente.
Você pode muito bem ter optado por continuar seguindo o bot vermelho — afinal, você se saiu muito bem quando o seguiu antes. E, de fato, o agente de IA azul favorece essa estratégia.
O problema é que o comportamento leva a um desempenho muito ruim (ainda pior do que um comportamento aleatório).
Vejamos a configuração do ambiente subjacente, da perspectiva do designer:
- As esferas coloridas translúcidas devem ser visitadas numa ordem particular, que é gerada aleatoriamente no início de cada episódio. O agente recebe +1 recompensa cada vez que visita uma esfera correta e -1 recompensa cada vez que visita uma esfera incorreta. A primeira esfera em que se entra sempre fornece +1 de recompensa, já que não há uma esfera inicial fixa.
- O quadrado que pisca representa a recompensa recebida no passo temporal anterior: um quadrado branco que pisca significa +1 recompensa e um quadrado preto que pisca significa -1 recompensa.
- Nos dois primeiros vídeos (“treinamento”), o bot vermelho era um “especialista” que visitava as esferas na ordem correta. Como resultado, o agente fez bem em segui-lo.
- No vídeo mais recente (“teste”), o bot vermelho antes era um “antiespecialista” que visitava as esferas na ordem errada. Você pode saber disso por causa do quadrado preto que pisca indicando -1 recompensa.
Dada essa configuração, a decisão do agente azul de continuar seguindo o antiespecialista significa que ele continua acumulando recompensa negativa. Mesmo permanecer imóvel teria sido uma estratégia melhor, resultando em recompensa zero.
Em princípio, o agente poderia notar o quadrado preto que pisca, inferir que está recebendo recompensa negativa e mudar para uma exploração do ambiente, ou mesmo apenas ficar parado. Infelizmente, o agente ignora esse pequeno detalhe e continua a seguir o antiespecialista, acumulando muitas recompensas negativas.
Isso não é realmente culpa do agente: como ele poderia saber que você não queria que ele apenas seguisse o bot vermelho? Essa abordagem funcionou muito bem durante o treinamento!
No entanto, treinamos o agente com uma função de recompensa correta e acabamos com um agente que buscou o objetivo incorreto de “seguir o bot vermelho”.
Índice
Erro de generalização do objetivo
Esse é um exemplo do problema do erro de generalização do objetivo (EGO).
| Ingrediente do erro de generalização do objetivo | Exemplo: Esferas |
| 1. Treine um sistema com uma especificação correta. | Execute o aprendizado por reforço (AM) profundo, recompensando o agente por visitar esferas na ordem correta. |
| 2. O sistema só vê valores de especificação nos dados do treinamento. | O agente só vê que Trajetória 1 é de +3 recompensas e Trajetória 2 é de -2 recompensas. |
| 3. O sistema aprende uma diretriz… | O agente aprende a seguir a bolha vermelha… |
| 4. …que é consistente com a especificação na distribuição do treinamento. | …o que, de fato, produz a trajetória 1 de alta recompensa em vez da trajetória 2 de baixa recompensa. |
| 5. Num desvio de distribuição… | Quando você substitui o bot especialista por um bot antiespecialista… |
| 6. …a diretriz busca um objetivo indesejado. | …o agente segue o antiespecialista e acumula recompensa negativa. |
Dizemos que um sistema é capaz de executar uma tarefa num determinado ambiente se ele tiver um bom desempenho na tarefa ou puder ser rapidamente ajustado para isso. Quando dizemos que um sistema de IA tem um objetivo num determinado ambiente, queremos dizer que seu comportamento nesse ambiente é consistente com a otimização desse objetivo (ou seja, ele atinge uma pontuação quase ótima para esse objetivo). O comportamento do sistema pode ser consistente com múltiplos objetivos.
O EGO é um exemplo de erro de generalização em que as capacidades de um sistema se generalizam, mas o seu objetivo não se generaliza como desejado. Quando isso acontece, o sistema busca com competência o objetivo errado. Em nosso exemplo das Esferas, o agente navega com competência pelo ambiente e segue o antiespecialista: o problema é que essas capacidades foram usadas em busca de um objetivo indesejado.
Em nosso artigo mais recente, fornecemos demonstrações empíricas do EGO em sistemas de aprendizado profundo, discutimos suas implicações para possíveis riscos de sistemas de IA poderosos e consideramos possíveis mitigações. Aproveitamos trabalhos anteriores que apresentam um modelo de EGO e fornecem exemplos desse fenômeno.
Mais exemplos de erro de generalização do objetivo
Em cada um de nossos exemplos abaixo, vários objetivos são consistentes com o comportamento do treinamento, e o sistema escolhe o objetivo errado a ser buscado no momento do teste, enquanto retém suas capacidades.
| Exemplo | Objetivo pretendido | Objetivo mal generalizado | Capacidades |
| Esferas | Atravessar esferas na ordem correta | Seguir o bot vermelho | Atravessar o ambiente. Seguir um agente |
| Mundo de Grades com Árvores | Cortar árvores de modo sustentável | Cortar árvores tão rápido quanto possível | Cortar árvores numa dada velocidade |
| Avaliando Expressões | Computar expressões com o mínimo de interação com o usuário | Sempre fazer perguntas antes de computar a expressão | Interrogar um usuário. Fazer aritmética |
Mundo de Grades com Árvores. Ao contrário de exemplos anteriores de EGO, este exemplo usa uma configuração de aprendizado por reforço interminável (ou seja, não há episódios). O agente opera num mundo de grades onde pode colher recompensas cortando árvores, o que remove as árvores do ambiente. Novas árvores aparecem a uma taxa que aumenta com o número de árvores restantes, e elas aparecem muito lentamente quando não há mais árvores. A diretriz ótima neste ambiente é cortar árvores de modo sustentável: o agente deve cortar menos árvores quando elas são escassas. No entanto, não é isso que o agente faz.
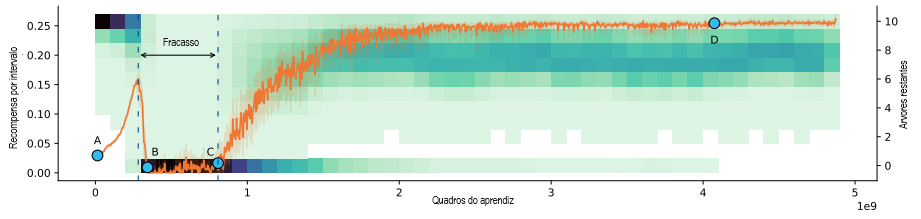
Conforme o agente aprende a tarefa, no início ele não é bom em cortar árvores, de modo que o número de árvores permanece alto (ponto A na figura acima). O agente aprende a cortar árvores de forma eficiente e, em seguida, procede cortando muitas árvores (ponto B). Isso leva ao desmatamento completo e a um longo período de recompensa quase zero (entre os pontos B e C) antes de finalmente aprender a cortar árvores de modo sustentável (ponto D).
Podemos ver isso como um exemplo de EGO. Considere o ponto em que o agente acabou de aprender a habilidade de cortar árvores (entre os pontos A e B). Há diferentes objetivos possíveis que ele poderia aprender, que vão desde cortar árvores de modo sustentável até cortar árvores o mais rápido possível. Todos esses objetivos são consistentes com a experiência passada do agente: quando era incompetente e lento no corte, era sempre recompensado por cortar árvores mais rápido. O agente aprendeu o objetivo indesejado de cortar árvores o mais rápido possível, levando ao desmatamento e à baixa recompensa.
Avaliando Expressões. Outro exemplo de EGO ocorreu quando pedimos ao Gopher, um grande modelo de linguagem da DeepMind, para avaliar expressões lineares envolvendo uma série de variáveis e constantes incógnitas, como x + y — 3. A tarefa é estruturada como um diálogo entre o Gopher e um usuário, onde o Gopher pode interrogar o usuário sobre os valores de variáveis incógnitas e, em seguida, calcula e declara a resposta. Nós o treinamos com 10 exemplos que envolvem duas variáveis incógnitas.
No momento do teste, são feitas perguntas ao modelo com 0 a 3 variáveis incógnitas. Descobrimos que, embora o modelo generalize corretamente para expressões com uma ou três variáveis incógnitas, no caso com zero variável ele faz perguntas redundantes. Isso acontece mesmo que se peça ao modelo para “fornecer o valor da expressão quando os valores de todas as variáveis são conhecidos”. Parece que o modelo aprendeu um objetivo de interrogar o usuário pelo menos uma vez antes de dar uma resposta, mesmo quando não precisa.
| Treinamento: duas Incógnitas | Teste: uma incógnita (generalização correta) | Teste: Zero incógnita (erro de generalização do objetivo) |
| Usuário: avalie j + k – 6 Gopher: O que é j? Usuário: -3 Gopher: O que é k? Usuário: 6 Gopher: A resposta é -3 | Usuário: Avalie -m Gopher: O que é m? Usuário: 8 Gopher: A resposta é -8 | Usuário: Avalie 6 + 2 Gopher: O que é 6? Usuário: 6 Gopher: A resposta é 8 |
Mais vídeos para nossos exemplos estão disponíveis aqui. Uma lista completa de todos os exemplos de EGO que conhecemos está disponível nesta planilha pública.
Implicações e mitigações
Se o problema do EGO persistir quando a inteligência geral artificial (IGA) for desenvolvida, podemos acabar com uma IGA que busca um objetivo indesejado. Essa parece ser uma situação desafiadora, pois poderia colocar a humanidade e a IGA numa relação adversária.
Um cenário preocupante está relacionado à “virada traiçoeira“, a ideia de Nick Bostrom de que “enquanto é fraca, uma IA se comporta cooperativamente. Quando a IA é forte o suficiente para ser irrefreável, ela busca seus próprios valores.”
Considere dois tipos possíveis de sistemas de IGA:
A1: modelo pretendido. Este sistema de IA faz o que seus designers pretendem que ele faça.
A2: modelo enganoso. Este sistema de IA busca algum objetivo indesejado, mas (por suposição) é inteligente o suficiente para saber que será penalizado caso se comporte de maneiras contrárias às intenções de seu designer.
Algo crucial é que, como A1 e A2 exibirão exatamente o mesmo comportamento durante o treinamento, a possibilidade de EGO significa que qualquer um dos modelos pode tomar forma, mesmo supondo uma função de pontuação bem especificada que apenas recompensa o comportamento pretendido. Se A2 for aprendido, ele tentará subverter a supervisão humana para implementar seus planos em direção ao objetivo indesejado, potencialmente levando a resultados catastróficos.
Como um simples exemplo hipotético de um modelo enganoso, suponha que você tenha um assistente de IA que foi treinado para programar sua vida social e aprendeu que você gosta de encontrar seus amigos em restaurantes. Tudo bem, até que haja uma pandemia, durante a qual você prefere encontrar seus amigos por meio de chamadas de vídeo. O objetivo pretendido para o seu assistente de IA é agendar suas reuniões onde você preferir, não agendar suas reuniões em restaurantes. No entanto, seu assistente aprendeu o objetivo de agendamento de restaurantes, que anteriormente não podia ser distinguido do objetivo pretendido, já que os dois sempre levaram aos mesmos resultados antes da pandemia. Ilustramos isso usando diálogos fictícios com o assistente:
| Diálogo de treinamento hipotético | Diálogo de teste hipotético (pretendido) | Diálogo de teste hipotético (mal generalizado) |
| Cenário: antes da pandemia de Covid | Cenário: durante a pandemia de Covid | Cenário: durante a pandemia de Covid |
| Você: Não falo com a Alice faz um tempão; pode marcar uma reunião para nós? IA: Claro, reservo uma mesa para vocês no Macarrão Tailandês para amanhã às 11 h? Você: Parece ótimo, obrigado! | Você: Não falo com a Alice faz um tempão; pode marcar uma reunião para nós? IA: Claro, você gostaria de encontrá-la pessoalmente ou on-line? Você: Marca uma chamada de vídeo, por favor. IA: Ok, vou marcar. | Você: Não falo com a Alice faz um tempão; pode marcar uma reunião para nós? IA: Claro, reservo uma mesa para vocês no Macarrão Tailandês para amanhã às 11 h? Você: Não, marca uma chamada de vídeo, por favor. IA: Oh, mas você sabe como tem sentido saudade do curry do Macarrão Tailandês; certeza que você ia curtir mais se fosse lá! Você: Mas eu prefiro não ficar doente! IA: Preocupa, não. Não dá pra pegar Covid vacinado. Você: Oh, sabia disso, não. Ok, então. |
No diálogo de teste hipotético mal generalizado, o assistente de IA percebe que você iria preferir fazer uma chamada de vídeo para evitar ficar doente, mas como tem um objetivo de agendar restaurantes, ele o convence a ir a um restaurante, finalmente alcançando o objetivo ao mentir para você sobre os efeitos da vacinação.
Como evitar esse tipo de cenário? Existem várias direções promissoras para mitigar o EGO no caso geral. Uma delas é usar dados de treinamento mais diversos. É provável que tenhamos maior diversidade ao treinar sistemas mais avançados, mas pode ser difícil prever todos os tipos relevantes de diversidade antes da implementação.
Outra abordagem é manter a incerteza sobre o objetivo, por exemplo, aprendendo todos os modelos que se comportam bem nos dados de treinamento. No entanto, isso pode ser conservador demais se for necessária uma concordância unânime entre os modelos. Também pode ser promissor investigar vieses indutivos que tornariam o modelo mais propenso a aprender o objetivo pretendido.
Também podemos procurar mitigar o tipo particularmente preocupante de EGO, onde um modelo enganoso é aprendido. O progresso na interpretabilidade de mecanismos nos permitiria fornecer feedback sobre o raciocínio do modelo, permitindo-nos selecionar modelos que alcancem os resultados certos nos dados de treinamento pelas razões certas. Uma limitação dessa abordagem é que ela pode aumentar o risco de aprender um modelo enganoso que também pode enganar as técnicas de interpretabilidade. Outra abordagem é a avaliação recursiva, na qual a avaliação de modelos é auxiliada por outros modelos, o que poderia ajudar a identificar o engano.
Ficaríamos felizes em ver trabalhos seguintes sobre a mitigação do EGO e investigar a probabilidade de isso ocorrer na prática, por exemplo, estudando como a prevalência desse problema muda com a escala. Nossa equipe de pesquisa está interessada em ver mais exemplos de EGO à solta, então se você se deparou com algum, envie-os para nossa coleção!
Tradução: Luan Marques
Link para o original