De Scott Garranbrandt e Abram Demski. 29 de outubro de 2018.
Suponha que você queira construir um robô para atingir algum objetivo do mundo real para você, um objetivo que exige que o robô aprenda por si mesmo e descubra muitas coisas que você ainda não sabe.
Há um problema complicado de engenharia aqui. Mas também há o problema de descobrir o que significa construir um agente de aprendizado como esse. O que é otimizar metas realistas em ambientes físicos? Em termos amplos, como funciona?
Nesta série de postagens, apontarei quatro modos como ainda não sabemos como funciona e quatro áreas de pesquisa ativa destinadas a descobrir isso.
Este é Alexei, e Alexei está jogando videogame.

Como a maioria dos jogos, este jogo possui canais de entrada e saída claros. Alexei só observa o jogo pela tela do computador e só manipula o jogo pelo controle.
O jogo pode ser pensado como uma função que recebe uma sequência de apertos de botões e exibe uma sequência de pixels na tela.
Alexei também é muito inteligente e capaz de manter todo o videogame dentro de sua mente. Se Alexei tiver alguma incerteza, será apenas sobre fatos empíricos, como o jogo que está jogando, e não sobre fatos lógicos, como que entradas (para um determinado jogo determinístico) produzirão quais resultados. Isso significa que Alexei também deve armazenar em sua mente todos os jogos possíveis que esteja jogando.
Alexei , entretanto, não precisa pensar em si mesmo. Ele está apenas otimizando o jogo que está jogando e não otimizando o cérebro que usa para pensar sobre o jogo. Ele ainda pode escolher ações com base no valor da informação, mas isso serve apenas para ajudá-lo a descartar possíveis jogos que esteja jogando e não para mudar a maneira como pensa.
Na verdade, Alexei pode tratar a si mesmo como um átomo imutável e indivisível. Como ele não existe no ambiente em que está pensando, Alexei não se preocupa se ele mudará com o tempo ou com nenhuma sub-rotina que possa ter que executar.
Observe que todas as propriedades de que falei são parcialmente possíveis pelo fato de Alexei estar claramente separado do ambiente que ele está otimizando.
Esta é Emmy. Emmy está jogando a vida real.
A vida real não é como um videogame. As diferenças vêm em grande parte do fato de Emmy estar dentro do ambiente que ela está tentando otimizar.
Alexei vê o universo como uma função e otimiza escolhendo entradas para essa função que levam a uma recompensa maior do que qualquer uma das outras entradas possíveis que ele possa escolher. Emmy, por outro lado, não tem uma função. Ela só tem um ambiente, e esse ambiente a contém.
Emmy quer escolher a melhor ação possível, mas a ação que Emmy escolhe realizar é apenas mais um fato sobre o ambiente. Emmy pode raciocinar sobre a parte do ambiente que é sua decisão, mas como há apenas uma ação que Emmy acaba realmente realizando, não está claro o que significa para Emmy “escolher” uma ação que seja melhor que as demais.
Alexei pode cutucar o universo e ver o que acontece. Emmy é o universo cutucando a si mesmo. No caso de Emmy, como sequer formalizamos a ideia de “escolher”?
Para piorar a situação, como Emmy está contida no ambiente, Emmy também deve ser menor que o ambiente. Isso significa que Emmy é incapaz de armazenar modelos detalhados e precisos do ambiente em sua mente.
Isso causa um problema: o raciocínio bayesiano funciona começando com uma grande coleção de ambientes possíveis e, à medida que você observa fatos que são inconsistentes com alguns desses ambientes, você os descarta. Como é o raciocínio quando você não é capaz de armazenar uma única hipótese válida sobre o modo como o mundo funciona? Emmy terá que usar um tipo diferente de raciocínio e fazer atualizações que não se enquadram na estrutura bayesiana padrão.
Como Emmy está dentro do ambiente que está manipulando, ela também será capaz de se autoaperfeiçoar. Mas como Emmy pode ter certeza de que, à medida que aprende mais e encontra mais e mais maneiras de melhorar, ela só muda de maneiras que são realmente úteis? Como ela pode ter certeza de que não modificará seus objetivos originais de maneira indesejável?
Finalmente, como Emmy está contida no ambiente, ela não pode tratar a si mesma como um átomo. Ela é feita das mesmas peças que compõem o resto do ambiente, o que a faz pensar sobre si mesma.
Além dos perigos em seu ambiente externo, Emmy terá que se preocupar com ameaças vindas de dentro. Durante a otimização, Emmy pode ativar outros otimizadores como sub-rotinas, intencionalmente ou não. Esses subsistemas podem causar problemas se ficarem muito poderosos e não estiverem alinhados com os objetivos de Emmy. Emmy deve descobrir como raciocinar sem criar subsistemas inteligentes ou, em outros sentidos, descobrir como mantê-los fracos, contidos ou totalmente alinhados com seus objetivos.
Emmy é confusa; então voltemos a Alexei. A estrutura AIXI de Marcus Hutter fornece um bom modelo teórico de como agentes como Alexei funcionam:
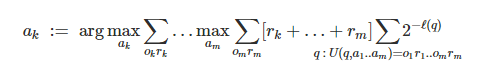
O modelo possui um agente e um ambiente que interagem por meio de ações, observações e recompensas. O agente envia uma ação a, e então o ambiente envia tanto uma observação o quanto uma recompensa r. Este processo se repete a cada momento k… m.
Cada ação é uma função de todos os trios ação-observação-recompensa anteriores. E cada observação e recompensa é igualmente uma função desses trios e da ação imediatamente anterior.
Você pode imaginar um agente nesta estrutura que tenha pleno conhecimento do ambiente com o qual está interagindo. No entanto, o AIXI é usado para modelar a otimização sob incerteza sobre o ambiente. O AIXI tem uma distribuição sobre todos os ambientes computáveis possíveis q e escolhe ações que levam a uma alta recompensa esperada sob essa distribuição. Como também se preocupa com recompensas futuras, isso pode levar à exploração do valor da informação.
Sob algumas suposições, podemos mostrar que o AIXI se sai razoavelmente bem em todos os ambientes computáveis, apesar da sua incerteza. No entanto, embora os ambientes com os quais o AIXI interage sejam computáveis, o próprio AIXI é incomputável. O agente é feito de um tipo de material diferente, um tipo de material mais poderoso do que o ambiente.
Chamaremos agentes como o AIXI e Alexei de “dualistas”. Eles existem fora de seu ambiente, com apenas interações definidas entre material de agente e material de ambiente. Eles exigem que o agente seja maior que o ambiente e não tendem a modelar o raciocínio autorreferencial, porque o agente é feito de um material diferente daquele sobre o qual o agente raciocina.
O AIXI não está sozinho. Essas suposições dualistas aparecem em todas as nossas melhores teorias atuais da agência racional.
Eu configurei o AIXI como uma espécie de contraste, mas o AIXI também pode ser usado como inspiração. Quando olho para o AIXI, sinto que realmente entendo como Alexei funciona. Esse é o tipo de compreensão que quero ter também para Emmy.
Infelizmente, Emmy é confusa. Quando falo sobre querer ter uma teoria da “agência integrada”, quero dizer que quero ser capaz de compreender teoricamente como funcionam agentes como Emmy. Ou seja, agentes que estão integrados a seu ambiente e, portanto:
- não possuem canais de e/s bem definidos;
- são menores que o seu ambiente;
- são capazes de raciocinar sobre si mesmos e de se autoaperfeiçoar;
- e são feitos de partes semelhantes ao meio ambiente.
Você não deveria pensar nessas quatro complicações como uma partição. Elas estão muito emaranhadas entre si.
Por exemplo, a razão pela qual o agente é capaz de se autoaperfeiçoar é que ele é feito de partes. E sempre que o ambiente for suficientemente maior que o agente, ele poderá conter outras cópias do agente e, assim, destruir quaisquer canais de e/s bem definidos.
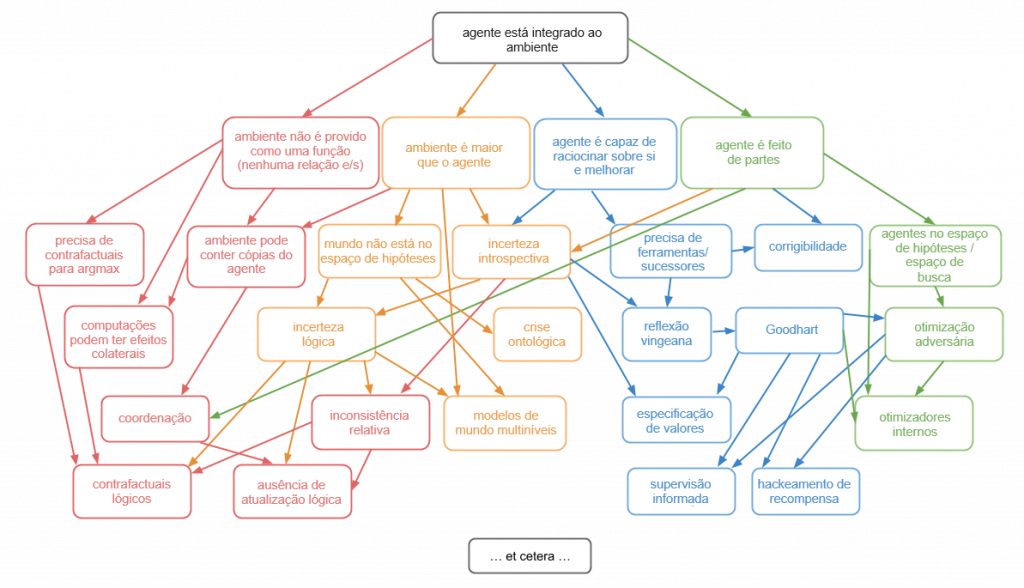
No entanto, utilizarei essas quatro complicações para inspirar uma divisão do tema da agência integrada em quatro subproblemas. São eles: teoria da decisão, modelos do mundo integrados, delegação resiliente e alinhamento de subsistemas.
A teoria da decisão trata da otimização integrada.
O modelo mais simples de otimização dualista é o argmax. argmax. O argmax. argmax pressupõe uma função de ações para recompensas e retorna a ação que leva à maior recompensa sob essa função. A maior parte da otimização pode ser considerada uma variante disso. Você tem algum espaço; tem uma função desse espaço para alguma pontuação, como uma recompensa ou utilidade; e deseja escolher uma entrada com pontuação elevada sob essa função.
Mas acabamos de dizer que grande parte do que significa ser um agente integrado é que você não tem um ambiente funcional. Então, o que fazemos agora? A otimização é claramente uma parte importante da agência, mas atualmente não podemos dizer o que ela é, mesmo na teoria, sem cometer grandes erros de tipo.
Alguns dos principais problemas em aberto na teoria da decisão incluem:
- Contrafactuais lógicos: como você raciocina sobre o que aconteceria se executasse ação B, visto que pode provar que, em vez disso, executará ação A?
- Ambientes que incluem múltiplas cópias do agente ou previsões confiáveis do agente.
- Falta de atualização lógica, que se trata de como combinar o mundo muito bom, porém muito bayesiano, da teoria da decisão sem atualização de Wei Dai, com o mundo muito menos bayesiano da incerteza lógica.
Modelos do mundo integrados tratam de como você pode criar bons modelos do mundo que sejam capazes de caber em um agente que é muito menor que o mundo.
Isso provou ser muito difícil, primeiro, porque significa que o verdadeiro universo não está no seu espaço de hipóteses, o que arruína muitas garantias teóricas; e segundo, porque significa que teremos que fazer atualizações não bayesianas à medida que aprendemos, o que também arruína muitas garantias teóricas.
Também trata de como fazer modelos do mundo do ponto de vista de um observador interno e dos problemas resultantes, como a antrópica. Alguns dos principais problemas em aberto em modelos do mundo integrados incluem:
- Incerteza lógica, que trata de como combinar o mundo da lógica com o mundo da probabilidade.
- Modelagem multinível, que trata de como ter vários modelos do mesmo mundo em diferentes níveis de descrição e fazer uma boa transição entre eles.
- Crises ontológicas, que é o que fazer quando você percebe que seu modelo, ou mesmo seu objetivo, foi especificado usando uma ontologia diferente da do mundo real.
A delegação resiliente trata de um tipo especial de problema do agente-principal. Você tem um agente inicial que deseja criar um agente sucessor mais inteligente para ajudá-lo a otimizar seus objetivos. O agente inicial tem todo o poder, porque decide exatamente qual agente sucessor criar. Mas, em outro sentido, o agente sucessor tem todo o poder, porque é muito, muito mais inteligente.
Do ponto de vista do agente inicial, a questão é criar um sucessor que não use a sua inteligência contra si de forma resiliente. Do ponto de vista do agente sucessor, a questão é: “Como você aprende ou respeita de forma resiliente os objetivos de algo que é estúpido, manipulável e nem sequer está usando a ontologia correta?”
Existem problemas extras provenientes do obstáculo löbiano, que tornam impossível confiar consistentemente em coisas que são mais poderosas do que você.
Você pode pensar sobre esses problemas no contexto de um agente que está apenas aprendendo ao longo do tempo, ou no contexto de um agente que está fazendo um autoaperfeiçoamento significativo, ou no contexto de um agente que está apenas tentando criar uma ferramenta poderosa.
Os principais problemas em aberto na delegação resiliente incluem:
- A reflexão vingiana, que trata de como raciocinar e confiar em agentes que são muito mais inteligentes que você, apesar do obstáculo löbiano à confiança.
- O aprendizado de valor, que é como o agente sucessor pode aprender os objetivos do agente inicial, apesar da estupidez e das inconsistências desse agente.
- A corrigibilidade, que trata de como um agente inicial pode fazer com que um agente sucessor permita (ou mesmo ajude com) modificações, apesar de um incentivo instrumental para não fazê-lo.
O alinhamento de subsistemas se trata de ser um agente unificado que não possui subsistemas lutando contra você ou entre si.
Quando um agente tem um objetivo, como “salvar o mundo”, ele pode acabar passando grande parte do tempo pensando em um subobjetivo, como “ganhar dinheiro”. Se o agente cria um subagente que está apenas tentando ganhar dinheiro, agora existem dois agentes com objetivos diferentes, e isso leva a um conflito. O subagente pode sugerir planos que parecem apenas gerar dinheiro, mas na verdade destroem o mundo para ganhar ainda mais dinheiro.
O problema é: você não precisa se preocupar apenas com subagentes que você cria intencionalmente. Você também precisa se preocupar com subagentes que você cria acidentalmente. Sempre que você realizar uma busca ou otimização em um espaço suficientemente rico que seja capaz de conter agentes, você terá que se preocupar com o próprio espaço fazendo a otimização. Essa otimização pode não estar exatamente alinhada com a otimização que o sistema externo estava tentando fazer, mas terá um incentivo instrumental para parecer que está alinhada.
Muitas otimizações na prática usam esse tipo de transferência de responsabilidade. Você não só encontra uma solução; você encontra algo que é capaz de buscar uma solução por si só.
Na teoria, eu absolutamente não entendo como fazer otimização, exceto métodos que parecem encontrar um monte de coisas que não entendo e ver se isso atinge meu objetivo. Mas esse é exatamente o tipo de coisa mais propensa a criar subsistemas adversários.
O grande problema em aberto no alinhamento de subsistemas é como ter um otimizador de nível básico que não acione otimizadores adversários. Você pode dividir esse problema ainda mais considerando casos em que os otimizadores resultantes são intencionais ou não intencionais e considerando subclasses restritas de otimização, como a indução.
Mas lembre-se: a teoria da decisão, os modelos do mundo integrados, a delegação resiliente e o alinhamento de subsistemas não são quatro problemas separados. São todos subproblemas diferentes do mesmo conceito unificado que é agência integrada.
Tradução: Luan Marques
Link para o original