Do EA Global. 3 de abril de 2020.
Paul Christiano, pesquisador da OpenAI , discute o estado atual da pesquisa sobre o alinhamento da IA com os valores humanos: o que está acontecendo agora, o que precisa acontecer e como as pessoas podem ajudar. Esta palestra cobre um amplo conjunto de subobjetivos na pesquisa de alinhamento, desde inferir preferências humanas até verificar as propriedades de sistemas avançados.
Uma transcrição da palestra, que editamos levemente pela maior clareza, está abaixo. Você também pode assistir à palestra de Paul no YouTube e lê-la em Effectivealtruism.org.
A palestra
Quando eu estava me preparando para esta palestra, cheguei à conclusão de que seria útil descrever como algumas das peças do alinhamento da IA se encaixam, e como elas se relacionam com o projeto mais amplo de fazer com que a IA vá bem.
Dito isso, vamos mergulhar. Estou amplamente interessado no problema de tornar bom o futuro da humanidade a longo prazo. Estou focando no subproblema dos efeitos da IA em nosso futuro a longo prazo e em como tornar esses efeitos positivos.
Mas mesmo dentro desse problema, existem muitos subproblemas diferentes nos quais podemos pensar separadamente. Acho que vale a pena ter alguma clareza conceitual [em torno desses problemas] e [apontar as] distinções [entre eles]. É por isso que há muito espaço vazio neste slide:

A parte do problema em que mais penso é o que chamo de alinhamento.
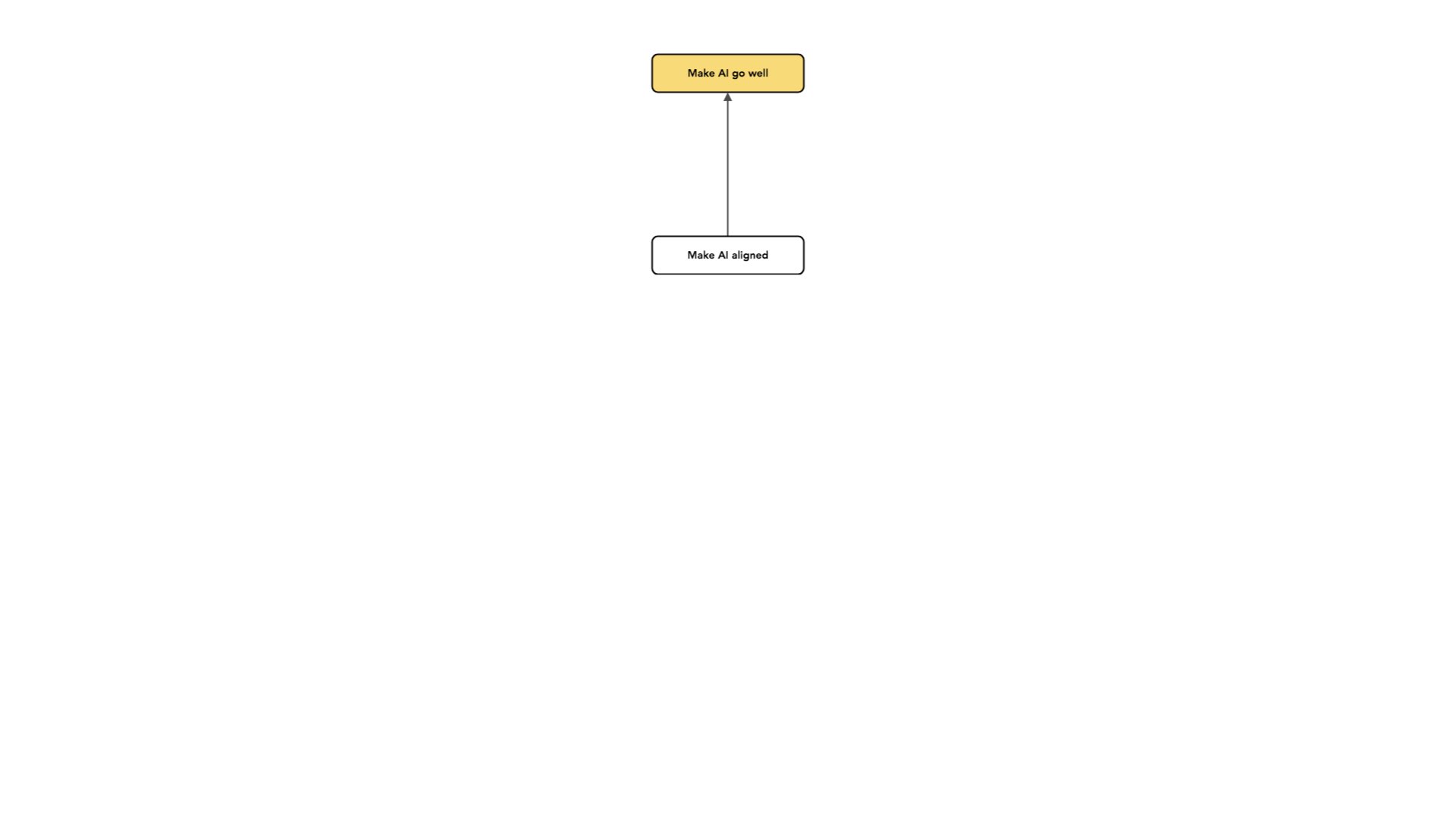
Uso o conceito de “alinhamento” de uma forma um pouco diferente das outras pessoas.

O que quero dizer é “alinhamento de intenções”, que consiste em tentar construir sistemas de IA que tentem fazer o que você deseja que eles façam. Em certo sentido, isso pode ser o mínimo que você deseja da sua IA: pelo menos ela está tentando. E o alinhamento de intenções é apenas uma peça para fazer com que a IA tenha um impacto positivo a longo prazo. Queremos evitar a situação em que os sistemas de IA funcionam de forma contrária à nossa e, à medida que se tornam mais competentes, fazem de forma mais eficaz coisas que não queremos que façam. Queremos que eles pelo menos tentem.

Existem muitos outros problemas nos quais poderíamos trabalhar com o mesmo tipo de intenção. Outra categoria de trabalho é tornar a IA mais competente. Algumas formas de competência são principalmente importantes no curto prazo, mas mesmo que nos concentremos exclusivamente no longo prazo, há tipos de competência com os quais nos preocupamos.

Um exemplo é querer que os nossos sistemas de IA tenham um desempenho confiável. Um sistema pode ser bem-intencionado, mas não confiável. E se meu sistema cometer erros, eles podem ser muito ruins. Por exemplo, imagine que esteja interessado na implementação de IA em situações de alto risco, como a tomada de decisões sobre armas nucleares. Posso pensar que é muito importante que esse novo sistema não falhe. Acho que esse é um problema muito importante, mas vale a pena separá-lo do problema de construir uma IA que tenta fazer o que queremos.
Algumas técnicas se aplicam a ambos os problemas. Mas, novamente, [vale a pena olhar para] um desses problemas e perguntar: “Como podemos resolver este aqui?” Acredito que [a confiabilidade é algo] que esperamos que melhore à medida que nossos sistemas de IA se tornem mais competentes. Assim, à medida que a IA melhora, os sistemas de IA ficam melhores na compreensão do mundo e ficam melhores em fazer o que estão tentando fazer. Esperamos que não cometer erros [acompanhe isso].
Vou examinar mais alguns exemplos de competências nas quais alguém poderia trabalhar na perspectiva de tentar tornar positivos os impactos de longo prazo da IA.
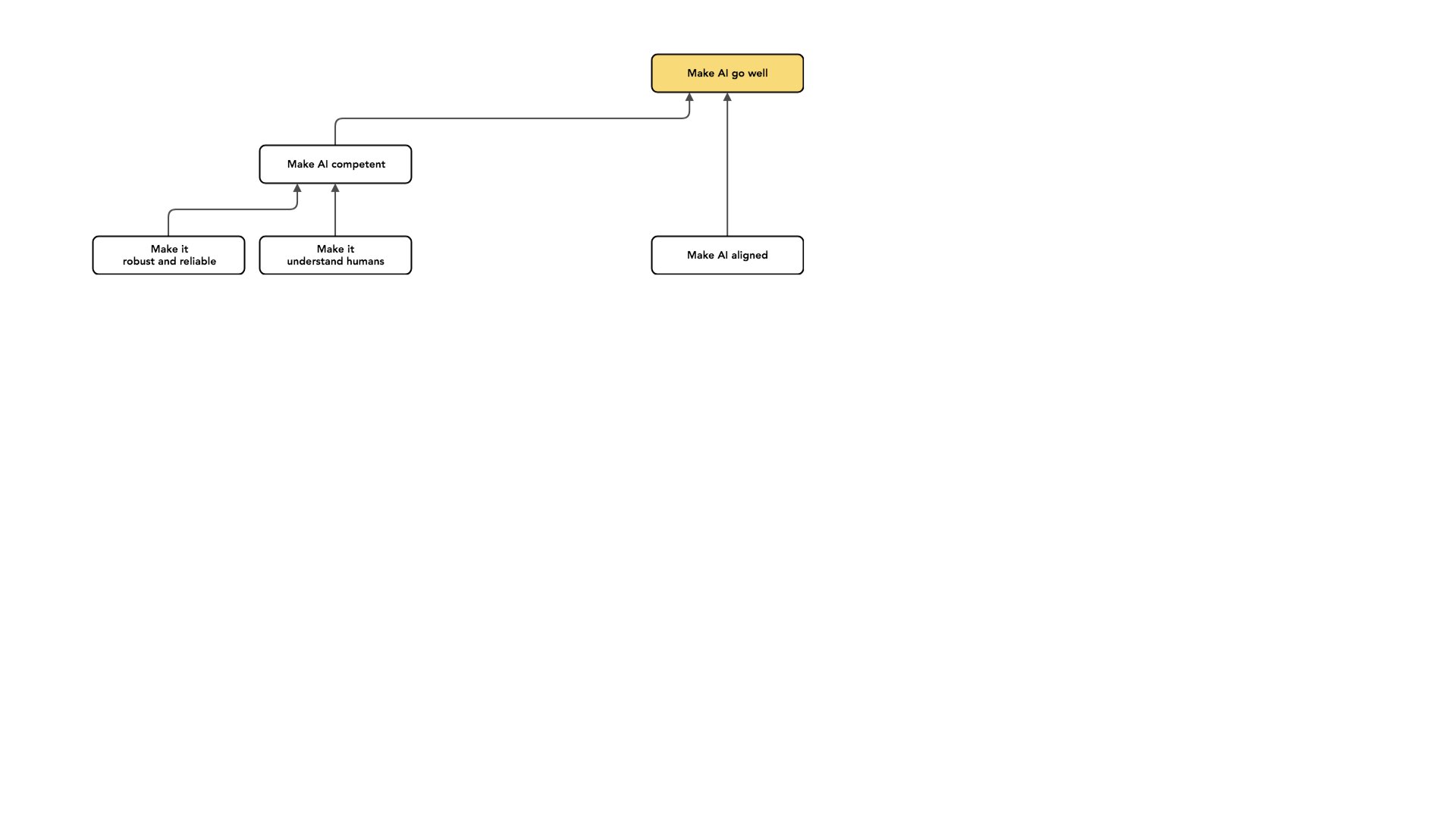
Estou escolhendo exemplos que parecem próximos do alinhamento de intenções para deixar claro o que não se enquadra neste título de alinhamento de intenções. Mais uma vez, porque penso que ter essa distinção em mente [entre alinhamento de intenções e competência] é útil para pensar sobre o trabalho nesta área.
Então, outro exemplo que talvez seja um pouco mais surpreendente é fazer com que sua IA entenda bem os humanos.

Ou seja, existe uma distinção potencial entre um sistema que é “bem-intencionado” (e está tentando fazer o que eu queria) e um sistema que me conhece bem. Se eu imaginar contratar um assistente, poderia ter um assistente que está tentando fazer a coisa certa, mas talvez não me entenda muito bem ou não tenhamos uma comunicação com largura de banda realmente alta, e esse é outro problema importante, mas separado. Ou seja, há uma distinção entre [uma IA bem-intencionada que está tentando conseguir o que pensa que eu quero] e [uma IA que realmente entende o que eu quero].
E eu trabalho principalmente no lado bem-intencionado disso, em vez do lado do “me conhece bem”. Uma das esperanças que motiva esse foco para mim: espero que você não precise de uma compreensão profunda do que os humanos desejam para evitar resultados catastróficos e ruins.
Se eu imaginar um cenário em que um sistema de IA esteja trabalhando ativamente contra os humanos, [eu poderia pensar em] ladrilhar o universo com clipes de papel como um exemplo absurdo, e talvez em [um exemplo menos extremo, uma IA] não permitir que os humanos tenham espaço para obter o que eles querem, ou para descobrir o que querem e, finalmente, conseguir.
Evitar esse caso envolve uma compreensão mínima do que os humanos desejam. Envolve compreender que os humanos não querem ser mortos. Os humanos não querem que você pegue todas as coisas deles e fuja. Esses são fatos importantes que [esperamos que a IA compreenda desde o início, à medida que progredimos na construção de sistemas mais sofisticados]. Quando digo que uma IA está tentando fazer o que eu quero, [quero dizer] que ela está tentando fazer o que [pensa que] Paul quer. Não é tentar fazer o que Paul de fato quer.
OK. Então esse é um exemplo de competência, que considero importante e que quero manter separado.

Outro exemplo que talvez seja surpreendente é a distinção entre tornar a nossa IA boa e fazer a nossa IA nos ajudar a tornar bons os sistemas de IA subsequentes. Ou seja, estamos lidando com essa transferência para sistemas de IA agora.
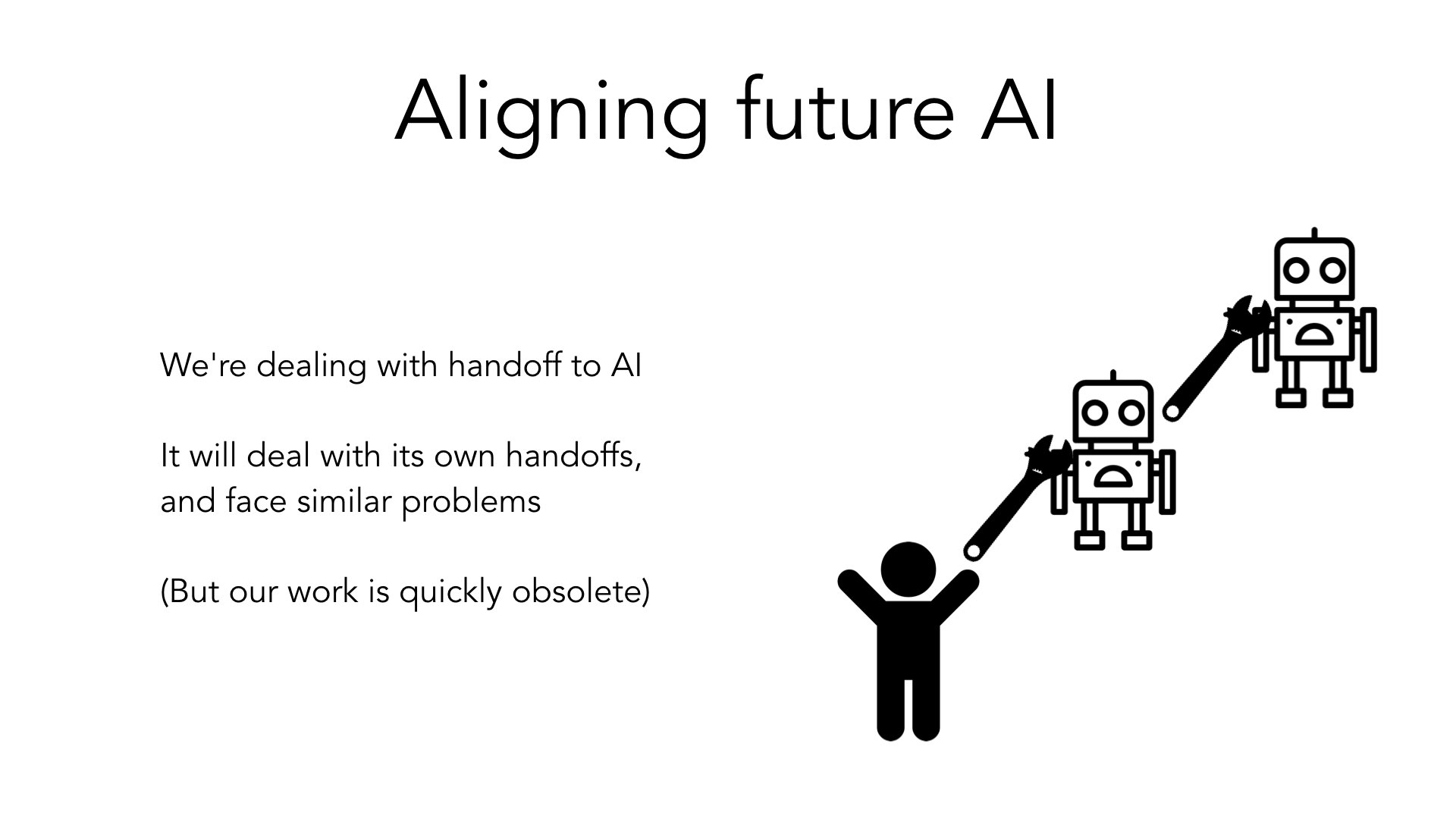
Estaremos construindo sistemas de IA que tomarão algumas decisões em nosso nome. O sistema de IA que construímos nos ajudará a projetar futuros sistemas de IA – ou, em algum momento, a projetar futuros sistemas de IA por conta própria. E enfrentará seus próprios problemas semelhantes enquanto [trabalha na construção de IA alinhada].
Então você poderia imaginar um caso em que construímos uma IA que está fazendo o que queremos, mas depois erramos e construímos outro sistema de IA que não está fazendo o que [o primeiro sistema de IA queria]. E estou novamente distinguindo este problema do desafio que enfrentamos agora nesta primeira transferência, e estou pensando apenas nesta primeira transferência [de humanos para IA, em vez de IA para outra IA].
Esses problemas são semelhantes. Espero também que essa investigação ajude futuros sistemas de IA a construir sistemas de IA subsequentes que estejam alinhados com os seus interesses. Mas penso que o nosso trabalho cognitivo neste momento poderá rapidamente se tornar obsoleto quando pensarmos em sistemas muito mais sofisticados do que nós. E então estou realmente me concentrando nesse desafio [a transferência humano-IA], uma espécie de primeiro desafio que enfrentamos, o primeiro passo dessa dinâmica. Portanto, tudo isso está na categoria de tornar a IA capaz.
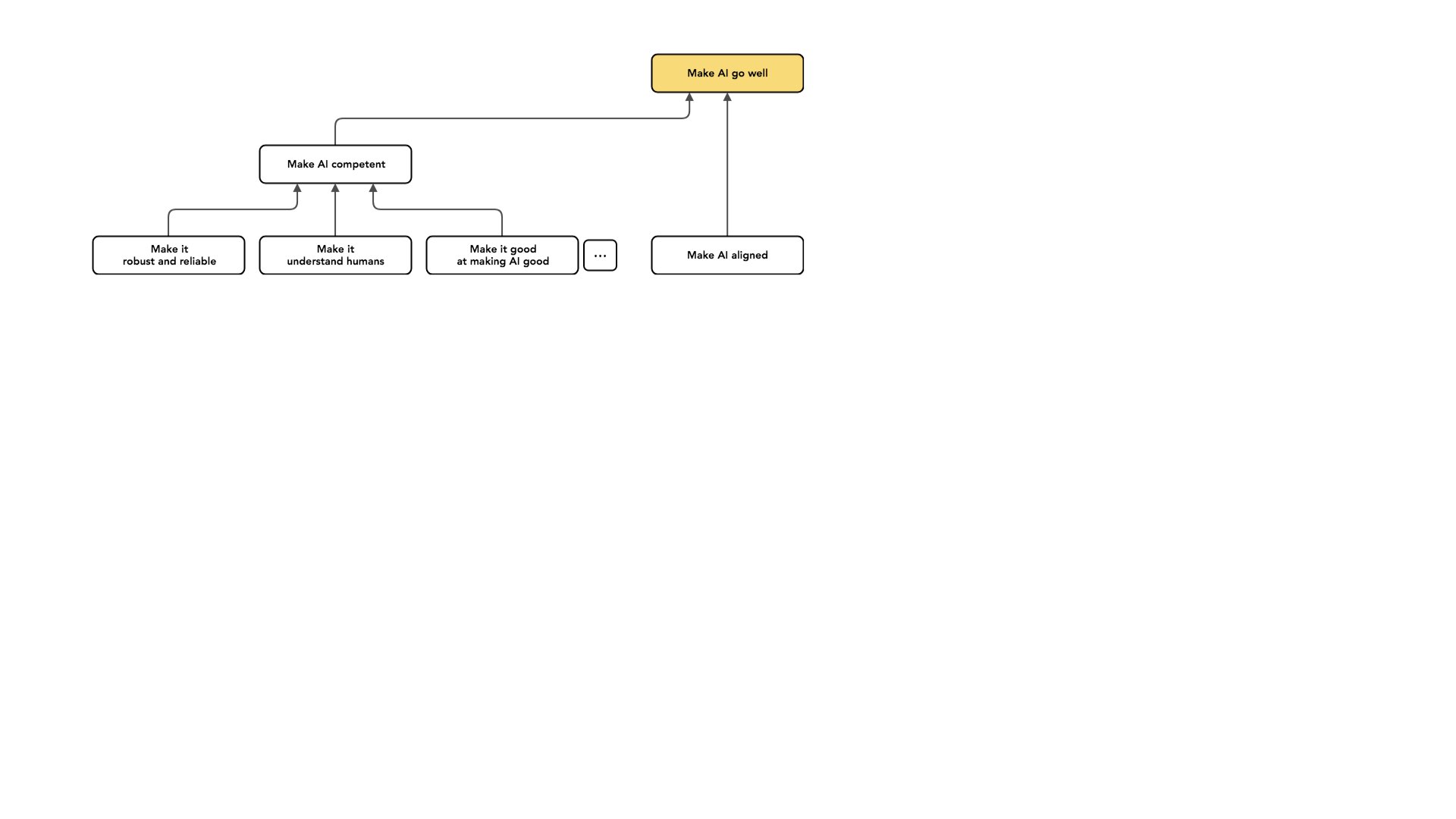
Acho que separar esses problemas dos problemas de alinhamento é importante para expressar por que vejo o alinhamento como um tipo de problema bem definido que estou otimista que podemos resolver totalmente. Isso ocorre em parte porque estou disposto a dizer que [resolver as transferências] é um problema mais restrito do que o problema geral de fazer a IA ir bem. E espero que muitas dessas [questões] do lado da competência melhorem à medida que a IA melhora. Estou escolhendo alinhamento [em vez de competência] em parte porque acho que é o aspecto do problema que provavelmente não melhorará à medida que a IA melhorar.

Há toda uma categoria separada de trabalho: em vez de mudar a forma como a minha IA se comporta ou o que a minha IA faz, também posso tentar lidar com os impactos dos sistemas de IA.
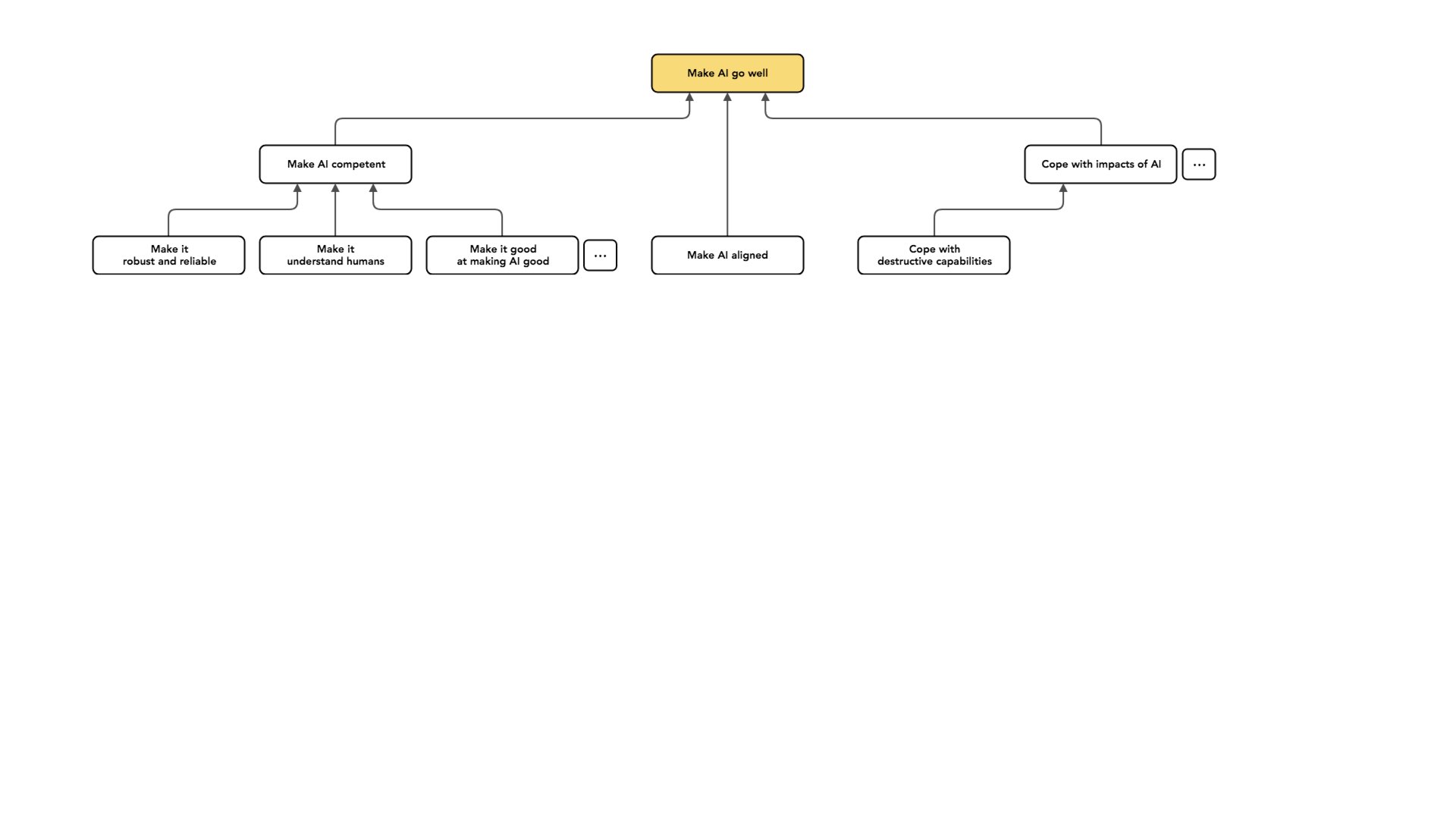
Por exemplo, os sistemas de IA podem permitir novas capacidades destrutivas, como talvez nos permitir fabricar bombas melhores ou fabricar bombas realmente grandes e mais baratas. Talvez eles nos permitam projetar armas biológicas, algo nesse sentido. Posso dizer que [essas capacidades] exigem novas abordagens à governança, mas quero manter essas [considerações] separadas do trabalho sobre o caráter da IA.
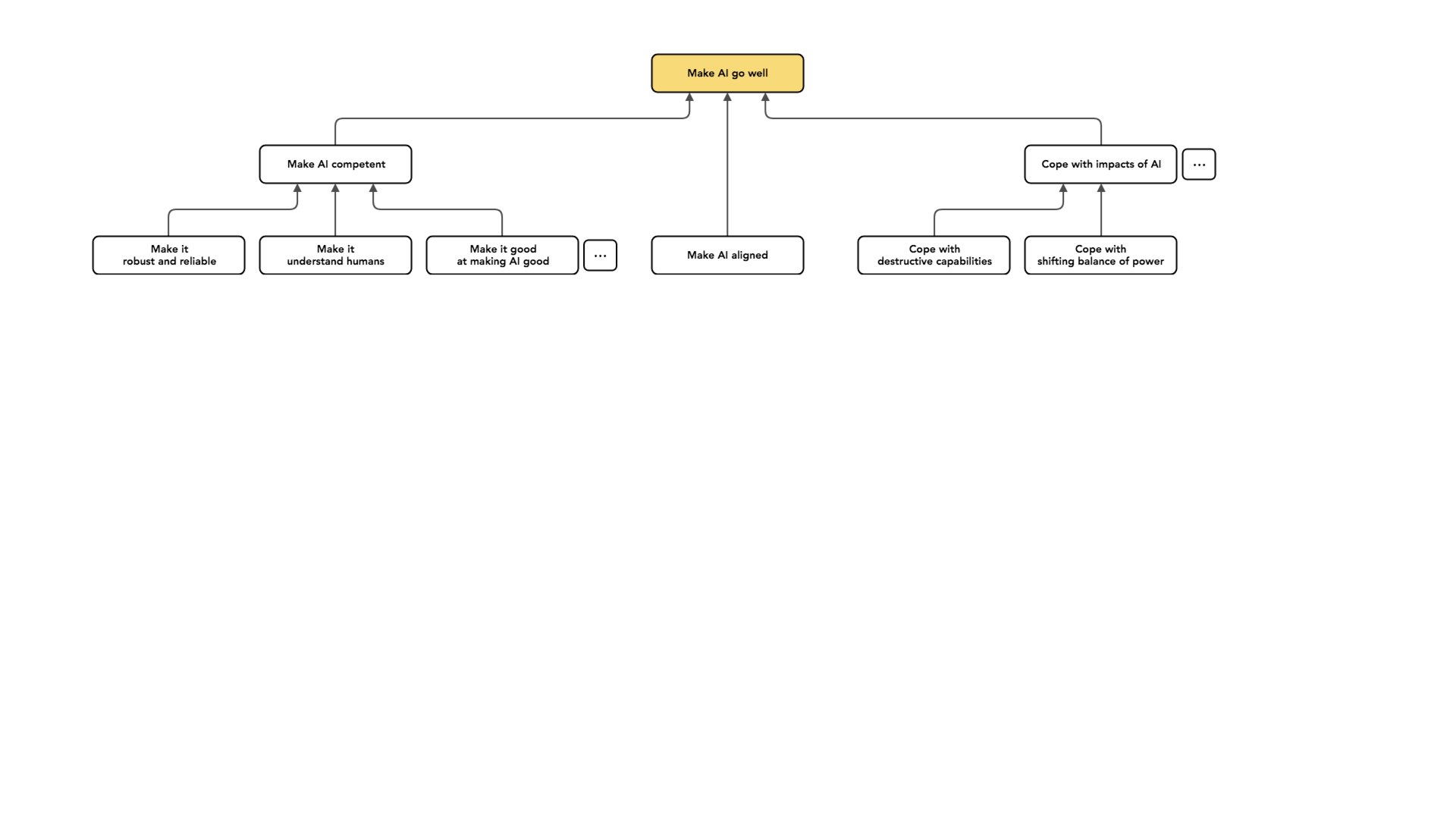
Da mesma forma, a IA pode causar mudanças no equilíbrio de poder. Pode permitir certos tipos de uso indevido.
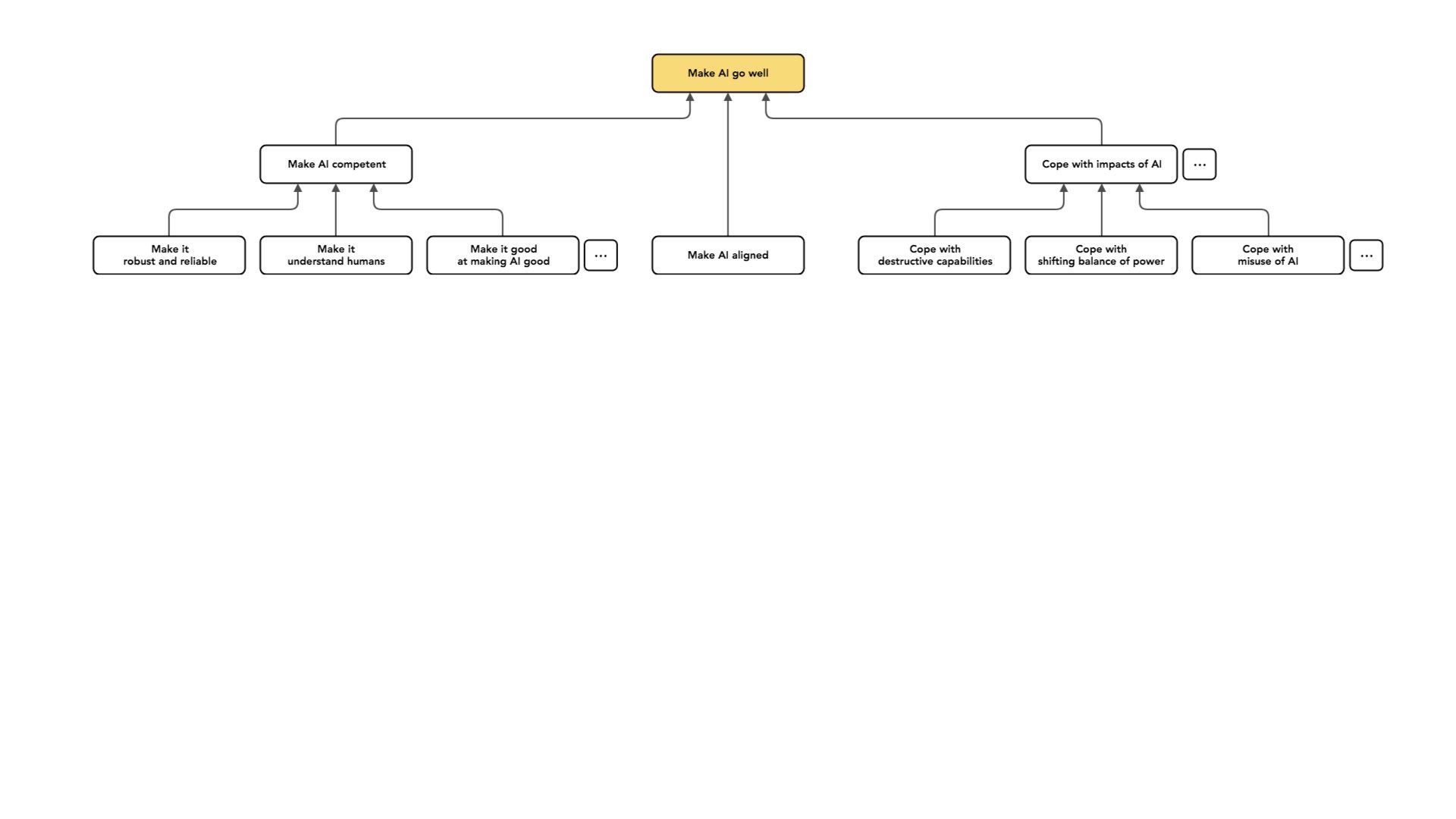
Digamos que talvez os criminosos atualmente tenham dificuldade em se coordenar; isso se torna mais fácil num mundo que requer apenas capital [para comprar sistemas de IA que podem facilitar o crime], ou talvez os regimes totalitários tenham mais facilidade em permanecer no poder sem pessoas que os apoiem se cada vez mais tarefas forem automatizadas.
E há muitos pontinhos neste gráfico [veja o slide acima] porque todos esses nós cobrem apenas uma parte muito pequena do espaço total possível. Acho que estas são algumas das grandes áreas em que as pessoas trabalham: tornar a nossa IA mais competente, alinhá-la para que pelo menos tente fazer a coisa certa e lidar com os impactos da IA. Todos são como projetos diferentes nos quais podemos nos envolver para tentar fazer com que a IA vá bem.

Uma vez que eu disse que tantas coisas não são alinhamento da IA, uma questão natural pode ser: como poderíamos falhar neste problema? O que poderia dar errado?
Um exemplo de algo que pode dar errado é que, quando treinamos sistemas de aprendizado de máquina, muitas vezes usamos algum objetivo mensurável para dizer quais diretrizes estão funcionando melhor ou pior. E você pode acabar com sistemas de IA que, em vez de tentarem fazer o que eu quero, estão tentando otimizar os tipos de objetivos mensuráveis que utilizo durante o treinamento. Então esse é um exemplo de uma possível falha. E se o que quero não for mensurável, posso ter esta restrição imposta pela natureza da tecnologia, que [torna muito mais fácil construir sistemas que buscam objetivos mensuráveis do que os objetivos não mensuráveis que quero atingir].
Outra possível falha é que pode haver diferentes tipos de valores que se comportam bem nos casos históricos que uso para treinar um sistema de IA [mas não funcionariam bem para aplicações do mundo real], o que poderia levar [o sistema a agir de formas absurdas.]. O aprendizado de máquina pode me dar, em certo sentido, uma extração aleatória de alguma distribuição de valores, e então eu posso ficar infeliz porque a maioria das extrações aleatórias de valores não são [semelhantes aos] meus.
Vou aumentar o zoom.

Para pensar em dividir ainda mais esse problema, vou usar uma abstração. Acho que isso vem de Eliezer [Yudkowsky ], embora não tenha certeza. Gosto desta noção de “imposto de alinhamento” – a linguagem, pelo menos, vem de Eliezer.

O que quero dizer com isso é que todos prefeririam ter sistemas de IA que tentassem fazer o que eles querem que [os sistemas] façam. Quero que minha IA tente me ajudar. A razão pela qual posso fazer uma concessão é se houver alguma tensão entre ter uma IA que está tentando fazer o que eu quero de forma resiliente e ter uma IA que seja competente ou inteligente. E a taxa de alinhamento tem a intenção de capturar essa lacuna: aquele custo em que incorrerei se insistir no alinhamento.
Você pode imaginar que tenho dois atores, Alice e Beto. Alice realmente deseja ter uma IA que tente fazer o que ela deseja. Beto está apenas disposto a ter uma IA que ganhe tanto dinheiro quanto possível. Você pode pensar que, se ganhar dinheiro é um subobjetivo instrumental para Alice [ajudá-la a conseguir o que deseja], Alice gostaria que sua IA ganhasse mais dinheiro [apenas] a serviço de ajudá-la a alcançar o que deseja. Assim, Alice enfrenta algum custo indireto por insistir que sua IA realmente tente fazer exatamente o que ela quer, e a taxa de alinhamento captura esse custo indireto.
O melhor caso é um mundo em que não temos imposto de alinhamento: [nesse mundo, não há] razão para alguém implementar uma IA que não esteja alinhada.
O pior caso é que não temos como construir IA alinhada; então Alice fica reduzida a apenas fazer as coisas sozinha e esse mundo tem uma taxa de alinhamento gigante [você perde todo o valor de usar IA se não usar sistemas não alinhados ].
Na realidade, provavelmente estaremos em algum lugar entre esses dois extremos. Portanto, poderíamos imaginar duas abordagens para alinhar os sistemas de IA:
1. Reduzir a taxa de alinhamento, de modo que Alice tenha que incorrer em menos custos se insistir em que sua IA esteja alinhada.
2. Pagar a taxa de alinhamento. Se eu simplesmente aceitar que será difícil construir uma IA alinhada, posso simplesmente pagar esse custo.

Falarei principalmente sobre a redução do imposto de alinhamento, mas apenas para detalhar algumas opções sobre o pagamento do imposto de alinhamento:
Você pode imaginar que uma classe de estratégias é apenas importar-se o suficiente para pagar o imposto. Portanto, se você é um desenvolvedor de IA ou um consumidor de IA, você pode pagar algum custo para usar IA alinhada, e essa é uma maneira de melhorar o futuro a longo prazo [apoiando o surgimento de sistemas que não apresentam um perigo tão grande à medida que se tornam mais poderosos].
Você também pode tentar influenciar quais pessoas estão em posição de fazer essas escolhas. Portanto, você poderia [tentar ajudar as pessoas que se preocupam com o alinhamento a obter posições-chave no desenvolvimento/regulamentação da IA, ou encontrar pessoas que já estão nessas posições e convencê-las a se preocupar com o alinhamento.]
Outra opção é tentar coordenar. Portanto, se Alice e Beto estão nessa posição, ambos prefeririam ter sistemas de IA que fizessem o que eles querem, mas talvez tenham feito esta concessão: ambos poderiam simplesmente concordar. Alice poderia dizer: “Olha, Beto, só implementarei uma IA que não esteja fazendo exatamente o que quero se você implementar tal IA”.
Se nós dois continuarmos insistindo na IA alinhada, estaremos (grosso modo) de volta ao ponto de partida. E talvez isso possa tornar a taxa de alinhamento menos dolorosa. Você pode imaginar que isso desse algum trabalho; você está elaborando acordos que podem tornar menos doloroso o pagamento desse imposto e, em seguida, aplicando esses acordos.

É nisso que me concentro principalmente: como podemos fazer um trabalho técnico que reduza a taxa de alinhamento. Você poderia imaginar vários tipos diferentes de abordagens a esse problema. Vou falar sobre dois.
Uma é a ideia de ter alguma visão sobre quais algoritmos são mais fáceis ou mais difíceis de alinhar.
Então, por exemplo, eu poderia ter uma visão do tipo: poderíamos construir IA tendo sistemas que realizam inferências e modelos que entendemos que têm crenças interpretáveis sobre o mundo e então agir de acordo com essas crenças, ou eu poderia construir sistemas tendo caixas-pretas opacas e otimizando essas caixas-pretas. Posso acreditar que o primeiro tipo de IA é mais fácil de alinhar; por isso uma forma de reduzir a taxa de alinhamento é simplesmente avançar com nesse tipo de IA, que espero que seja mais fácil de alinhar.
Essa não é uma visão muito incomum entre os acadêmicos. Também pode ser familiar aqui porque eu diria que descreve a visão do MIRI; a organização meio que presume a perspectiva de que alguns tipos de IA parecem difíceis de alinhar. Queremos construir um entendimento tal que possamos construir o tipo de IA que seja mais fácil de alinhar.
Na verdade, essa não é a abordagem sobre a qual vou falar ou não é a perspectiva que normalmente assumo.
Normalmente, em vez disso, faço uma pergunta que supõe que temos esse tipo de algoritmo; suponha que tenhamos as caixas-pretas. Existe alguma maneira de projetarmos uma variante desses algoritmos que seja alinhável, de modo que capture ou funcione tão bem quanto o algoritmo original destacado, mas que esteja alinhado?
Sendo um pouco mais preciso sobre isso, vejo o objetivo da maior parte da minha pesquisa como começar com um algoritmo X que está potencialmente desalinhado (p. ex., aprendizado por reforço profundo). Estou então tentando projetar um novo algoritmo, “align(X)”, que esteja alinhado à intenção, quase tão útil quanto X e [tão facilmente amplificável] quanto X. Essa é a situação em que eu gostaria de estar.
Se você estiver nessa situação, então Alice, que deseja ter uma IA alinhada, pode fazer a mesma coisa que Beto. Mas toda vez que Beto usaria esse algoritmo X potencialmente desalinhado, Alice usaria X alinhado, ao invés disso. Esse é o mundo aonde eu quero chegar.
Penso que a característica saliente deste plano é essa ideia de amplificabilidade. Você pode imaginar que tem duas opções para alinhar a IA.

1. Uma delas é que, à medida que a IA melhora, continuamos a fazer um trabalho contínuo para garantir que a IA esteja alinhada, e a taxa de alinhamento consiste então em quanto trabalho extra temos que fazer para tornar essa IA alinhável o estado da arte.
2. A segunda abordagem seria resolver de forma amplificável o alinhamento para um algoritmo específico. Então, eu poderia dizer que não me importo com quão bom ou profundo o aprendizado por reforço pode ser; eu sei que, independentemente disso, posso [aplicar uma transformação ao algoritmo] e acabar com uma versão alinhada. E agora a taxa de alinhamento depende dos custos indiretos dessa transformação.
Em geral, a opção 2 é ótima se for possível, mas não está claro se é possível. Talvez isso dependa de quão ampla é a categoria à qual estou me referindo quando digo] “algoritmo”.
Não espero ter uma solução que funcione para qualquer tipo possível de algoritmo de IA. Vou olhar para algoritmos específicos e dizer: “Posso formar uma versão alinhada deste algoritmo?” e espero que, à medida que novos algoritmos apareçam, eu consiga alinhá-los.
Nessa categoria, o problema agora se divide pelo tipo de algoritmo que desejo alinhar.
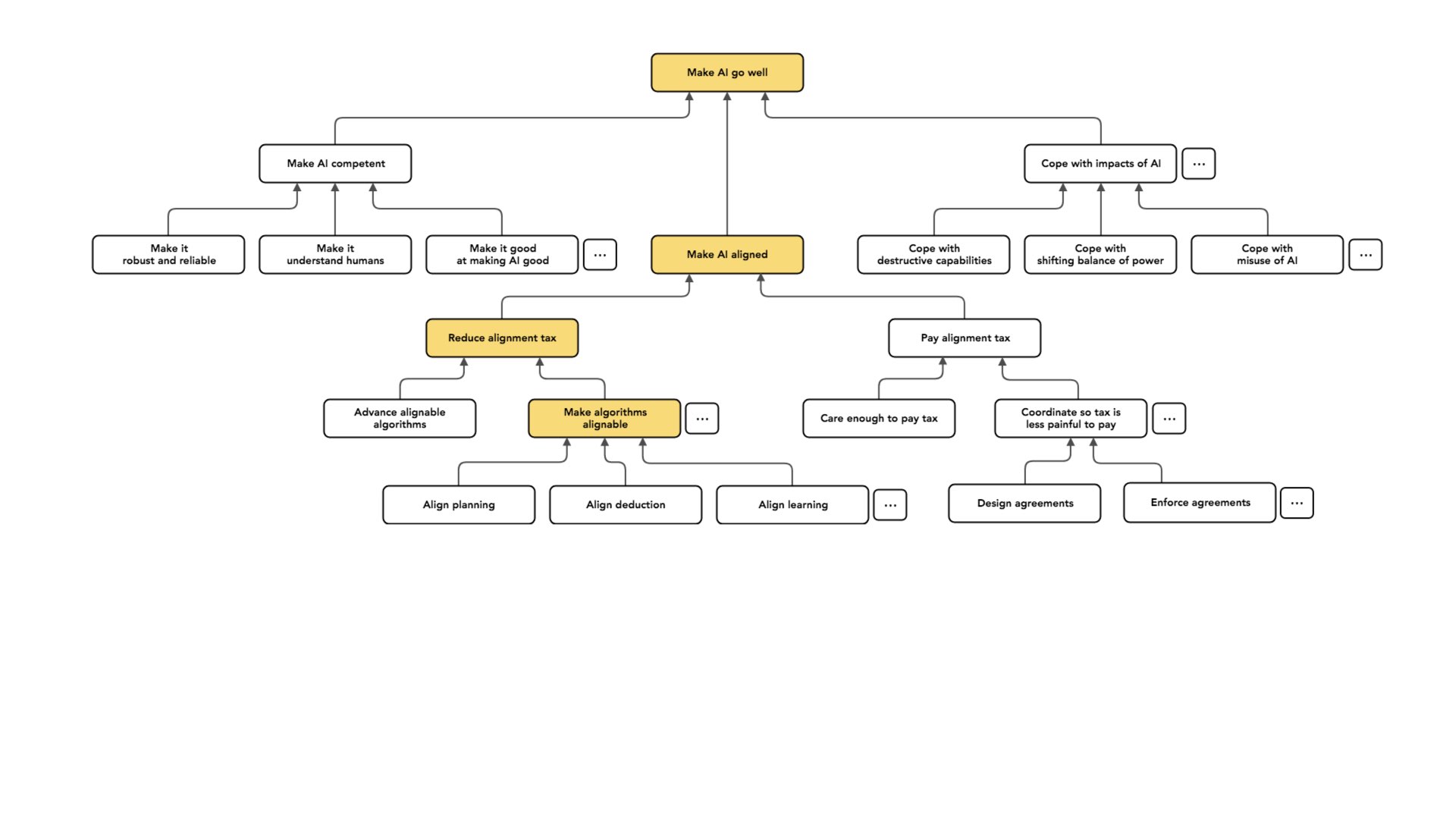
Por exemplo, vou falar sobre planejamento como ingrediente algorítmico. Assim, um agente pode planejar no sentido de buscar ações ou espaços de ações para encontrar ações que se prevê que tenham bons efeitos e então executar as ações que ele prevê que terão bons efeitos.
Isso é como um algoritmo. É um bloco de construção algorítmico muito simples. Ele introduz potenciais [obstáculos ao] alinhamento se houver uma incompatibilidade entre o que eu quero e o padrão que uma IA usa para avaliar os efeitos previstos. Também introduz potencialmente incompatibilidades: por exemplo, se houver alguma teoria da decisão implícita nesse algoritmo de planejamento que eu acho que não captura a maneira correta de tomar decisões.
Então, tenho este problema: posso encontrar uma versão de planejamento que seja tão útil quanto o planejamento que eu poderia ter feito de outra forma, mas que agora esteja alinhado e amplificado da mesma forma?
Da mesma forma, há um belo algoritmo de dedução no qual começo a partir de um conjunto de premissas e depois uso regras de inferência válidas para chegar a novas crenças. E posso perguntar: existe alguma versão de dedução que evite falhas de alinhamento? As falhas de alinhamento na dedução podem ser um pouco mais sutis. Não vou falar sobre elas. E então outro algoritmo, que se destaca agora e é o assunto principal da minha pesquisa, é o aprendizado, que é como planejamento no nível meta.
Então, em vez de pesquisar ações para encontrar uma que seja boa, terei uma maneira de avaliar se uma possível diretriz é boa (p. ex., jogando vários jogos com essa diretriz e vendo [se a IA que executa essa diretriz] vence). E então pesquisarei diretrizes (p. ex., pesos para minha rede neural) para encontrar uma diretriz com bom desempenho e usarei essa diretriz para tomar decisões no futuro.
É isso que quero dizer com aprender. E isso novamente introduz o desafio de saber se existe alguma maneira de pegar um algoritmo que está potencialmente desalinhado e criar uma versão alinhada de aprendizado. É sobre isso que falaremos durante o resto do tempo. Esse é o foco da minha pesquisa.

Vou novamente pegar emprestado do MIRI e falar sobre uma distinção neste problema – que considero importante e que realmente ajuda a organizar o pensamento – entre “alinhamento externo” e “alinhamento interno”.

Grosso modo, o que quero dizer com “alinhamento externo” é encontrar um objetivo que incentive um comportamento alinhado. Assim, quando executo um processo de aprendizado, tenho alguma forma de avaliar quais as diretrizes que são boas e quais as que são ruins, e escolho uma diretriz que seja boa de acordo com esse objetivo.
A primeira parte do problema é conceber esse objetivo de modo a captar aquilo que me interessa, suficientemente bem para que uma diretriz que tenha um bom desempenho relativamente ao objetivo seja realmente boa. Então, aqui, meu modo de falha se parece com a lei de Goodhart, na qual tenho um comportamento que não é realmente bom, mas parece bom de acordo com este indicador que estou usando. Parece bom de acordo com o padrão que estou usando para avaliar.
Por exemplo, tenho um conselheiro. Esse conselheiro está me dando conselhos. Talvez eu escolha diretrizes para obter conselhos com base em quão bons parecem os conselhos que ele produz e acabe com conselhos ruins apenas otimizados para parecerem bons para mim. Esse é o modo de falha do alinhamento externo. O problema é projetar um objetivo que capture bem o que eu quero.
Depois, há a segunda metade do problema, que é um pouco mais sutil, chamada “alinhamento interno”: garantir que a diretriz que adotamos busque de forma resiliente o objetivo que utilizamos para a selecioná-la.
O que quero dizer com isso é… bem, começarei novamente com uma analogia de que o MIRI gosta muito, na qual os humanos foram selecionados ao longo de muitas gerações para produzir um grande número de descendentes. Mas, na verdade, os humanos não são motivados principalmente no dia a dia a terem muitos descendentes. Então, em vez disso, os humanos têm uma mistura complicada de valores com os quais nos preocupamos – arte, alegria, florescimento e assim por diante – que por acaso estava [suficientemente bem correlacionada com a sobrevivência] no ambiente evolutivo que tornar-nos melhores na busca pelas coisas que desejamos nos fazia ter mais descendentes.
Mas se você colocar um humano em alguma situação muito nova, ele não continuará realizando as ações que promovem o número máximo de descendentes. Existem condições nas quais os humanos dirão: “Olha, essa ação vai fazer com que eu tenha mais descendentes, mas não me importo. Será muito sem graça. Em vez disso, vou fazer a coisa divertida.”
Do nosso ponto de vista, isso é bom, porque gostamos de diversão! Do ponto de vista da evolução, talvez isso seja uma pena se ela está tentando obter um grande número de descendentes.
Você pode imaginar enfrentar um problema semelhante no ambiente de aprendizado. Você poderia selecionar uma diretriz que tivesse um bom desempenho na distribuição, mas pode ser que essa diretriz esteja tentando fazer algo [diferente do que você queria]. Poderão existir muitas diretrizes diferentes que tenham valores que conduzam a um comportamento razoavelmente bom na distribuição de treinamento, mas então, em certas situações novas, fazem algo diferente do que eu quero.
Isso é o que quero dizer com alinhamento interno. (Novamente, minha pesquisa se concentra principalmente no alinhamento externo.)

Vou falar um pouco sobre as técnicas que mais me animam com o alinhamento interno. Um exemplo é o treinamento adversário.
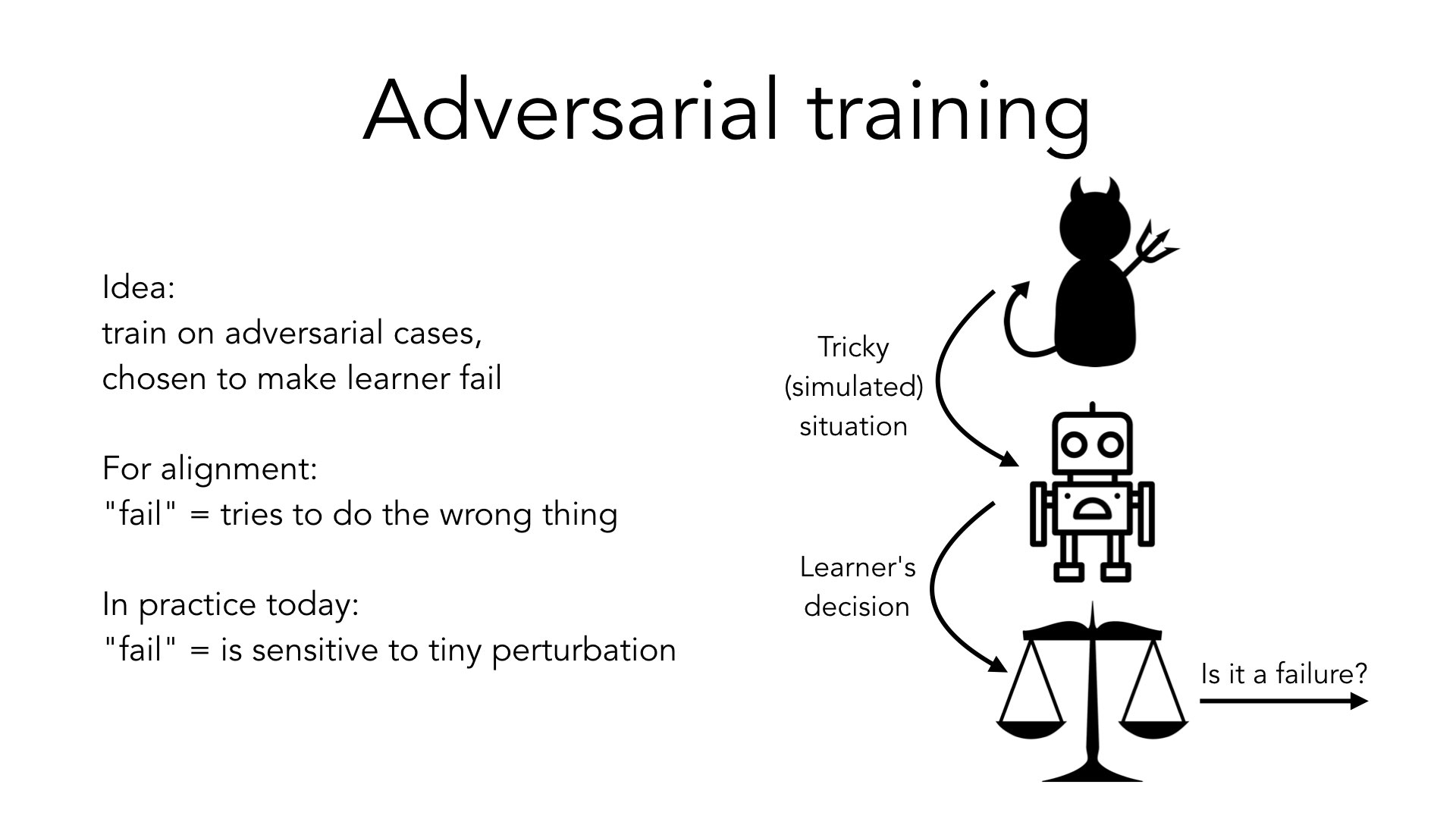
A ideia é a seguinte: se estou preocupado com a possibilidade de meu sistema falhar em casos diferentes dos casos que apareceram durante o treinamento, posso pedir a um adversário que construa casos em que meu sistema tenha maior probabilidade de falhar e depois treinar nesses casos. E então podemos simplesmente repetir esse ciclo. Cada vez que tenho um novo agente, pergunto ao meu adversário: “Tudo bem, agora pense em uma situação em que isso falharia”.
A noção de “falha” aqui é um parâmetro livre que podemos escolher.
No caso do alinhamento, a falha significa que não estamos tentando fazer o que queremos. Vamos pedir ao adversário que gere casos como esse, nos quais o sistema não está tentando fazer o que queremos.
No [trabalho comum de treinamento de IA atualmente], falha geralmente significa algo como “o comportamento do seu modelo é sensível a uma pequena perturbação na entrada”.
A ideia básica é a mesma entre esses dois casos. Há uma questão em aberto sobre até que ponto as técnicas que ajudam num caso ajudarão no outro. Mas a estrutura básica, o esquema, é a mesma. E este tópico é um foco ativo de pesquisa e aprendizado de máquina; normalmente não da perspectiva do alinhamento, mas da perspectiva de [encontrar um sistema que funcione bem, de forma confiável e seja resiliente para diferentes entradas].
Existem outras abordagens possíveis.

Um exemplo: gostaria de entender o que a diretriz que aprendi está fazendo. Se eu compreender isso, mesmo que de uma forma muito grosseira, poderei ser capaz de ver que mesmo que uma diretriz [pareça ter] um bom objetivo na distribuição de treinamento, na verdade faria algo muito estranho sob diferentes condições. Na verdade, não está tentando otimizar o objetivo e, portanto, em alguma situação estranha, faria algo contrário aos meus interesses.
Novamente, hoje em dia a maioria das pessoas estuda essa questão [enquanto pensa] “com certeza seria bom entender algo sobre o que esses modelos que estamos aprendendo estão fazendo”. Mas os mesmos tipos de pesquisa que estão fazendo podem ser úteis para entender: será que este modelo de aprendizado está fazendo algo de ruim? Seria potencialmente algo de ruim em uma situação nova?
Outro exemplo é a verificação, na qual, em vez de apenas considerar o comportamento da minha diretriz em exemplos específicos, posso tentar quantificar possíveis entradas. Posso [testar situações diretamente, para encontrar situações em que a diretriz funcionaria mal ou para demonstrar que funciona bem em todos os casos].
Como eu disse, eu trabalho principalmente no alinhamento externo. Aqui, novamente, farei outra distinção entre pares, dividindo o problema em duas partes – [você poderia pensar nelas como] a metade fácil e a metade difícil, ou o aquecimento e o problema completo.
Um cenário é o caso em que temos acesso a algum especialista que entende muito bem a tarefa que queremos que nossa IA execute.
Imagine que eu tenha um professor que é capaz de demonstrar o comportamento pretendido e de avaliar o comportamento pretendido: ele entende o que a IA deveria fazer. Nesse caso, temos muitas opções para construir um objetivo que fará com que a nossa IA faça a coisa certa. Por exemplo, eu poderia simplesmente escolher diretrizes que produzissem um comportamento muito semelhante ao comportamento do professor.
Então, se você tem um professor que faz o que eu quero e eu quero um agente que faça o que eu quero, vou fazer um cículo sobre os agentes até encontrar um que pareça fazer o mesmo tipo de coisa que o agente faz ou que o professor faz.
Outra opção é fazer com que o professor observe o comportamento [do agente de IA] e diga se foi bom ou ruim, e depois procure diretrizes que produzam comportamentos que o professor considera bons.
Ambos são casos de imitação e aprendizado a partir do feedback. Uma das minhas principais dificuldades pode ser o fato de ter acesso a um professor, mas quero poder utilizar de forma eficiente os dados que o professor fornece. Talvez seja caro [trabalhar com] o professor, e esse é o tipo de dificuldade que parece realmente grande: ser eficiente na forma como uso o tempo desse especialista e ser cuidadoso sobre como [o conhecimento do professor] é transmitido ao agente.
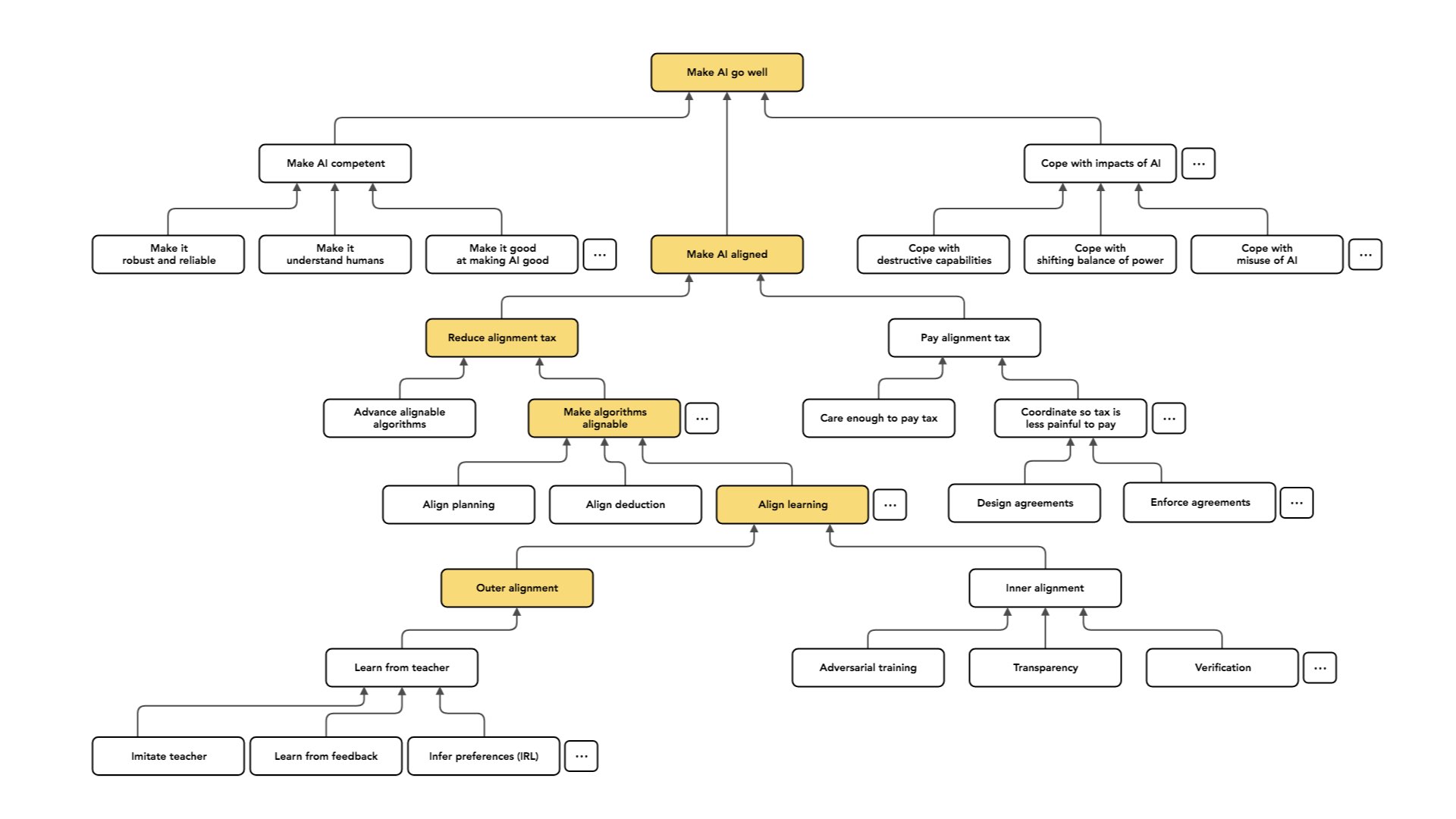
Outra opção é o “aprendizado por reforço inverso”: observar o comportamento do professor, descobrir quais valores ou preferências o professor parece satisfazer e então usá-los [como valores ou preferências para o agente].
Você pode ver a imitação e o aprendizado a partir do feedback como casos especiais de algum paradigma mais geral. Isso envolverá algumas suposições que relacionam as preferências do professor com o seu comportamento [p. ex., presumindo que o professor se comporte próximo do ideal para satisfazer as suas preferências].
Como eu disse, o tipo de caso mais fácil é aquele em que temos um professor e o professor é capaz de exibir ou compreender o comportamento pretendido. Mas o caso que nos interessa a longo prazo é aquele em que queremos construir sistemas de IA que sejam capazes de tomar decisões que um ser humano não poderia tomar, ou que compreendam coisas sobre a sua situação que nenhum professor disponível entende.

E, assim, o caso de aprender com um professor é, num sentido prático, o mais imediatamente relevante. Temos humanos que são muito bons em realizar tarefas. Hoje, queremos principalmente que nossos sistemas de IA façam o que os humanos fazem, mas de forma mais barata. No longo prazo, da perspectiva do risco de alinhamento de longo prazo, nos preocupamos muito com o caso em que queremos fazer coisas que um ser humano não poderia ter feito ou nem consegue entender.
Esse pode ser um [tipo de caso] em que as pessoas preocupadas com os impactos de longo prazo se concentram mais, relativamente às pessoas que se preocupam com a aplicabilidade prática. Então vou falar sobre três abordagens diferentes a esse problema (que, novamente, não são completas).
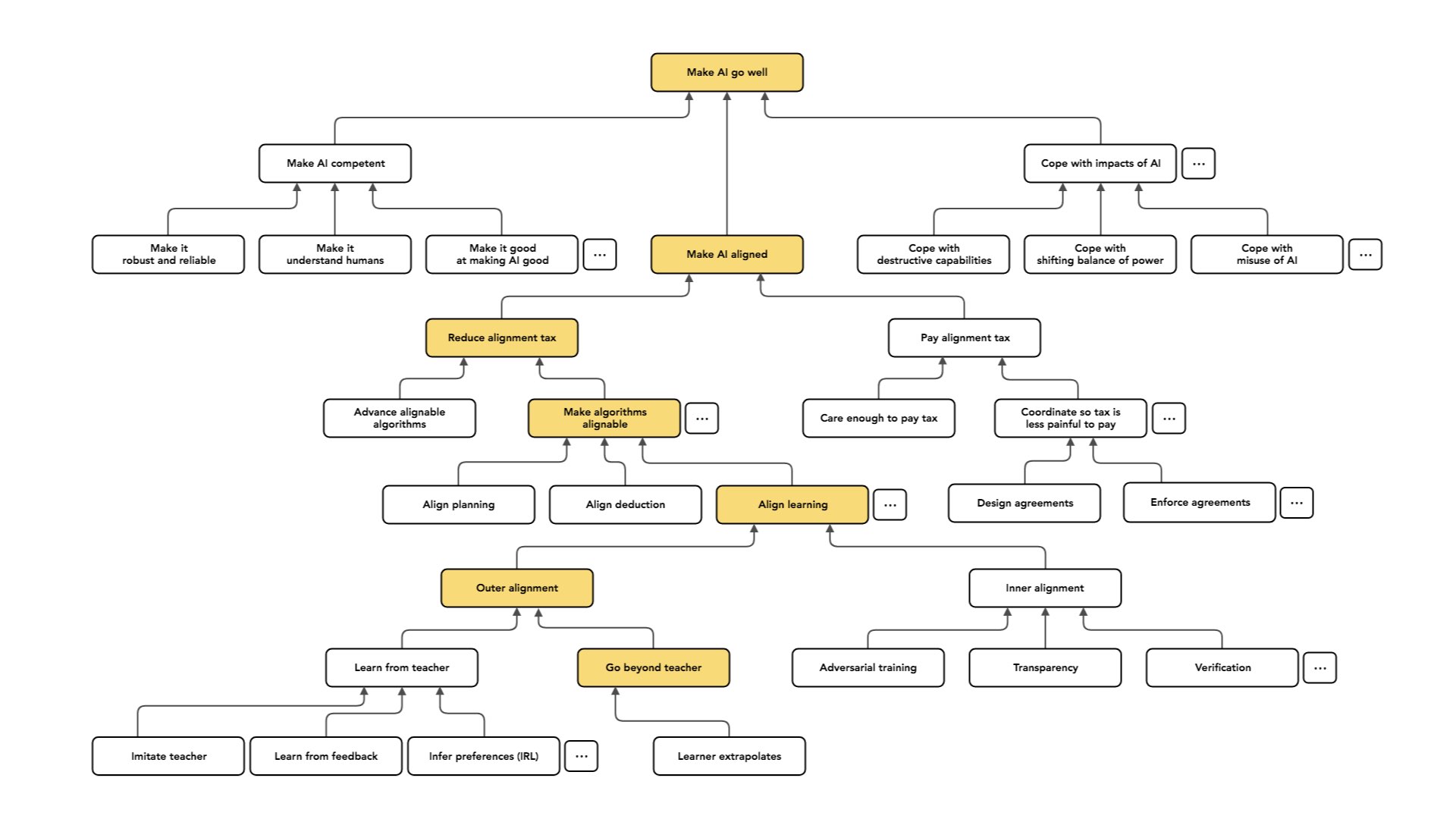
Uma abordagem – que considero ser a expectativa implícita mais comum das pessoas na comunidade de aprendizado de máquina – é tratar o caso em que você tem um professor como um “conjunto de treinamento” e, em seguida, treinar um modelo que irá extrapolar esses dados para o caso em que você não tem acesso a um professor. Portanto, você espera que, se o seu modelo generalizar da maneira certa, ou se você treiná-lo em uma distribuição de casos suficientemente ampla, ele aprenda a coisa certa e extrapole.
Não vou falar muito sobre isso. Acho que o histórico até agora para esse tipo de extrapolação não é bom. Mas acho que é razoável perguntar se isso poderia [funcionar melhor] à medida que nossos sistemas de IA se tornassem mais inteligentes.
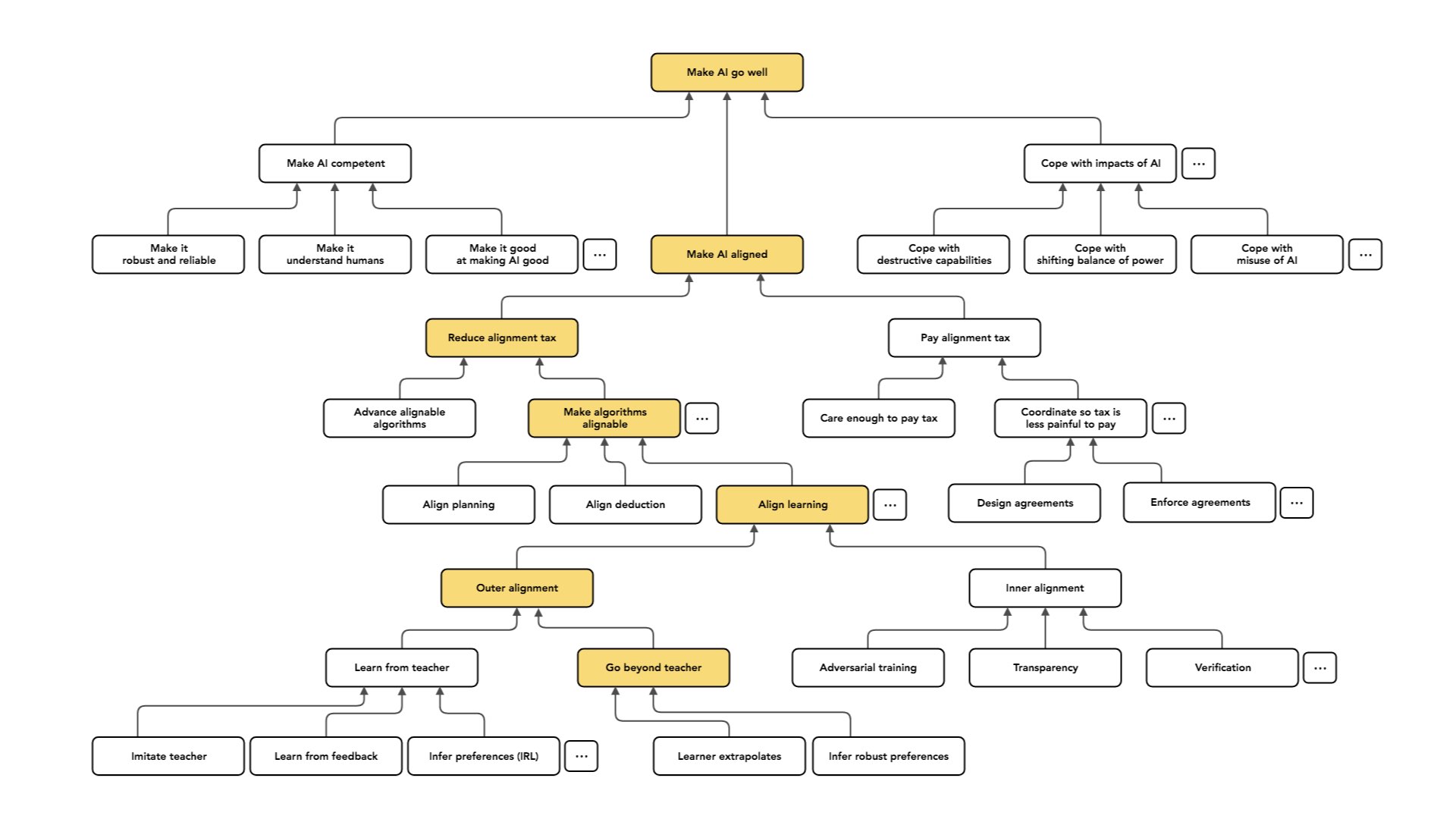
Outra opção seria tratar o caso “aprender com um professor” como um aquecimento. Poderíamos fazer aprendizado por reforço inverso e tentar [descobrir] quais eram os valores do professor. Também podemos tentar ir além do professor e inferir o que ele realmente queria. [Os valores que uma pessoa usa para tomar decisões não são os mesmos que ela realmente deseja obter dessas decisões.] Num sentido mais profundo, podemos entender quais dos comportamentos do professor são artefatos do que ele quer versus o que ele valoriza? Podemos separar isso e tentar conseguir o que [o professor] queria, mas sem as limitações que ele tinha?
Acho que esse é um projeto plausível, mas parece muito difícil agora.
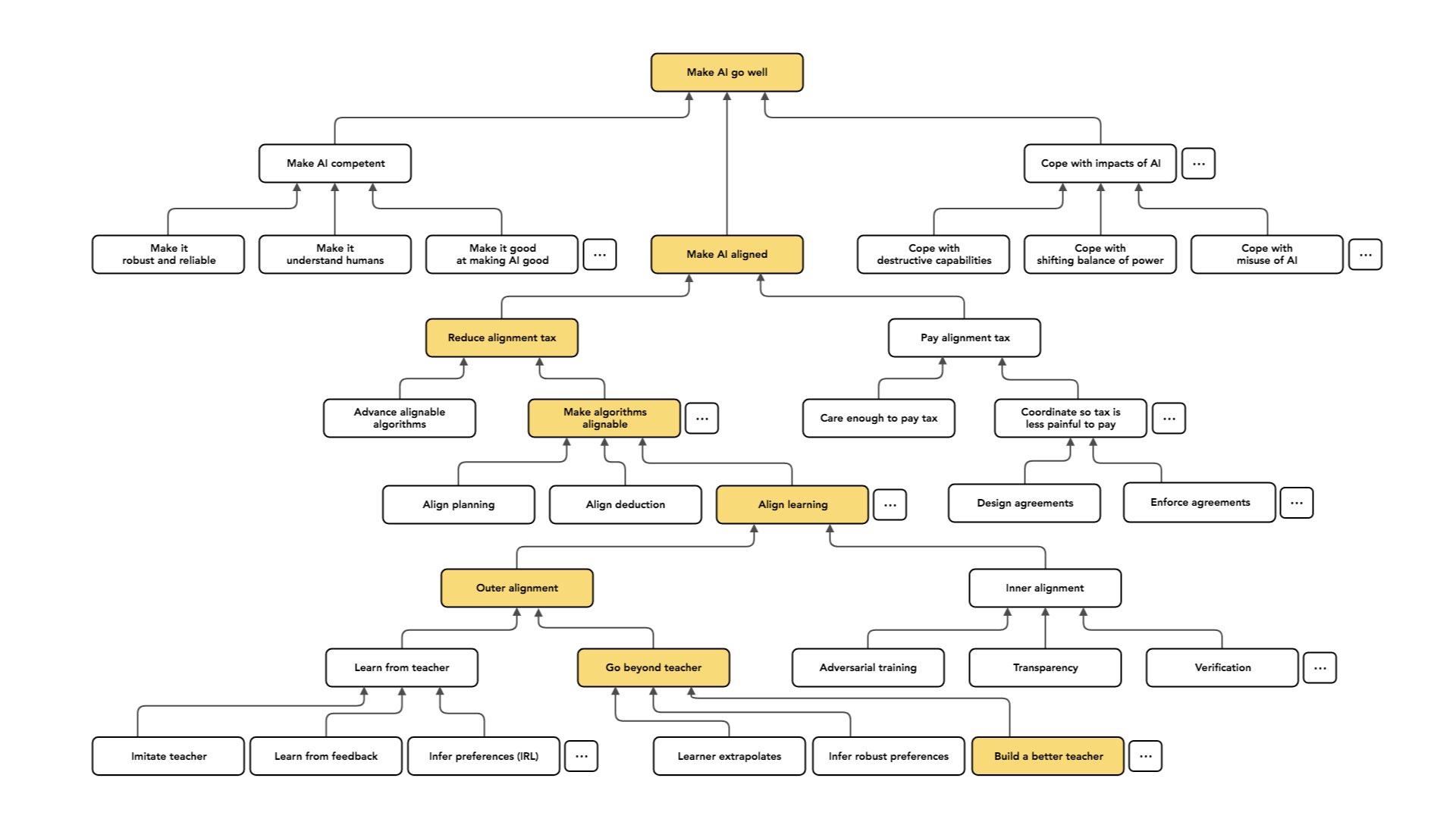
E então uma terceira abordagem, que também parece difícil — mas é aquela que mais me anima e na qual mais me concentro — é tratar o aprendizado de um professor como um alicerce e dizer: “Suponhamos que possamos resolver bem esse problema. Existe alguma maneira de usar isso para conseguir diretamente o que queremos no longo prazo?” Poderíamos supor que se conseguíssemos construir uma sequência de professores cada vez melhores, pudéssemos treinar uma sequência de agentes cada vez melhores sem nunca ter que [entender nada que um professor não entenderia].

Então a ideia aqui é perguntar: onde podemos conseguir um professor melhor? Alguém que entende o suficiente para treinar o agente? E um ponto em que podemos obter força é que, se você levar 10 pessoas, talvez elas possam resolver problemas mais difíceis do que uma pessoa pode resolver.
Portanto, se você tiver 10 pessoas e pedir a elas que decomponham um problema – quebrem-no em pedaços e dividam o trabalho –, elas poderão resolver problemas que estariam pelo menos um pouco além das habilidades de uma única pessoa. E poderíamos esperar que o mesmo se aplicasse aos sistemas de IA que treinamos.

[Uma explicação excessivamente simples] seria dizer: “Em vez de considerar que nosso professor inicial é um humano e aprender com esse humano a se comportar tão bem quanto um humano, vamos começar aprendendo com um grupo de humanos a fazer coisas mais sofisticadas do que um humano poderia fazer.” Isso poderia nos dar uma IA, que não é apenas de “nível humano”, mas de nível de um grupo humano.
E então podemos tomar isso como nosso alicerce e repetir esse procedimento. Podemos formar um grupo desses sistemas de IA. Cada IA já era tão boa quanto um grupo humano. Talvez esse grupo de IA seja agora melhor do que qualquer grupo de humanos, ou seja tão bom quanto um grupo muito maior. E posso usar esse [grupo de IA] como professor para treinar outro sistema de IA.
Se essa dinâmica seguir consistentemente na direção certa, posso esperar apenas treinar uma sequência de sistemas de IA cada vez melhores, que continuam a fazer o que queremos [porque cada grupo na sequência estava alinhado com a nossa intenção original]…
Isso foi uma ampla visão geral de como vejo as diferentes partes do problema do alinhamento relacionadas entre si e como elas se encaixam no quadro geral. Estou tentando entender [como os sistemas de IA realmente tomam decisões] em vez de apenas aceitar que teremos essas caixas-pretas malucas e opacas. Vamos promover abordagens diferentes que não [apresentem] os mesmos riscos potenciais [de sistemas não alinhados com os objetivos humanos].
Quando estou pensando sobre esses tipos de questões, é realmente útil para mim ter em mente uma visão geral de como as coisas se interligam, quais são os problemas separados e como eles se relacionam. Então isso é tudo que tenho a dizer, e acho que isso nos deixa apenas alguns minutos para perguntas. Obrigado.
Tradução: Luan Marques
Link para o original