De Richard Ngo. 5 de janeiro de 2023.
O campo da IA passou por uma revolução na última década, impulsionado pelo sucesso de técnicas de aprendizado profundo. Este post pretende transmitir três ideias usando uma série de exemplos ilustrativos:
- Houve grandes saltos nas capacidades de IAs na última década, a ponto de se tornar difícil especificar tarefas que IAs não podem realizar.
- Esse progresso foi impulsionado principalmente pela amplificação de um punhado de algoritmos relativamente simples (em vez do desenvolvimento de uma compreensão mais baseada em princípios ou científica do aprendizado profundo).
- Poucas pessoas previram que o progresso seria tão rápido; mas muitos dos que previram também preveem que podemos enfrentar o risco existencial advindo da IGA (Inteligência Geral Artificial) nas próximas décadas.
Vou me concentrar em quatro domínios: visão, jogos, tarefas baseadas em linguagem e ciência. Os dois primeiros têm aplicações mais limitadas no mundo real, mas fornecem exemplos particularmente vívidos e intuitivos do ritmo do progresso.
Índice
Visão
Reconhecimento de imagem
O reconhecimento de imagem tem sido o foco do campo da IA por muitas décadas. As primeiras pesquisas se concentravam em domínios simples, como a escrita à mão; o desempenho agora melhorou significativamente, superando o desempenho humano em muitos conjuntos de dados. No entanto, é difícil interpretar pontuações em referenciais de forma intuitiva, de modo que vamos nos concentrar em domínios onde o progresso pode ser visualizado com mais facilidade.
Geração de imagem
Em 2014, a geração de imagens de IA avançou significativamente com a introdução de Redes Adversárias Generativas (RAGs). No entanto, os primeiros RAGs só conseguiam gerar imagens muito simples ou borradas, como estas abaixo.

Nos 8 anos seguintes, a geração de imagens progrediu em um ritmo muito rápido; a figura abaixo mostra imagens geradas por sistemas de última geração em cada ano. Nos últimos dois anos, em particular, esses sistemas fizeram muito progresso na geração de cenas criativas complexas em resposta a pedidos linguísticos.
Esta é uma taxa de progresso impressionante. O que o conduziu? Em parte, foi o desenvolvimento de novos algoritmos – principalmente RAGs, transformadores e modelos de difusão. No entanto, o principal fator subjacente foi a amplificação da quantidade de recursos computacionais e dados usados durante o treinamento. Uma demonstração disso vem da série Parti de modelos de imagem, que inclui quatro redes de tamanhos diferentes (com contagens de parâmetros variando de 350 milhões a 20 bilhões). Embora todos tenham sido treinados da mesma forma, para os três pedidos abaixo você pode ver claramente como os modelos maiores são melhores do que os menores (p. ex., observando o surgimento gradual da capacidade de retratar o texto).
Geração de vídeo
Um dos primeiros exemplos de geração de vídeo veio do modelo DVD-GAN de 2019 da DeepMind. No entanto, embora os vídeos tenham alguns recursos realistas, quase todos os vídeos individuais são visivelmente deformados.

Mais recentemente, os pesquisadores se concentraram na produção de vídeos em resposta a pedidos textuais. Aqui estão quatro conjuntos de exemplos de diferentes sistemas lançados entre abril e outubro de 2022, mostrando melhorias visíveis apenas nesse período:
Pedidos em ordem: caminho numa floresta tropical; atividade num canteiro de obras; nuvens se movendo; pôr do sol ao mar; latas de alumínio numa esteira transportadora; zoom num operário serrando um cano de aço – conceito de técnico; pôr do sol dramático no oceano; floresta no outono; Berlim – Portão de Brandenburgo à noite; visão aérea de cavalos num pasto; engarrafamento na Avenida 23 de Maio, em ambas as direções, sul de São Paulo; autoestrada movimentada à noite.

Jogos
Videogames
Em 2013, o estado da arte para o uso de aprendizado de máquina para aprender a jogar videogames estava superando os humanos em alguns jogos da Atari muito simples, como Pong e Breakout.
Em 2018, isso progrediu para a derrota de profissionais nos esportes mais complexos, em particular StarCraft e DOTA2, nos quais os jogadores realizam milhares de ações seguidas ao longo de jogos com duração de até uma hora.
E em 2022, os recursos se estenderam de jogos restritos para ambientes de extensão em aberto como o Minecraft, onde o treinamento em vídeos de jogadores humanos permitiu que as IAs aprendessem a executar sequências complexas de ações envolvendo muitas etapas diferentes. Abaixo você pode ver as muitas subtarefas envolvidas na fabricação de uma picareta de diamante e um vídeo da IA executando-as.
Jogos de estratégia
2016 e 2017 viram o sistema AlphaGo da DeepMind vencer os melhores jogadores do mundo no Go, um jogo de tabuleiro muito mais complexo que o xadrez.
Digno de nota é que uma versão posterior do AlphaGo treinada sem dados humanos, apenas jogando contra si mesma, atingiu o nível sobre-humano (indicado pela linha verde no gráfico abaixo) após menos de três dias de treinamento, o que envolveu redescobrir muitos aspectos da teoria e estratégia do Go que os humanos desenvolveram ao longo de milhares de anos.
Eixo y: Classificação da Elo; eixo x: Dias.
No entanto, xadrez e Go ainda são jogos bastante simples: os jogadores só podem interagir de maneiras muito limitadas. 2022 viu IAs atingindo desempenho de nível humano no jogo de tabuleiro Diplomacy (um jogo de estratégia semelhante ao Risk). O Diplomacy exige que os jogadores formem alianças ocultas por meio de negociações complexas baseadas na linguagem, além de enganar outros jogadores ao trair essas alianças.
Tarefas baseadas na linguagem
O nível de capacidades linguísticas usados nas negociações do Diplomacy foi viabilizado pelo desenvolvimento nos últimos anos de grandes modelos de linguagem (large language models, LLMs) treinados em bilhões de palavras de texto. Apesar de serem treinados apenas para prever a próxima palavra, a fim de fazer isso com muita precisão, os LLMs desenvolvem uma série de habilidades emergentes, incluindo um amplo conhecimento sobre o mundo que pode ser acessado fazendo-lhes os pedidos certos. Os principais LLMs que discutiremos nesta seção são os modelos GPT-2, GPT-3 e ChatGPT da OpenAI (o último dos quais você pode experimentar on-line aqui) e diversas variantes do modelo PaLM da Google.
Geração de texto
Embora seja difícil comparar os resultados de diferentes pedidos, algumas amostras de diferentes modelos podem fornecer uma noção intuitiva da taxa de progresso.
Em 2011, modelos de linguagem de última geração não conseguiam nem organizar frases gramaticais:
PEDIDO: O SENTIDO DA VIDA É
O sentido da vida é a tradição da antiga reprodução humana: é menos favorável ao bom menino para quando remover o maior dela. No acordo do espetáculo ressurgiu com unanimidade. Os selvagens pastaram com consistentes florestas de rua foram incorporados à altura do século XV aC. Em 1996 o principal rapford passa por um esforço que a reserva condicionando, escrito nas cidades judias, dorminhocos para incorporar a .Sta Eurásia que ativa a população. O pensamento de Mar??a Nationale, Kelli, Zedlat-Dukastoe, Florendon, Ptu é. Adaptar na maioria das partes da América do Norte, a dinâmica
O sentido da vida é a tradição da antiga reprodução humana: é menos favorável ao bom menino para quando remover o maior dela. No acordo do espetáculo ressurgiu com unanimidade. Os selvagens pastaram com consistentes florestas de rua foram incorporados à altura do século XV aC. Em 1996 o principal rapford passa por um esforço que a reserva condicionando, escrito nas cidades judias, dorminhocos para incorporar a .Sta Eurásia que ativa a população. O pensamento de Mar??a Nationale, Kelli, Zedlat-Dukastoe, Florendon, Ptu é. Adaptar na maioria das partes da América do Norte, a dinâmica
Um grande salto na geração de texto veio com o desenvolvimento do GPT-2 em 2019, que foi consistentemente capaz de gerar frases coerentes contendo conhecimento relevante sobre o mundo.
PEDIDO: MILEY CYRUS HOJE FOI PEGA FURTANDO DA ABERCROMBIE AND FITCH EM HOLLYWOOD BOULEVARD
A cantora de 19 anos foi filmada sendo escoltada para fora da loja por seguranças.
A cantora estava de capuz preto com o rótulo "Linhas Turvas" na frente e "Polícia da Moda" atrás
A cantora também estava de óculos de aros pretos, uma jaqueta preta, jeans preto e sandálias pretas.
Ela carregava um par de luvas listradas em preto e branco e uma bolsa preta pequena.
Outro salto veio com o GPT-3 em 2020, que foi treinado de forma muito semelhante ao GPT-2, mas com cerca de 100 vezes mais parâmetros.
PEDIDO: METODISTAS UNIDOS CONCORDAM SOBRE UMA CISÃO HISTÓRICA — AQUELES QUE SE OPÕEM AO CASAMENTO GAY FORMARÃO A SUA PRÓPRIA DENOMINAÇÃO
Após dois dias de intenso debate, a Igreja Metodista Unida concordou sobre uma cisão histórica — uma que, espera-se, terminará na criação de uma nova denominação, uma que será "teológica e socialmente conservadora", segundo o Washington Post. A maioria dos representantes que compareceram na Conferência Geral da igreja em maio votaram para fortalecer a proibição sobre a ordenação de clérigos LGBTQ e escrever novas regras que irão "disciplinar" clérigos que oficiarem em casamentos homossexuais. Mas aqueles que se opuseram a essas medidas têm um novo plano: eles dizem que formarão uma denominação distinta à altura de 2020, chamando a sua igreja de denominação Metodista Cristã.
O Post observa que a denominação, que alega ter 12,5 milhões de membros, era no início do século XX "a maior denominação protestante nos Estados Unidos", mas que ela vem diminuindo de tamanho nas últimas décadas. A nova cisão será a segunda na história da igreja. A primeira ocorreu em 1968, quando cerca de 10% da denominação partiram para formar a Igreja Evangélica dos Confrades Unidos. O Post observa que a proposta cisão "chega num momento crucial para a igreja, que vem perdendo membros há anos", que tem sido "empurrada para a beira de um cisma sobre o papel de pessoas LGBTQ na igreja". O casamento gay não é o único tema que tem dividido a igreja. Em 2016, a denominação se dividiu sobre a ordenação de clérigos transgêneros, com a conferência regional do Pacífico Norte votando para proibi-los de servir como clérigos, e a conferência regional do Pacífico Sul votando para lhes permitir.
O próximo modelo da série foi o ChatGPT, lançado em 2022. O ChatGPT supera significativamente o GPT-3 em uma variedade de tarefas; como exemplo, veja a sua resposta de escrita criativa ao pedido abaixo:

Respostas de bom senso a perguntas
Historicamente, um dos principais impedimentos ao progresso da IA tem sido o raciocínio com bom senso. Nos últimos anos, porém, grandes modelos de linguagem tornaram-se capazes de fornecer respostas de bom senso descomplicadamente corretas para uma ampla gama de perguntas. (Observe, no entanto, que se um LLMs responde ou não corretamente a uma pergunta geralmente depende de como a pergunta é feita.)
Aqui estão algumas explicações de piadas do modelo PaLM 2022 da Google (com o quadro superior contendo exemplos dados ao modelo e, em seguida, os quadros abaixo contendo as próprias respostas do modelo):
Explicando uma Piada
Explicarei estas piadas:
- O problema dos cleptomaníacos é que eles sempre levam as coisas literalmente.
Explicação: esta piada é um trocadilho. Alguém que “leva as coisas literalmente” é alguém que não compreende plenamente indícios sociais e contexto, que é um traço negativo. Mas a definição de cleptomaníaco é alguém que literalmente leva as coisas.
- Sempre pegue dinheiro emprestado com pessimistas. Eles nunca irão esperar recebê-lo de volta.
Explicação: a maioria das pessoas espera que você as pague quando pega dinheiro emprestado; no entanto, um pessimista é alguém que sempre presume o pior, de modo que, se você pegar dinheiro emprestado com um, ele irá esperar que você não lhe pague de volta de qualquer forma.
Entrada: Era para eu começar a escrever um artigo às 17:00. Mas então comecei a brincar com um novo modelo de linguagem bem legal por 10 minutos. 10 minutos depois, de repente são 21:30!
Saída do modelo: Essa piada é sobre como o tempo voa quando você está se divertindo. Era para a pessoa começar a escrever o artigo às 17:00, mas começou a brincar com um modelo de linguagem em vez disso. Ela pensou que só tinha brincado com ele por 10 minutos, mas foram 4,5 horas na realidade.
Entrada: Eu ia pegar um avião para visitar minha família dia 6 de abril. Minha mãe disse: “Oh, ótimo. A leitura de poesia do seu padrasto é essa noite!” Então agora vou pegar o avião dia 7 de abril.
Saída do modelo: A piada é que a mãe do falante está tentando fazer com que ele vá à leitura de poesia do seu padrasto, mas o falante não quer ir; então ele vai mudar seu voo para o dia seguinte à leitura de poesia.
Entrada: Ler “Guerra e Paz” não me assusta. Uma vez tive que revisar o CL para o projeto inteiro do meu estagiário no seu último dia!
Saída do modelo: “Guerra e Paz” é um livro muito longo, de modo que lê-lo é uma tarefa intimidadora. No entanto, o falante está dizendo que teve que revisar o código para o projeto do seu estagiário no seu último dia, o que é ainda mais intimidador.
Entrada: Acho que entendo por que eu e minha companheira combinamos tanto. Eu fico animado quando sinto cheiro de comida e fico super-alerta quando tocam a campainha. Minha namorada Shelley entra em êxtase quando vê uma pessoa que ela viu só 5 horas antes.
Saída do modelo: É uma piada sobre cachorros. Cachorros ficam animados quando sentem cheiro de comida e quando tocam a campainha. A namorada fica animada quando vê alguém que ela viu 5 horas antes, o que é uma característica dos cachorros.
Entrada: Tentei 10.000 reinícios da minha rede neural, mas me acusaram de sobreajuste. Parece que nenhuma boa semente não é punida.
Saída do modelo: Essa piada é um trocadilho. Uma rede neural é um programa de computador que aprende a partir de dados. Uma “semente” é um número que é utilizado para iniciar um gerador de números aleatórios. Uma “boa semente” é um número que produz um bom gerador de números aleatórios. A frase “nenhuma boa ação não é punida” significa que, se você faz algo bom, será punido por isso.
Entrada: Qual a diferença entre uma zebra e um guarda-chuva? Um é um animal listrado aparentado com os cavalos; o outro é um instrumento que você usa para impedir que a chuva caia em cima de você.
Saída do modelo: Essa piada é uma antipiada. A piada é que a resposta é óbvia, e a piada é que você estava esperando uma resposta engraçada.
Aqui está uma série de outros recursos apresentados pelo PaLM:




Os resultados mais impressionantes de respostas a perguntas vêm de medições do desempenho do GPT-3.5 (o modelo por trás do ChatGPT) e do GPT-4 em uma série de exames AP do ensino médio. O GPT-3.5 já supera a maioria dos humanos em muitos exames; o GPT-4 se sai muito melhor em muitos de seus exames mais fracos, especialmente exames quantitativos: p. ex., passando de pior do que quase todos os humanos para perto da mediana no exame de Cálculo do AP. O salto é particularmente impressionante, visto que esses modelos foram treinados com apenas alguns meses de diferença.

Planejamento e pensamento estratégico
Os LLMs também desenvolveram a capacidade de descrever planos de longo prazo e decompô-los em uma série de tarefas. Por exemplo, aqui está o ChatGPT:

Embora sua capacidade de agir de acordo com esses planos seja atualmente limitada, uma série de trabalhos visa adaptar os LLMs para executar tarefas computacionais. Aqui está um exemplo do modelo ACT-1 realizando uma tarefa usando uma interface de computador:
E aqui está um vídeo do robô PaLM-SayCan da Google gerando e executando um plano de várias etapas em resposta às instruções do usuário:
Ciência
Embora o sucesso nas tarefas baseadas em linguagem descritas acima possa permitir que IAs automatizem muito do trabalho de colarinho branco, a longo prazo, os recursos mais impactantes e preocupantes provavelmente envolverão IAs capazes de automatizar o processo de avanço científico e tecnológico (incluindo o progresso no próprio desenvolvimento da IA). Nos últimos anos, vimos um rápido progresso em direção a IAs que são úteis na pesquisa científica.
Codificação
Um passo inicial para automatizar a codificação veio com o GPT-2, onde os pesquisadores que o treinaram notaram um fenômeno surpreendente: ele era capaz de completar automaticamente códigos realistas (embora geralmente com erros), porque seus dados de treinamento incluíam uma variedade de códigos espalhados pela Internet.
Isso foi em 2019. Em 2020, o GPT-3 desenvolveu recursos de codificação muito mais sofisticados, com o modelo de linguagem Codex (baseado no GPT-3) sendo capaz de seguir instruções linguísticas para escrever funções inteiras. Aqui está um exemplo do Codex escrevendo código para implementar uma funcionalidade em um jogo simples, com base em instruções linguísticas.
Quando clicarem no foguete, mostre temporariamente um texto dizendo “disparando propulsores!” em branco na localização atual — e acelere temporariamente em 4x por 0,25 segundo.
Aqui está um exemplo do Codex escrevendo códigos para plotar um gráfico:
Agora plote os resultados. Rotule ambos os eixos (eixo y é temperatura max.), rotacione as marcas x e acrescente um título.
O sistema AlphaCode da DeepMind foi treinado para resolver problemas de programação competitiva e teria sido colocado entre os 54% melhores humanos que participaram das competições de codificação em que foi testado.
Eixo y: Problema do conjunto de dados resolvido; eixo x: Progresso do Modelo da DeepMind; em verde: competidor humano melhor classificado; em roxo: competidor humano médio.
O ChatGPT também é capaz de responder a perguntas de codificação abstratas, incluindo algumas em um nível comparável a perguntas de entrevistas para contratação de engenheiros de software:

Matemática
Os últimos anos também viram um progresso incrível na aplicação da IA à matemática. A IA já havia sido usada para ajudar a provar alguns teoremas matemáticos, mas eles exigiam que os humanos especificassem manualmente quais partes da solução procurar. Por outro lado, os modelos de linguagem modernos são capazes de responder a perguntas matemáticas de formato livre, incluindo algumas perguntas usadas em competições de matemática.
Aqui estão alguns exemplos do modelo MINERVA da Google (uma variante do PaLM) respondendo a perguntas matemáticas:


Aqui está um exemplo de um modelo da OpenAI que é capaz de produzir tanto provas informais como formais na linguagem de programação LEAN:


Embora nenhum dos exemplos acima mostre IAs fazendo novas pesquisas, o modelo AlphaTensor da DeepMind descobriu um novo algoritmo para multiplicação de matrizes que era mais rápido do que qualquer outro projetado por humanos. Embora o AlphaTensor tenha sido desenvolvido especificamente para esse fim (ao contrário dos sistemas mais gerais discutidos acima), o resultado é notável porque a multiplicação de matrizes é a etapa principal no treinamento de redes neurais.
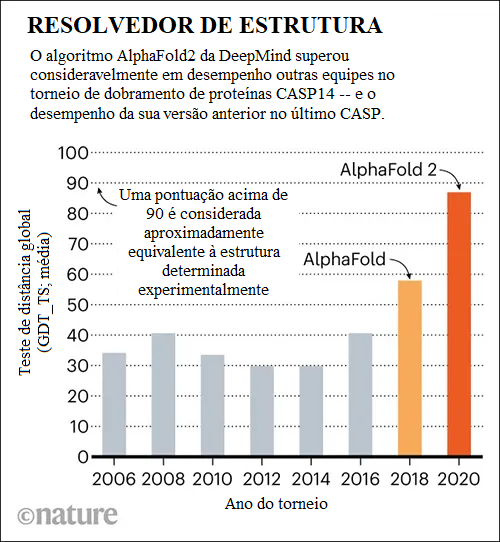
Ciências da Vida
O maior resultado até agora para a IA nas ciências da vida foi o sucesso do AlphaFold 2, a IA da DeepMind feita para prever estruturas de proteínas, que foi descrita por especialistas da área como tendo resolvido o problema do dobramento de proteínas (um dos principais problemas em aberto na biologia). Embora essa afirmação possa ser um tanto exagerada, foi, no entanto, um grande salto adiante em comparação com as tentativas anteriores:
Alguns exemplos das previsões do AlphaFold 2, comparadas com as descobertas experimentais:
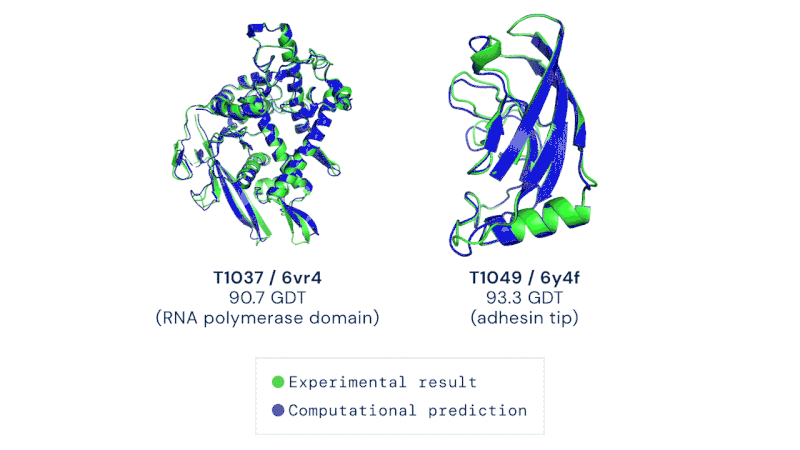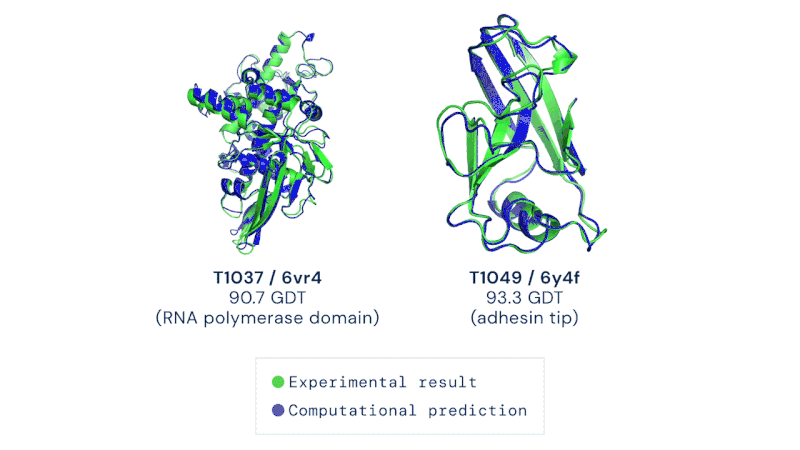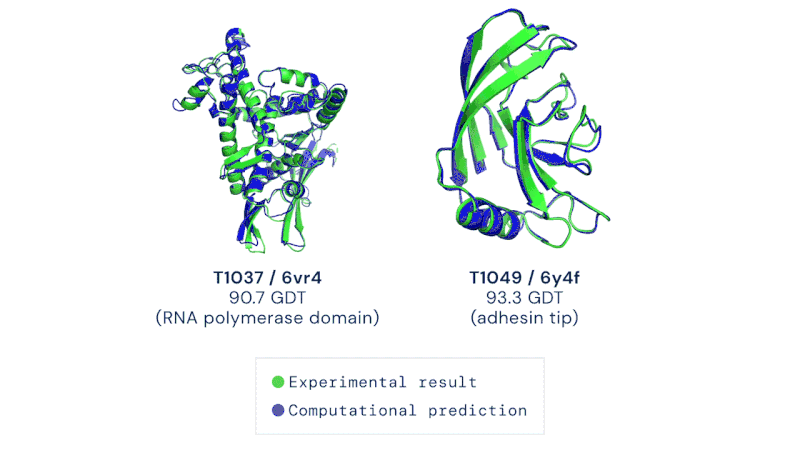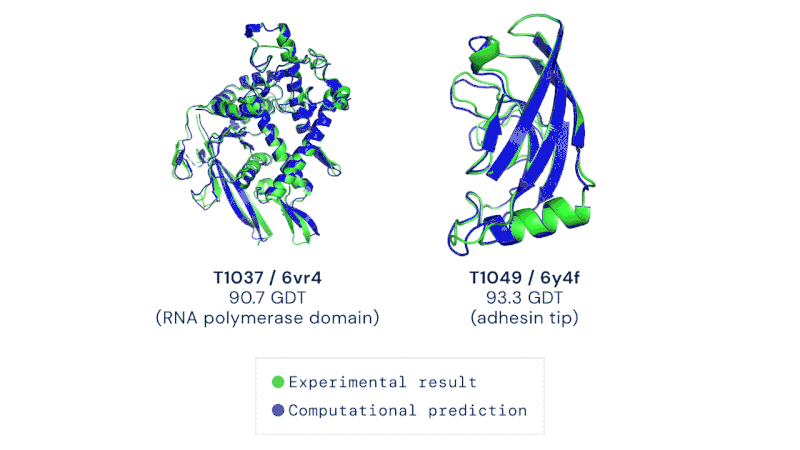
Em verde: resultado experimental; em azul: previsão computacional
Um avanço mais preocupante vem de uma equipe de pesquisadores de desenvolvimento de drogas, que inverteu seu algoritmo feito para encontrar drogas inofensivas para mostrar como isso teria o potencial de gerar armas químicas. O gráfico abaixo mostra a toxicidade prevista dos compostos gerados por sua IA; muitos deles têm uma dose letal menor que a VX (uma das toxinas mais letais conhecidas).
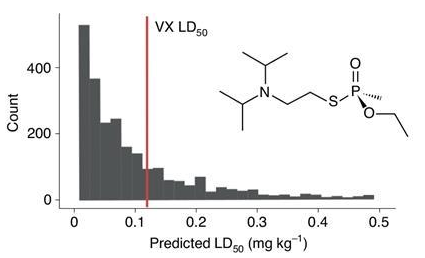
Eixo y: Contagem; eixo x: Prevista dose letal…
Olhando para a frente
Apenas para destacar quão absurda tem sido a taxa de progresso na IA, observe que cerca de metade dos avanços que mencionei aconteceram apenas em 2022! No geral, estamos vendo a IA se tornar cada vez melhor em realizar ações em ambientes complexos, produzir pensamento estratégico e, em seguida, conectá-lo ao mundo real. Você pode se preocupar que a apresentação de exemplos individuais seja uma maneira desorganizada de acompanhar esse progresso, em comparação com a medição de métricas mais quantitativas. No entanto, está ficando difícil projetar tarefas referenciais que permaneçam sem solução por mais que alguns anos, mesmo quando se destinam a acompanhar o progresso de longo prazo. O gráfico abaixo mostra que, ao passo que costumava levar décadas para atingir o nível humano nos referenciais, muitos novos referenciais estão sendo saturados em apenas alguns anos.
O ritmo do progresso surpreende até mesmo os especialistas da área. Por exemplo, considere o conjunto de dados MATH de problemas matemáticos de competição desafiadores, lançado em 2021. Previsores profissionais previram que a melhor precisão alcançada em meados de 2022 seria de 12,7%; na verdade, estava acima de 50%, bem fora de seus intervalos de confiança. Eles também subestimaram significativamente o progresso no conjunto de dados Entendimento de Linguagem Multitarefa Massivo de 2020, que abrange matemática elementar, história dos EUA, ciência da computação, direito e muito mais. Esses previsores não eram especialistas em aprendizado de máquina, mas previram um progresso muito mais rápido do que a maioria dos especialistas, e ainda assim subestimaram dramaticamente o progresso nesses dois referenciais (embora em dois outros referenciais as suas previsões tenham sido mais precisas).

Uma das razões pelas quais é difícil fazer previsões precisas é porque os recursos de processamento usados no treinamento de sistemas de aprendizado de máquina aumentaram drasticamente. Para entender isso, veja o gráfico abaixo mostrando os recursos computacionais usados para treinar mais de 100 sistemas de aprendizado de máquina de ponta. Observe em particular que o eixo y está em uma escala logarítmica: o sistema mais intensivo em termos de recursos de processamento retratado no gráfico foi treinado usando acima de 10 milhões de vezes mais recursos de processamento do que o maior sistema de dez anos antes (por volta do início da era do aprendizado profundo).
Recursos computacionais (FLOPs) de sistemas de aprendizado de máquina cruciais pelo tempo. Eixo y: Recursos computacionais de treinamento (FLOPs); eixo x: Data de publicação; em laranja: Era Pré-Aprendizado de Máquina; em azul: Era do Aprendizado de Máquina.
As pessoas que chegaram mais perto de prever corretamente a rapidez do progresso normalmente o fizeram concentrando-se na amplificação dos recursos de processamento, mesmo quando isso levava a consequências aparentemente absurdas. Na década de 1990, Hans Moravec previu IA de nível humano na década de 2030, com base na previsão de amplificação dos recursos de processamento. Em 2005, Ray Kurzweil usou um método semelhante para prever uma “transformação profunda e disruptiva na capacidade humana” (que ele chamou de “singularidade”) à altura de 2045. Em 2010, antes da revolução do aprendizado profundo, o cofundador da DeepMind, Shane Legg, previu IA de nível humano à altura de 2028 usando estimativas baseadas em recursos de processamento. O cofundador da OpenAI, Ilya Sutskever, cujo artigo da AlexNet desencadeou a revolução do aprendizado profundo, também foi um dos primeiros proponentes da ideia de que a amplificação do aprendizado profundo seria transformadora. Independentemente de as especificidades dessas previsões estarem corretas ou não, todas elas parecem muito mais plausíveis agora do que há uma década, especialmente quando comparadas ao consenso dominante de que o progresso na IA não seria nem de longe tão rápido. Mais recentemente, em 2020, uma equipe da OpenAI desenvolveu leis de amplificação que afirmavam que aumentar a quantidade de recursos de processamento usados em grandes modelos de linguagem previsivelmente melhoraria seu desempenho, uma afirmação que foi amplamente confirmada desde então (embora tenha havido correções recentes às leis de amplificação específicas que eles propuseram).
Outra coisa que muitos desses previsores compartilham é a séria preocupação com a possibilidade de que a IGA não vá estar alinhada com os valores humanos e que isso possa levar a resultados catastróficos. Shane iniciou e liderou a equipe técnica de segurança de IGA da DeepMind; mais recentemente, Ilya tem passado 50% de seu tempo na pesquisa de alinhamento; e a equipe principal por trás do artigo sobre leis de amplificação fundou a Anthropic, um laboratório de pesquisa focado em alinhamento. A possibilidade de estarmos na véspera da IGA naturalmente concentra a mente nos riscos de trazer uma tecnologia tão poderosa ao mundo.
Tradução: Luan Marques
Link para o original