De Richard Ngo. Publicado em 30 de agosto de 2021
Apesar da popularidade atual do aprendizado de máquina, não encontrei nenhuma breve introdução que corresponda exatamente à maneira como prefiro apresentar as pessoas ao campo. Então aqui está a minha. Em comparação com outras introduções, me concentrei menos em explicar cada um dos conceitos em detalhes e mais em explicar como eles se relacionam com outros conceitos importantes no campo da IA, especialmente em forma de diagrama. Se você é novo no aprendizado de máquina, não deve esperar entender totalmente a maioria dos conceitos explicados aqui logo após ler esta postagem — o objetivo é fornecer uma estrutura ampla que contextualizará as explicações mais detalhadas que você receberá de outros lugares.
Estou ciente de que taxonomias de nível abstrato podem ser controversas e também que é fácil cair na ilusão de transparência ao tentar apresentar um campo; então sugestões de melhorias são muito bem-vindas!
As ideias-chave estão contidas neste diagrama de resumo:
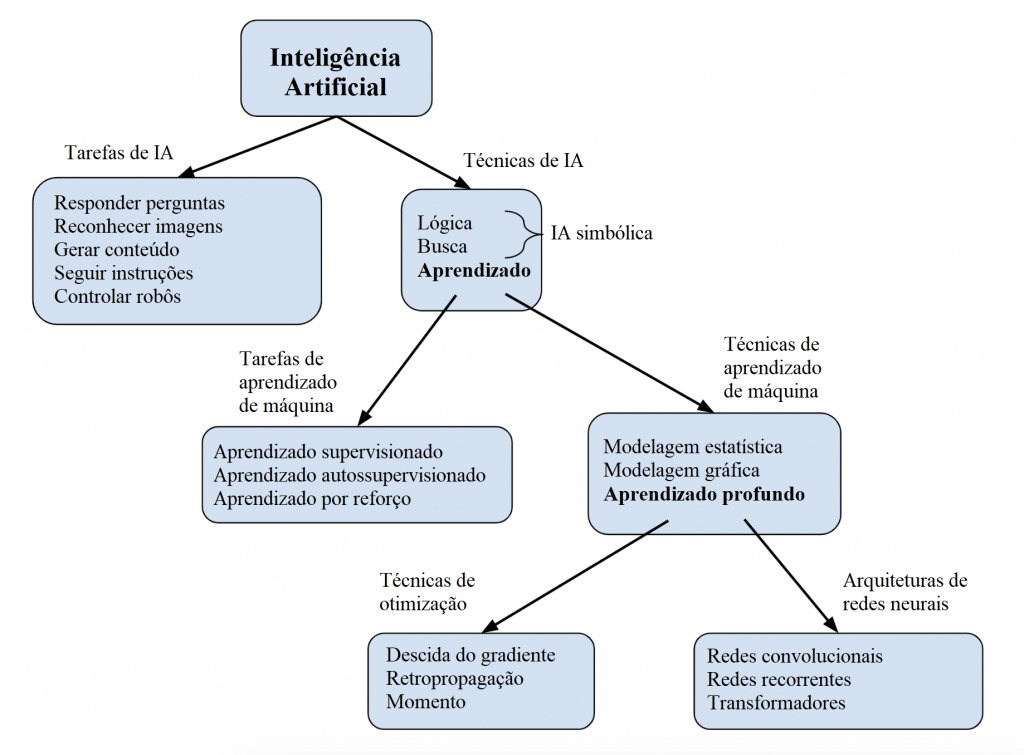
Antes, alguns breves esclarecimentos:
- A intenção não é que os quadros sejam completos; poderíamos adicionar mais itens a qualquer um deles. Portanto, você deve imaginar cada lista terminando com “e outros”.
- A distinção entre tarefas e técnicas não é uma categorização firme ou paradigmática; é apenas a melhor maneira que encontrei até agora para colocar as coisas.
- O resumo é explicitamente de uma perspectiva centrada na IA. Por exemplo, modelagem estatística e otimização são campos existentes por si sós; mas, para nossos propósitos atuais, podemos pensar nelas como técnicas de aprendizado de máquina.
Vamos nos aprofundar em cada parte do diagrama agora, começando do topo.
Índice
Paradigmas da inteligência artificial
O campo da inteligência artificial visa desenvolver programas de computador capazes de realizar tarefas úteis, como responder a perguntas, reconhecer imagens e assim por diante. Começou por volta da década de 1950. Historicamente, tem havido várias abordagens diferentes à IA. Nas primeiras décadas, o paradigma dominante era a IA simbólica, que focava em representar problemas usando declarações em linguagens formais (como a lógica ou linguagens de programação) e buscando soluções por meio da manipulação dessas representações segundo regras fixas. Por exemplo, uma IA simbólica pode representar um jogo de xadrez usando um conjunto de declarações sobre onde as peças estão no momento e um conjunto de declarações sobre para onde é permitido que as peças se movam (você só pode mover bispos diagonalmente, você não pode mover seu rei para uma posição de xeque, etc.). Ele pode então jogar xadrez buscando possíveis jogadas que sejam consistentes com todas aquelas declarações. O poder da IA simbólica fundamentada em buscas foi exibido pelo Deep Blue, a IA enxadrista que derrotou Kasparov em 1997.
No entanto, as representações simbólicas projetadas por pesquisadores do campo da IA acabaram sendo simples demais: há muito poucos fenômenos no mundo real que sejam facilmente descritíveis usando linguagens formais (apesar de valentes esforços). Desde a década de 1990, o paradigma no campo da IA tem sido em vez disso o aprendizado de máquina (ML). No aprendizado de máquina, em vez de codificarmos rígida e manualmente todos os detalhes das IAs nós mesmos, especificamos modelos com parâmetros livres que são aprendidos automaticamente a partir dos dados que recebem. Por exemplo, no caso do xadrez, em vez de usar um algoritmo fixo como faz o Deep Blue, um enxadrista de ML escolheria jogadas usando parâmetros que começam aleatórios, e gradualmente melhoram esses parâmetros com base no feedback que recebem as suas jogadas: isso é conhecido como aprendizado, treinamento ou processo de otimização.* Na teoria, modelos estatísticos (incluindo modelos simples como regressões lineares) também ajustam parâmetros aos dados que recebem. No entanto, os dois campos se distinguem pelas escalas em que operam: os maiores sucessos do aprendizado de máquina vieram do treinamento de modelos com bilhões de parâmetros em enormes quantidades de dados. Isso é feito usando aprendizado profundo, que envolve o treinamento de redes neurais com muitas camadas usando técnicas de otimização poderosas como a descida do gradiente e a retropropagação. As redes neurais existem desde o início da IA, mas só se tornaram o paradigma dominante no início da década de 2010, depois que o aumento na disponibilidade de recursos computacionais nos permitiu treinar redes muito maiores. Vamos explorar os componentes do aprendizado profundo com mais detalhes agora.
Aprendizado profundo: redes neurais e otimização
Redes neurais são um tipo de modelo de aprendizado de máquina inspirado no cérebro. Como em todos os modelos de aprendizado de máquina, elas recebem dados de entrada e produzem dados de saída correspondentes, de uma maneira que depende dos valores de seus parâmetros. A parte interessante é como elas fazem isso: passando esses dados por várias camadas de cálculos simples, de forma análoga ao modo como o cérebro processa dados passando-os por camadas de neurônios interconectados. No diagrama abaixo, cada círculo representa um “neurônio artificial”; redes com mais de uma camada de neurônios entre as camadas de entrada e saída são conhecidas como redes neurais profundas. Hoje em dia, quase todas as redes neurais são profundas e algumas têm centenas de camadas.
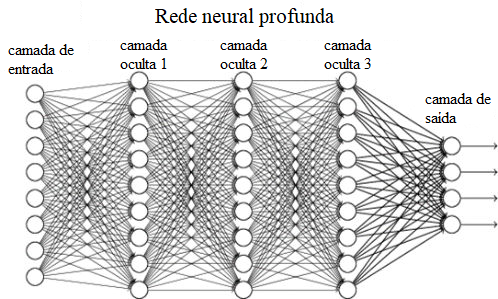
Cada neurônio artificial recebe sinais de neurônios na camada anterior, os combina em um único valor (conhecido como a sua ativação ) e então passa esse valor para os neurônios na próxima camada. Como em cérebros biológicos, o sinal que é passado entre um par de neurônios artificiais é afetado pela força da conexão entre eles — então, para cada uma das linhas do diagrama, precisamos armazenar um único número representando a força da conexão, conhecido como um peso. Os pesos das conexões de um neurônio com a camada anterior determinam a intensidade com que ele é ativado para qualquer dada entrada. (Em comparação com cérebros biológicos, as redes neurais artificiais tendem a ser muito mais rigorosamente organizadas em camadas.)
Esses pesos não são especificados manualmente, mas são, em vez disso, aprendidos por meio de um processo de otimização, que encontra pesos que fazem a rede marcar alto com base em qualquer métrica que estivermos usando. (Essa métrica é conhecida como função de objetivo ou função de perda; ela é avaliada sobre qualquer conjunto de dados que estivermos usando durante o treinamento.) De longe, o algoritmo de otimização mais comum é a descida do gradiente, que inicialmente define pesos para valores arbitrários e, a cada etapa, os altera para que a rede tenha um desempenho ligeiramente melhor em sua função de objetivo (em termos mais técnicos, ele atualiza cada peso na direção de seu gradiente com relação à função de objetivo). A descida do gradiente é um algoritmo de otimização muito geral, mas é particularmente eficiente quando aplicado a redes neurais porque a cada etapa os gradientes dos pesos podem ser calculados camada por camada, começando da última camada e trabalhando de trás para a frente, usando o algoritmo da retropropagação. Isso nos permite treinar redes que contêm bilhões de pesos, cada qual sendo atualizado bilhões de vezes.
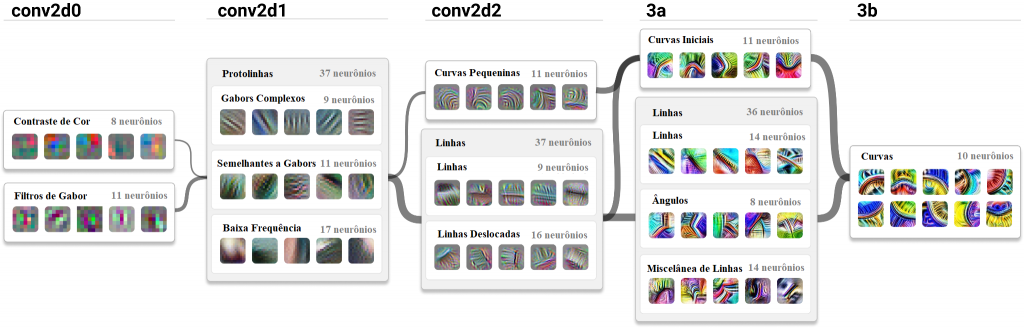
Como resultado da otimização, os pesos acabam armazenando informações que permitem que diferentes neurônios reconheçam diferentes características da entrada. Como exemplo, considere uma rede neural conhecida como Inception, que foi treinada para classificar imagens. Cada neurônio na camada de entrada da Inception foi atribuído a um único pixel da imagem de entrada. Os neurônios em cada camada sucessiva aprenderam a se ativar em resposta a características de nível cada vez mais alto da imagem de entrada. O diagrama mostra alguns dos padrões reconhecidos pelos neurônios em cinco camadas consecutivas do modelo Inception, em cada caso combinando padrões da camada anterior — de cores a (filtros de Gabor para) texturas, linhas, ângulos e curvas. Isso continua até a última camada, que representa a saída final da rede — neste caso, as probabilidades de a imagem de entrada conter gatos, cachorros e vários outros tipos de objetos.
Uma última coisa sobre redes neurais: em nosso diagrama de rede neural anterior, cada neurônio em uma determinada camada estava conectado a cada neurônio nas camadas próximas a ele. Isso é conhecido como uma rede totalmente conectada, o tipo mais básico de rede neural. Na prática, redes totalmente conectadas raramente são usadas; em vez disso, há toda uma gama de diferentes arquiteturas de redes neurais que conectam os neurônios de maneiras diferentes. Três das mais proeminentes (redes convolucionais, redes recorrentes e transformadores) estão listadas no diagrama de resumo original; no entanto, não cobrirei nenhum dos detalhes aqui.
Tarefas de aprendizado de máquina
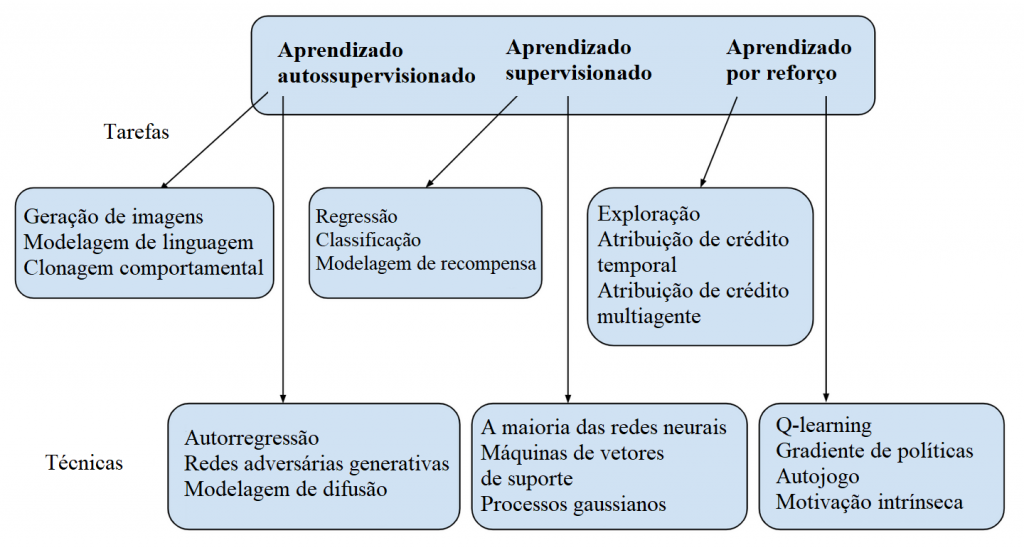
Descrevi como as redes neurais (e outros modelos de aprendizado de máquina) podem ser treinadas para realizar diferentes tarefas. As três categorias mais proeminentes de tarefas são supervisionadas, autossupervisionadas e aprendizado por reforço, cada uma envolvendo diferentes tipos de dados e funções de objetivo. O aprendizado supervisionado requer um conjunto de dados onde cada ponto de dados tem um rótulo correspondente. O objetivo do aprendizado supervisionado é que um modelo preveja os rótulos que correspondem a cada ponto de dados. Por exemplo, a rede de classificação de imagens que discutimos acima foi treinada em um conjunto de dados de imagens, cada qual rotulada com o tipo de objeto que continha. Alternativamente, se os rótulos fossem classificações sobre quão bonita cada imagem era, poderíamos ter usado o aprendizado supervisionado para produzir uma rede que avaliasse a beleza de imagens. Esses dois exemplos mostram diferentes tipos de aprendizado supervisionado: o primeiro é um problema de classificação (exigindo a previsão de categorias distintas) e o último é um problema de regressão (exigindo a previsão de valores contínuos). Historicamente, o aprendizado supervisionado tem sido a tarefa mais estudada em aprendizado de máquina, e as técnicas desenvolvidas para resolvê-la têm sido amplamente utilizadas como parte das soluções para as outras duas.
Uma desvantagem do aprendizado supervisionado é que a rotulação de um conjunto de dados geralmente precisar ser feita manualmente por humanos, o que é dispendioso e demorado. O aprendizado a partir de um conjunto de dados não rotulado é conhecido como aprendizado não supervisionado. Na prática, isso é tipicamente feito descobrindo modos automáticos de converter um conjunto de dados não rotulado para um rotulado, o que é conhecido como aprendizado autossupervisionado. O exemplo-padrão do aprendizado autossupervisionado é a previsão da palavra seguinte: treinar um modelo para prever, a partir de uma dada sequência de texto num conjunto de dados não rotulado, qual palavra decorre dessa sequência. Algumas aplicações impressionantes do aprendizado autosupervisionado são o GPT-2 e o GPT-3 para linguagem, e o Dall-E para imagens
Finalmente, no aprendizado por reforço, a fonte de dados não é um conjunto de dados fixo, mas sim um ambiente no qual a IA realiza ações e recebe observações — essencialmente como se estivesse jogando um videogame. Após cada ação, o agente também recebe uma recompensa (semelhante à pontuação de um videogame), que é utilizada para reforçar o comportamento que leva a altas recompensas e reduzir o comportamento que leva a baixas recompensas. Como ações podem ter consequências duradouras, a principal dificuldade no aprendizado por reforço é determinar quais ações são responsáveis por quais recompensas: um problema conhecido como atribuição de crédito. Até agora, as demonstrações mais impressionantes do aprendizado por reforço se encontraram no treinamento de agentes para jogar jogos de tabuleiro e esportes: principalmente o AlphaGo, o AlphaStar e o OpenAI Five.**
Resolvendo tarefas do mundo real
Estamos quase terminando! Mas não acho que mesmo um breve resumo sobre IA e aprendizado de máquina possa ser completo sem adicionar mais três conceitos. Eles não se encaixam na taxonomia que usei até agora; então modifiquei o diagrama de resumo original para encaixá-los:
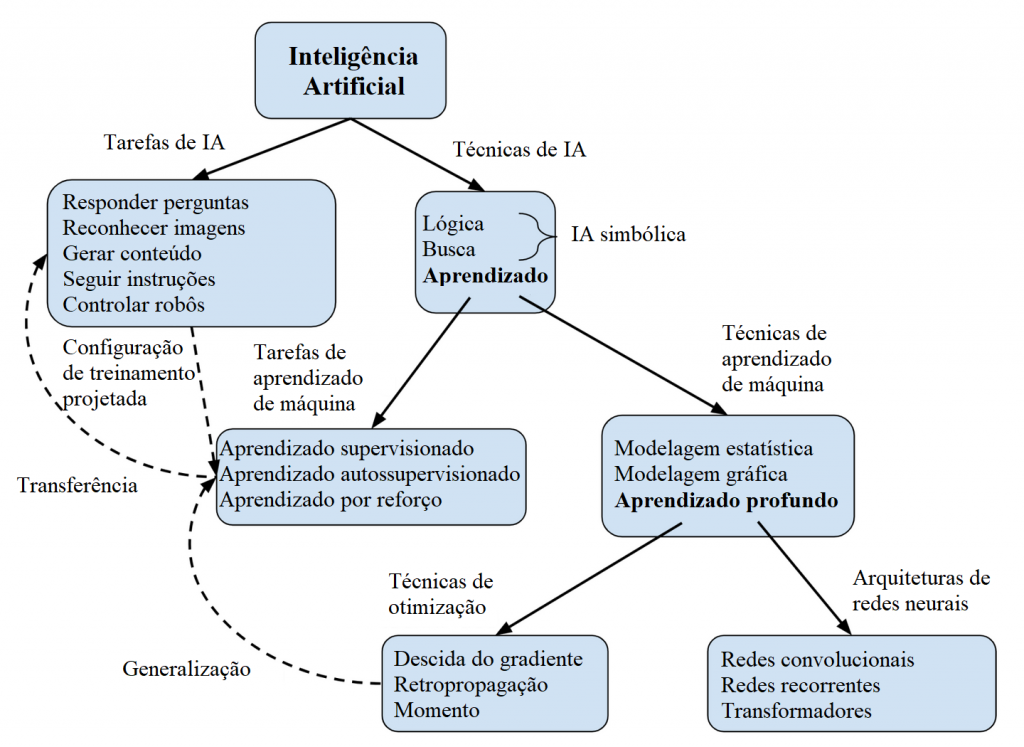
Vamos pensar nessas três linhas pontilhadas que acrescentei como modos de conectar os diferentes níveis. O objetivo final do campo da IA é criar sistemas que possam realizar tarefas valiosas do mundo real. A fim de aplicar técnicas de aprendizado de máquina para atingir isso, precisamos projetar e implementar uma configuração de treinamento supervisionada/autossupervisionada/de reforço que permita que o sistema aprenda as capacidades necessárias. Um elemento-chave é projetar conjuntos de dados ou ambientes de treinamento que sejam tão semelhantes quanto possível à tarefa do mundo real. No aprendizado por reforço, isso também requer projetar uma função de recompensa para especificar o comportamento desejado, o que com frequência é mais difícil do que esperamos.
Mas não importa quão boa seja nossa configuração de treinamento, enfrentaremos dois problemas. Em primeiro lugar, só podemos treinar nossos modelos em uma quantidade finita de dados. Por exemplo, ao treinar uma IA para jogar xadrez, existem muitas posições possíveis no tabuleiro que ela nunca irá vivenciar. Portanto, nossos algoritmos de otimização poderiam, na teoria, produzir IAs enxadristas que só conseguem jogar bem em posições que já vivenciaram durante o treinamento. Na prática, isso não acontece: em vez disso, o aprendizado profundo tende a generalizar incrivelmente bem para exemplos que ainda não viu. No entanto, como e por que isso acontece ainda é pouco compreendido.
Em segundo lugar, devido à imensa complexidade do mundo real, haverá maneiras como nossas configurações de treinamento serão representações incompletas ou enviesadas das tarefas do mundo real com as quais realmente nos preocupamos. Por exemplo, considere uma IA que foi treinada para jogar xadrez contra si mesma e que agora começa a jogar contra um ser humano com pontos fortes e fracos muito diferentes. Jogar bem contra o humano exige que ela transfira a sua experiência original para esta nova tarefa (embora seja muito tênue a linha entre generalização para diferentes exemplos “da mesma tarefa” versus transferência para “uma nova tarefa”). Também estamos começando a ver redes neurais cujas habilidades são transferidas para novas tarefas que diferem significativamente daquelas nas quais foram treinadas — sobretudo o modelo de linguagem GPT-3, que pode executar uma gama muito ampla de tarefas. Conforme desenvolvemos IAs cada vez mais potentes que realizam tarefas do mundo real cada vez mais importantes, garantir nelas um comportamento seguro irá exigir um entendimento muito melhor sobre como as suas habilidades e motivações irão transferir dos seus ambientes de treinamento para o mundo mais amplo.
Notas de rodapé
* Aprendizado, treinamento e otimização têm conotações ligeiramente diferentes, mas todos se referem ao processo pelo qual um sistema de aprendizado de máquina atualiza seus parâmetros com base nos dados.
** Aqui está uma análise mais detalhada de algumas das tarefas e técnicas correspondentes a esses três tipos de aprendizado. Mencionei apenas alguns desses termos até agora; incluí os outros para ajudar você a classificá-los, caso já os tenha visto antes, mas não se preocupe se muitos deles não forem familiares.
Tradução: Luan Marques
Link para o original