
Muitos programas governamentais e de caridade visam melhorar a educação, a saúde, o desemprego e assim por diante. Quantos desses esforços funcionam?
A grande maioria dos programas e serviços sociais ainda não foi rigorosamente avaliada, e… dos que foram rigorosamente avaliados, a maioria (talvez 75% ou mais), incluindo aqueles respaldados por opinião de especialistas e estudos menos rigorosos, acabam por produzir pequenos ou nenhum efeito e, em alguns casos, efeitos negativos.
Essa estimativa foi feita por David Anderson em 2008 no blog da GiveWell. Naquela época, ele era diretor assistente da Coalition for Evidence-Based Policy.
Esta se tornou uma estimativa amplamente citada, especialmente no comunidade de altruísmo eficaz, e muitas vezes é simplificada para “a maioria dos programas sociais não funciona”. Mas a estimativa tem quase dez anos, então decidimos investigar mais a fundo. Conversamos novamente com Anderson, assim como com Eva Vival, fundadora do AidGrade, e Danielle Mason, chefe de pesquisa da Education Endowment Foundation.
Concluímos que a estimativa original é razoável, mas que existem muitas complicações importantes. Parece enganoso dizer que “a maioria dos programas sociais não funciona” sem maiores esclarecimentos, mas é verdade que, concentrando-se em métodos baseados em evidências, você pode ter um impacto significativamente maior.
Analisaremos as estimativas feitas por Anderson, Vival e Mason, discutiremos as complicações e tentaremos chegar a uma conclusão geral no final.
1.Estimativas atualizadas de David Anderson
David Anderson é agora Diretor de Políticas Baseadas em Evidências na Laura and John Arnold Foundation, uma fundação beneficente multibilionária. Entramos em contato com ele e ele teve uma má notícia:
Se alguma coisa, a porcentagem de programas considerados fracos ou nenhum efeito quando avaliados rigorosamente pode até ser um pouco superior a 75%.
Ele passou a explicar:
Originalmente, dei essa citação à GiveWell como uma estimativa aproximada com base na revisão da nossa organização de centenas (agora provavelmente milhares) de ensaios controlados randomizados realizados em várias áreas da política social. Desde que fizemos essa estimativa, analisamos essa questão de forma um pouco mais sistemática.
Em 2015, a Fundação Arnold publicou um levantamento da literatura sobre programas que foram testados com ensaios clínicos randomizados (ECRs) como parte de uma solicitação de propostas de financiamento. Encontrou o seguinte:
Educação: Das 90 intervenções avaliadas em ECRs encomendados pelo Instituto de Ciências da Educação (IES) desde 2002, aproximadamente 90% apresentaram efeitos positivos fracos ou inexistentes.
Emprego/treinamento: Em ECRs encomendados pelo Departamento de Trabalho que relataram resultados desde 1992, cerca de 75% das intervenções testadas encontraram efeitos positivos fracos ou inexistentes.
Medicina: As revisões descobriram que 50-80% dos resultados positivos em estudos clínicos iniciais (“fase II”) são anulados em ECRs subsequentes e mais definitivos (“fase III”).
Negócios: De 13.000 RCTs de novos produtos/estratégias conduzidos pelo Google e pela Microsoft, 80-90% não encontraram efeitos significativos.
O ritmo atual de testes RCT é muito lento para construir um número significativo de intervenções comprovadas para resolver nossos principais problemas sociais. Da vasta diversidade de atividades programáticas em andamento e recém-iniciadas nos gastos sociais federais, estaduais e locais, apenas uma pequena fração é avaliada de maneira confiável para ver se funcionam. O governo federal, por exemplo, avalia apenas 1-2 dúzias desses esforços a cada ano em RCTs.
1.1.O que conta como um “efeito fraco”?
Uma dificuldade com essas estimativas é que elas são sensíveis à definição de um “efeito significativo”. Algumas variáveis incluem:
- A barra para significância estatística.
- Quão grande o tamanho do efeito precisa ser em relação ao custo.
- Como os resultados são escolhidos.
Nosso entendimento é que Anderson usou o teste padrão de significância de 5% para (1), e ele nos disse em correspondência que:
Estávamos focados em resultados fundamentais (relevantes para a política) extraídos de ECRs individuais, em oposição a meta-análises. Em termos dos efeitos em si, eu estava baseando minha estimativa para Give Well na regra geral que usamos na Coalition para determinar se algo “funcionou” – ou seja, se foi encontrado em um RCT bem conduzido para produzir efeitos consideráveis e sustentados em resultados importantes.
Os custos não foram explicitamente considerados.
Também podemos olhar diretamente para o estudo do IES mencionado acima para ver suas condições de inclusão, que estão de acordo com isso:
Nos casos em que o estudo mediu resultados intermediários (por exemplo, conhecimento do conteúdo do professor) e resultados mais importantes e relevantes para as políticas (por exemplo, desempenho do aluno), contamos o efeito nos resultados finais.
Nos casos em que o estudo mediu resultados intermediários e de longo prazo… contamos o efeito nos resultados de longo prazo.
Outra questão é como os estudos são escolhidos. Se você incluir muitos estudos com poucos participantes, a porcentagem de trabalho parecerá baixa, mesmo que a maioria deles o faça (esses são chamados de estudos de baixa potência). Na revisão da Arnold Foundation, no entanto, eles dizem que os estudos só foram incluídos se:
A amostra foi grande o suficiente para detectar um efeito significativo da intervenção.
2.Estimativas dentro do desenvolvimento internacional e meta-análises vs. ECRs
Até agora, falamos apenas sobre estimativas para programas baseados nos EUA, e falamos apenas sobre ensaios controlados randomizados individuais em vez de meta-análises – uma meta-análise pega todos os estudos existentes em um programa e os combina, com o objetivo de fornecer respostas mais claras sobre o que funciona. Eva Vival é a fundadora da AidGrade, que faz meta-análises de intervenções de desenvolvimento internacional, então ela estava bem posicionada para ajudar.
Vival fez algumas análises rápidas de seu conjunto de dados de RCTs para mostrar como a estatística depende das definições. Observe que essas são apenas estimativas improvisadas e podem ser revisadas em análises posteriores.
Começar com:
60-70% dos resultados individuais do RCT são insignificantes.
Isso é semelhante à estimativa de Anderson, embora uma porcentagem um pouco maior funcione.
No entanto, Vival apontou que é uma subestimativa da fração que funciona, porque (i) a maioria dos estudos tem uma amostra muito pequena para captar os efeitos (são “fracos”) e (ii) inclui todas as medidas de resultado, incluindo aquelas que não são muito importantes.
Se combinarmos os estudos por tipo de intervenção (por exemplo, mosquiteiros) e realizarmos uma meta-análise, então:
70-80% das intervenções (agregadas em coisas como “mosquiteiros”, “desparasitação”, etc., não projetos individuais) têm pelo menos um resultado positivo significativo se agregadas usando meta-análise de efeitos aleatórios.
Isso agora é surpreendentemente alto, mas ainda não é exatamente o número que queremos, porque (i) o resultado pode não ser importante e (ii) o tamanho do efeito pode ser pequeno em relação ao custo. Além disso, se muitos resultados são medidos, mas apenas um é significativo, as chances de um falso positivo são muito maiores, pelo motivo explicado aqui.
Como podemos identificar quais resultados são importantes? Uma opção é olhar para todas as combinações de intervenção-resultado que foram abordadas por vários estudos, uma vez que poucos estudos sobre um tipo de intervenção compartilham resultados em comum. A ideia é que, se muitos pesquisadores incluíssem o resultado, provavelmente pensariam que o resultado era importante. Restringindo a atenção para os resultados de intervenção compartilhados por pelo menos três artigos, encontramos:
60-70% dos resultados de intervenção que foram estudados têm resultados de meta-análise insignificantes.
O tamanho médio do efeito é de cerca de 0,1 desvios padrão.
No geral, o quadro parece semelhante às estimativas de Anderson, mas com uma fração um pouco maior funcionando. (Eles também estão alinhados com outros dados que vimos, como as Lições de Política do JPAL). No entanto, devemos suspeitar que uma proporção maior de meta-análises encontraria efeitos significativos em comparação com ECRs individuais. Isto é por várias razões:
Primeiro, provavelmente há uma seleção mais positiva com meta-análises, já que as pessoas não estudarão uma intervenção a menos que pensem que funciona, e a meta-análise se baseia em reunir resultados de vários estudos. Vival concorda e pensa que é uma estimativa otimista da distribuição subjacente.
Em segundo lugar, muitos estudos individuais são insuficientes e, portanto, não mostrarão efeitos estatisticamente significativos. No entanto, se a intervenção realmente funcionar, quando você combinar todos os estudos em uma meta-análise, obterá poder estatístico e encontrará um resultado positivo.
Terceiro, você pode imaginar que uma intervenção é ineficaz na maioria das circunstâncias, mas ocasionalmente tem fortes efeitos positivos. Considere três tentativas:
- Sem efeito significativo.
- Sem efeito significativo
- Três unidades de impacto.
Então, a proporção de ECRs individuais que “funcionam” é de apenas 33%, mas se fizermos uma média entre os estudos, o impacto médio seria de 1 unidade. Esta é uma simplificação grosseira do que uma meta-análise faria, mas ilustra a ideia básica. Diminuindo o zoom, se você acha que o desenvolvimento internacional funciona como um todo, quanto mais estudos combinarmos, maior a chance de um efeito positivo.
Um quarto fator pode ser que uma proporção maior de intervenções funciona no desenvolvimento internacional em comparação com os serviços sociais dos EUA. Se as pessoas são mais pobres, pode ser mais fácil encontrar maneiras simples de melhorar suas vidas que realmente funcionem e sejam grandes o suficiente para serem captadas por estudos. Em geral, devemos esperar que a fração que “funciona” varie de acordo com o domínio.
Finalmente, Vival estimou a fração de programas que são testados e fez uma estimativa aproximada semelhante a Anderson:
Talvez apenas cerca de 1-2% dos programas sejam avaliados com ECRs.
3.Meta-análises da educação no Reino Unido com Danielle Mason
A Education Endowment Foundation do Reino Unido fornece um fantástico “kit de ferramentas” que resume as evidências sobre diferentes intervenções educacionais do Reino Unido, para que possamos fazer as mesmas perguntas em outro domínio.
Danielle Mason, chefe de pesquisa da organização, nos disse que o kit de ferramentas tenta incluir todos os estudos quantitativos relevantes e de alta qualidade:
Para cada tópico do kit de ferramentas, capturamos todas as revisões e estudos existentes em inglês que atendem a um determinado limite de qualidade.
Cada tipo de intervenção é avaliado com base em (i) força de evidência, (ii) tamanho do efeito e (iii) custo. Veja aqui como essas pontuações são avaliadas.
Em 19 de junho de 2017, existem 34 tipos de intervenções no “kit de ferramentas de ensino e aprendizagem”, dos quais 31 tiveram pelo menos uma meta-análise realizada (ou seja, eles têm uma pontuação de pelo menos ⅖ para força de evidência).
Dentro disso, que fração desses 31 poderia ser considerada como “funciona”? Como dissemos, isso depende da definição que você usa, pois se algo funciona depende da relação entre custos e benefícios, e não há uma linha divisória clara. A EEF encoraja os usuários a considerar as compensações, em vez de dividir os tipos de intervenção entre aqueles que “funcionam” e “não funcionam”. Com isso dito, aqui estão alguns números aproximados para os 31 fios restantes:
- 2 (6%) tiveram efeitos negativos.
- 19 (61%) tiveram uma pontuação de impacto de pelo menos “3 pontos” (medido em meses de progresso), que é definido como “efeito moderado” na rubrica.
- Desses 19, um era caro em relação ao tamanho do efeito, então pode ser razoável contá-los como “não funcionando”.
- 2 tiveram uma pontuação de impacto de apenas “2 pontos”, mas estavam entre os mais baratos, então pode ser razoável contá-los como “funcionando”.
A porcentagem que funciona parece surpreendentemente alta, e talvez seja maior do que os números de Vivalt. Isso é semelhante às descobertas de John Hattie – de 1.200 meta-análises na educação, ele descobriu que o tamanho médio do efeito foi de 0,4 desvios padrão, sugerindo que a maioria das intervenções “funciona”. No entanto, muitas delas não são intervenções causais. Por exemplo, o item principal na lista de Hattie é “estimativas de desempenho dos professores”, que apenas mostra que os professores podem prever quais alunos se sairão bem, mas não nos diz como melhorar o desempenho dos alunos. Esperaríamos que o tamanho médio do efeito das intervenções causais fosse menor.
Além disso, não sabemos ao certo por que a porcentagem que funciona parece maior. Pode ser que os efeitos da seleção positiva sejam mais fortes nesta amostra, ou que haja mais viés de publicação na pesquisa em educação (como veremos adiante).
4.Outras fontes para investigar
A Colaboração Campbell faz meta-análises de programas sociais e a Colaboração Cochrane faz meta-análises de intervenções de saúde. Seria útil revisar a proporção desses que são significativos, mas nossa impressão aproximada ao navegar no banco de dados é que cerca de metade encontra resultados insignificantes.
5.E a crise de replicabilidade?
Mesmo que um RCT encontre um efeito positivo, quando outro grupo tenta executar o mesmo estudo (“replicar” as descobertas), eles geralmente não encontram nenhum efeito. A fração que não consegue replicar varia de acordo com o campo, mas geralmente está na faixa de 20 a 50%.
A crise de replicação é mais grave em assuntos como psicologia e pesquisa em educação, o que poderia explicar os achados aparentemente mais positivos em educação expostos acima. Na psicologia, mesmo as descobertas apoiadas por várias meta-análises e consenso de especialistas não conseguiram replicar. Você pode ler um relato popular do fracasso dos estudos de “esgotamento do ego” aqui. Uma tentativa recente de replicar vários estudos sobre “priming romântico” descobriu que todo o efeito era provavelmente devido ao viés de publicação. O gráfico abaixo mostra que os estudos originais encontraram um tamanho de efeito médio de 0,5, comparado a 0 para os estudos de replicação.
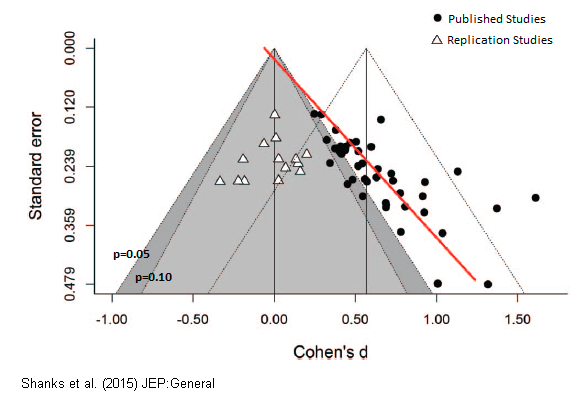
Acredita-se que a crise de replicação esteja acontecendo porque as técnicas estatísticas existentes oferecem muitas oportunidades para aumentar a significância aparente dos efeitos, e os efeitos positivos são muito mais prováveis de serem publicados do que os negativos. Portanto, mesmo que você tenha um RCT mostrando um efeito positivo, ainda há uma chance de 20 a 50% de que o verdadeiro efeito seja próximo de zero.
Em parte por esse motivo, John Ioannidis argumentou que “a maioria das descobertas de pesquisas publicadas são falsas”.
Alguns trabalhos mais recentes com foco em economia de Ioannidis et al em 2015 descobriram que:
Quase 80% dos efeitos relatados nestas literaturas de economia empírica são exagerados; normalmente, por um fator de dois e com um terço inflado por um fator de quatro ou mais.
Não fizemos nenhum ajuste adicional para essas preocupações em nenhuma de nossas estimativas acima, então provavelmente são superestimativas.
No entanto, esses problemas são muito menos graves se focarmos em estudos de alta qualidade, e ainda mais se usarmos meta-análises, como temos feito em muitas das estimativas. Se supusermos que 30% das descobertas não serão replicadas, se a proporção que parece funcionar começar em 35%, cairá para 25%.
Além disso, um próximo artigo de Vival e outros descobriu que o quadro é melhor na economia do desenvolvimento, uma vez que o campo contém um número relativamente grande de grandes estudos.1
6.O que podemos concluir de tudo o que foi dito acima?
É difícil dizer que fração das intervenções sociais “funciona” porque:
- Apenas alguns por cento são medidos rigorosamente, e muitos estudos são insuficientes.
- Isso torna os efeitos de seleção potencialmente graves. Se os pesquisadores tendem a estudar intervenções mais promissoras, então os resultados pintarão um quadro excessivamente otimista.
- A proporção que “funciona” é sensível a (i) os estudos incluídos, (ii) os resultados incluídos, (iii) onde você traça a linha para significância estatística, (iv) onde você traça a linha para o tamanho do efeito em relação ao custo, (v) se você se concentra em estudos individuais ou meta-análises, e quão amplamente você agrega, e (vi) em qual área você se concentra (por exemplo, saúde versus educação).
- Uma fração significativa desta pesquisa pode não ser confiável devido à crise de replicação (“p hacking”, viés de publicação, etc).
No entanto, quais podem ser algumas conclusões provisórias sobre a proporção que é efetiva?
Se nos concentrarmos nas principais medidas de resultados fundamentais:
- Dos projetos individuais, quando testados com ensaios controlados randomizados de boa potência, talvez mais de 80% não “funcionam”, ou seja, apresentam um tamanho de efeito razoável em relação ao custo.
- Talvez 1-10% tenham efeitos negativos.
- Dos tipos de intervenção que foram avaliados com meta-análises, a proporção que não “funciona” é provavelmente menor, talvez mais de 60% em vez de 80%, mas isso ocorre em parte apenas porque há mais atenção às intervenções mais promissoras.
- As intervenções e projetos que não foram testados são provavelmente piores, já que mais pesquisas são feitas sobre as abordagens mais promissoras.
- Se você considerar “áreas” inteiras (por exemplo, educação como um todo), então o efeito médio é provavelmente positivo. Isso é o que você esperaria se a área estivesse progredindo como um todo e houvesse alguma pressão, mesmo que fraca, para encerrar programas ruins. Isso é consistente com muitos projetos individuais que não funcionam e um pequeno número de projetos com fortes efeitos positivos, que é o que poderíamos esperar teoricamente.2
- O tamanho médio do efeito e a proporção de intervenções que funcionam provavelmente variam significativamente por área.
Então, é justo dizer que “a maioria dos programas sociais não funciona?”
Eu acho que isso é um pouco ambíguo e potencialmente enganoso. Projetos individuais geralmente não funcionam, mas áreas inteiras geralmente têm um impacto positivo. Então, se você escolher uma intervenção ao acaso, então, em média, seu impacto será positivo, porque há uma pequena, mas importante chance de você escolher uma das boas.
No entanto, se você puder se concentrar nas melhores intervenções em uma área de acordo com as evidências, poderá ter um impacto significativamente maior do que a média. Por exemplo, se dois terços das intervenções não funcionarem, então, se você puder evitá-las, terá cerca de três vezes mais impacto do que se trabalhasse em qualquer coisa em que tropeçar e escolhesse aleatoriamente.
Dado que também não podemos esperar que nossos instintos escolham com precisão, ainda é importante tentar o nosso melhor para nos concentrar em abordagens baseadas em evidências.
6.1.Quão importante é ser “baseado em evidências”?
Dito isso, o impulso de “ser baseado em evidências” não é tão grande quanto muitas vezes se diz na comunidade de altruísmo eficaz. Suponha que 10% das intervenções sejam altamente eficazes e tenham 10 unidades de impacto, enquanto 90% não funcionam. Se você puder escolher os 10% melhores, terá 10 unidades de impacto, enquanto se escolher aleatoriamente, terá:
10% * 10 + 90% * 0 = 1 unidade de impacto.
Portanto, o aumento no impacto que você obtém por ser baseado em evidências é 10 vezes maior. Mas, esse é um limite superior, porque, na realidade, os outros 90% terão algum impacto positivo. Além disso, suas medidas serão imperfeitas, então você não poderá identificar com precisão os 10% melhores, reduzindo ainda mais as diferenças.
Em geral, o tamanho do aumento de ser baseado em evidências depende do grau de disseminação da eficácia dentro da área e de quão boas são suas medições. A saúde global é provavelmente a melhor área nestes termos, uma vez que temos a maioria dos dados e há grandes diferenças de custo-benefício. Mas as melhores intervenções em saúde global são apenas cerca de dez vezes mais eficazes do que a média, e a diferença será menor após o ajuste pelo erro de medição ( regressão à média ).
Além disso, é possível que as melhores intervenções em uma área não sejam baseadas em evidências atuais – em vez disso, elas podem envolver a criação e o teste de novas intervenções ou a adoção de uma abordagem de alto risco e alta recompensa, como pesquisa ou defesa de políticas. Se você se ater apenas aos métodos baseados em evidências, pode perder aqueles que são de maior impacto. (Depende se as pessoas estão correndo muito ou pouco risco na área.)
Todos juntos, um ganho de dez vezes em eficácia provavelmente representa o máximo que você pode ganhar atualmente escolhendo intervenções baseadas em evidências e, na maioria das áreas, é provavelmente mais como um ganho de duas ou três vezes.3
Para ilustrar a importância de se basear em evidências, as pessoas da comunidade geralmente citam a diferença entre as melhores intervenções e as piores, ou a mediana. Esta é uma figura interessante, porque dá uma ideia da disseminação da eficácia, mas a alternativa a ser baseada em evidências é provavelmente mais como escolher aleatoriamente (na pior das hipóteses), em vez de escolher sistematicamente as piores intervenções (ou a mediana). Se você escolher aleatoriamente, terá uma pequena chance de escolher algo altamente eficaz por sorte, o que significa que sua eficácia esperada é igual à média. E você pode fazer ainda melhor do que escolher aleatoriamente usando teoria ou sua própria experiência.
Um ganho de duas a dez vezes no impacto de ser baseado em evidências é, pela maioria dos padrões, um grande negócio, mas é muito menor do que o impulso que você pode obter ao escolher a área de problema certa em primeiro lugar. Argumentamos usando nossa estrutura que os esforços em algumas áreas comuns podem ser mais de 100 vezes mais eficazes do que em outras.
Consulte Mais informação:
Leitura adicional:
- Nossos podcasts com Eva Vival e Rachel Glennerster : Quanto os estudos de ciências sociais generalizam?
- Você consegue adivinhar quais programas sociais funcionam?
- Quando você deve ir com seu intestino?
- Por que o altruísmo eficaz é importante?
7.Notas e referências
1. Descobrimos que a grande maioria dos estudos em nossa amostra são geralmente confiáveis.Coville, A., & Vivalt, E. (2017, 14 de agosto). Quantas vezes devemos acreditar em resultados positivos? Avaliando a Credibilidade dos Resultados da Pesquisa em Economia do Desenvolvimento.
Link para pré-impressão.
2. Sistemas complexos geralmente produzem resultados de “cauda gorda”, onde um pequeno número de resultados é muito maior que a mediana. Por exemplo, descobrimos que “sucesso na carreira” parece ser assim. (Se um resultado for causado por um produto de fatores normalmente distribuídos, então ele será log-normalmente distribuído.)
3. Embora a longo prazo, seja valioso construir uma cultura que atenda às evidências. Por exemplo, se você não atender a evidências rigorosas, poderá (1) ser influenciado por alegações extravagantes em áreas onde os dados não foram coletados e outros fatores que fazem com que você escolha algo pior do que aleatoriamente e (2) crie incentivos para adicionar uma quantidade ilimitada de más intervenções (já que qualquer intervenção terá sua parte na loteria).
Traduzido de: https://80000hours.org/articles/effective-social-program/