Paul Christiano, Buck Shlegeris 1 e Dario Amodei. 19 de outubro de 2018.
Índice
Resumo
Muitas tarefas de aprendizado do mundo real envolvem objetivos complexos ou difíceis de especificar, e usar um indicador mais fácil de especificar pode levar a um desempenho ruim ou a comportamento mal-alinhado. Uma solução é que humanos forneçam um sinal de treinamento ao demonstrar ou julgar o desempenho, mas essa abordagem falha se a tarefa for muito complicada para um humano avaliar diretamente. Propomos a Amplificação Iterada, uma estratégia de treinamento alternativa que progressivamente constrói um sinal de treinamento para problemas difíceis combinando soluções para subproblemas mais fáceis. A Amplificação Iterada está intimamente relacionada à Iteração de Especialistas (Anthony et al., 2017; Silver et al., 2017b), exceto que não utiliza uma função de recompensa externa. Apresentamos resultados em ambientes algorítmicos, mostrando que a Amplificação Iterada pode aprender comportamentos complexos de modo eficiente.
1. Introdução
Se quisermos treinar um sistema de aprendizado de máquina (ML) para realizar uma tarefa, precisamos ser capazes de avaliar quão bem ele está se saindo. Quer nosso sinal de treinamento assuma a forma de rótulos, recompensas ou algo completamente diferente, precisamos de alguma maneira de gerar esse sinal.
Se nosso objetivo puder ser avaliado automaticamente, como vencer um jogo de Go, ou se tivermos um algoritmo que possa gerar exemplos de comportamento correto, então gerar um sinal de treinamento é trivial. Nesses casos, poderíamos dizer que há um sinal de treinamento “algorítmico”.
Infelizmente, a maioria das tarefas úteis não possui um sinal de treinamento algorítmico. Portanto, nas aplicações atuais de aprendizado de máquina, muitas vezes os humanos fornecem o sinal de treinamento. Isso pode ser feito tendo um humano demonstrando a tarefa, por exemplo, rotulando uma imagem ou teleoperando um robô, ou pode ser feito aprendendo uma função de recompensa a partir de julgamentos humanos. Para essas classes de tarefas, poderíamos dizer que há um sinal de treinamento “humano”.
No entanto, existem tarefas mais difíceis para as quais não podemos calcular demonstrações ou recompensas mesmo com a assistência humana, e para as quais atualmente não temos um método claro para obter um sinal de treinamento significativo. Considere tomar decisões de política econômica, avançar na fronteira científica ou gerenciar a segurança de uma grande rede de computadores. Algumas dessas tarefas estão “além da escala humana”: um único humano não pode executá-las e não pode compreender bem o suficiente seu enorme espaço de observação para julgar o comportamento de um agente. É possível para um humano julgar o desempenho a longo prazo (por exemplo, observando o crescimento econômico ao longo de vários anos), mas tal feedback de longo prazo é muito lento para que se aprenda dele. Atualmente, não temos como aprender a executar essas tarefas muito melhor do que um humano.
A situação geral é representada na Tabela 1, que mostra seis combinações diferentes de fonte de sinal de treinamento e formulação do problema (aprendizado supervisionado (SL) ou aprendizado por reforço (RL). A maior parte da prática de ML opera no quadro do centro superior (aprendizado supervisionado a partir de rótulos humanos), no quadro inferior esquerdo (RL com uma recompensa programada) e às vezes no quadro superior esquerdo (aprendizado supervisionado de algoritmos). O quadro do centro inferior (RL a partir de um sinal de treinamento humano) está começando a ser explorado e inclui aprendizado de reforço inverso (Ng e Russell, 2000; Abbeel e Ng, 2004; Finn et al., 2016) e RL a partir de feedback humano (Knox e Stone, 2009; Pilarski et al., 2011; MacGlashan et al., 2017; Christiano et al., 2017). Atualmente, parece não haver um método geral para lidar com problemas no quadro inferior direito ou superior direito.
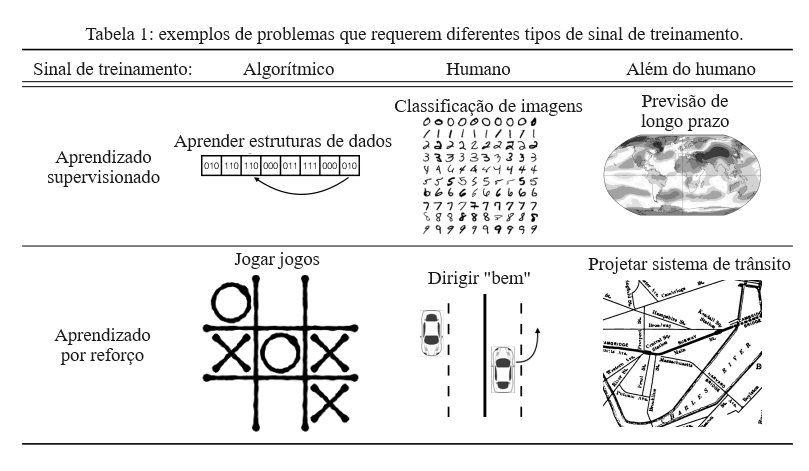
Sinal de treinamento, Algoritmo, Humano, Além do humano, Aprendizado supervisionado, Estruturas de dados de aprendizado, Classificação de imagens, Previsão de longo prazo, Aprendizado por reforço, Jogar jogos, Dirigir “bem”, Projetar sistemas de trânsito
Parece desejável expandir o leque de tarefas para as quais podemos obter um sinal de treinamento, por dois motivos. Primeiro, isso permitiria que sistemas de ML realizassem novas tarefas. SL e RL são métodos muito poderosos quando podemos obter um sinal de treinamento, de modo que torná-los aplicáveis a tarefas que os humanos não podem julgar ou executar diretamente poderia ter um grande impacto. Segundo, uma melhor especificação de objetivos e metas complexas pode ser essencial para construir sistemas de IA resilientemente benéficos. Na prática, quando um sinal de treinamento preciso estiver “além da escala humana”, muitas vezes encontramos um indicador de curto prazo que está correlacionado com o que queremos. Mas otimizar agressivamente esse indicador pode levar a comportamentos patológicos (Lehman et al., 2018; Amodei e Clark, 2016; Amodei et al., 2016), um exemplo da Lei de Goodhart.2 Por exemplo, podemos descobrir que a satisfação relatada pelo usuário (que podemos medir facilmente) é um bom indicador para o benefício a longo prazo para a sociedade (que é muito complicado), mas se o maximizarmos com RL, nosso agente pode manter aparências fraudulentas ou efetivamente manipular os usuários para fornecerem altas classificações. Em grande escala, esse tipo de patologia pode levar a colapsos sistêmicos, e uma discrepância entre indicadores e nossas preferências reais é uma fonte importante de preocupações sobre a segurança de futuros sistemas de IA poderosos (Bostrom, 2014).
Neste artigo, propomos uma estrutura geral para construir um sinal de treinamento em tarefas complexas, decompondo-as (com a assistência de IA) em tarefas mais simples para as quais temos um sinal de treinamento humano ou algorítmico. Em nossos experimentos, aplicamos a estrutura com várias simplificações (veja a Seção 4.3) para tarefas relativamente simples, como um primeiro passo para resolver os problemas descritos acima.
1.1. Nosso método: Amplificação Iterada
Propomos um novo método, a Amplificação Iterada, para um especialista humano H treinar um agente de ML X. Em vez de que H demonstre ou avalie o comportamento-alvo por conta própria, permitimos que ele invoque várias cópias do agente atual X para ajudá-lo. Escrevemos AmplifyH (X) para o sistema composto, consistindo em H e várias cópias de X que trabalham juntas para resolver um problema. O agente X então aprende com AmplifyH (X) da mesma forma que tradicionalmente aprenderia apenas com H.
Para instanciar essa estrutura, tomamos três decisões de projeto:
- Que conjunto de tarefas treinamos X para resolver? Para que X seja um assistente útil, precisamos escolher um conjunto de tarefas suficientemente amplo. Neste artigo, vamos nos concentrar na resposta a perguntas.
- Como construímos AmplifyH (X)? Neste artigo, focamos na delegação: AmplifyH (X) responde a uma pergunta Q fazendo com que H identifique uma sequência de subperguntas úteis, usando X para calcular uma sub-resposta para cada subpergunta, e fazendo com que H decida como responder Q após ver as sub-respostas.
- Como X aprende com AmplifyH (X)? Neste artigo, focamos no aprendizado supervisionado: X é um modelo autorregressivo treinado para prever a saída de AmplifyH (X). Trabalhos futuros poderiam, em vez disso, usar aprendizado por imitação ou usar AmplifyH (X) para definir uma função de recompensa que X maximize com RL.
Inicialmente, X se comporta aleatoriamente, de modo que AmplifyH (X) é essencialmente equivalente a H e estamos efetivamente aprendendo com um especialista. Com o tempo, o agente X se torna mais poderoso e o papel do especialista transita para “coordenar” várias cópias de X para resolver o problema melhor do que uma única cópia poderia fazê-lo. (Uma vez que X seja muito sofisticado, até mesmo tarefas como “identificar uma subpergunta útil” podem ser delegadas.) Desde que seja possível que múltiplos agentes resolvam colaborativamente problemas de forma mais eficaz do que um único agente (talvez usando expertise humana para coordenar seus esforços), então AmplifyH (X) pode superar X e, portanto, fornecer um sinal de treinamento útil. Discutimos essa suposição na Seção 5.
O humano deve estar envolvido nesse processo porque não há objetivo externo para orientar o aprendizado; o objetivo está implícito na maneira como o humano coordena as cópias de X. Por exemplo, não temos uma medida externa do que constitui uma resposta “boa” para uma pergunta; essa noção está apenas implícita em como um humano decide combinar as respostas às subperguntas (que geralmente envolvem tanto fatos quanto julgamentos de valor). Nosso objetivo é fazer com que X aprenda o objetivo ao mesmo tempo que aprende a se comportar competentemente. Isso contrasta com a abordagem alternativa de especificar uma função de recompensa e depois treinar um agente capaz de maximizar essa função de recompensa.
1.2. Linhas gerais
Na Seção 2, descrevemos a Amplificação Iterada e nossa implementação com mais detalhes. Na Seção 3, comparamos nossa abordagem com trabalhos anteriores. Na Seção 4, descrevemos nossos resultados experimentais, mostrando que a Amplificação Iterada pode ser estável e eficiente, apesar do sinal de treinamento não estacionário e da falta de objetivo externo. Na Seção 5, explicamos por que acreditamos que a decomponibilidade é uma suposição realista para tarefas complexas do mundo real.
2. Instanciação detalhada da Amplificação Iterada
2.1. Prevendo o comportamento humano
Para reduzir o ônus sobre o especialista humano H, treinamos um “previsor humano” H’ e utilizamos esse previsor para gerar dados de treinamento em vez de consultar H diretamente. Ou seja, treinamos H’ para imitar o papel de H ao calcular AmplifyH (X), e treinamos X usando AmplifyH’ (X) em vez de usar AmplifyH (X) diretamente.
Como H’ está apenas aprendendo a identificar subquestões e combinar sub-respostas, ao invés de resolver uma tarefa completa, esperamos treiná-lo com muito menos dados.
Note que H’ precisa prever como H responderá às sub-respostas fornecidas por X. Como X está em constante mudança, essa distribuição é não estacionária, e portanto precisamos atualizar continuamente H’ ao longo do processo de treinamento.
2.2. Visão geral do treinamento
Treinamos um agente X para responder a perguntas de uma distribuição D.
Nosso processo de treinamento, ilustrado na Figura 1, envolve a execução de quatro processos em paralelo:
- Repetidamente retiramos uma pergunta Q ∼ D como amostra, usamos AmplifyH (X) para responder a essa pergunta e registramos cada decisão tomada por H durante o processo. Ou seja, H encontra uma subpergunta Q1 que o ajudaria a responder a Q, e calculamos a resposta A1 = X(Q1). Repetimos esse processo k vezes, sendo k um parâmetro fixo, e então H calcula uma resposta A. Armazenamos a transcrição τ = (Q, Q1, A1, . . . , Qk, Ak, A).
- Treinamos um modelo H’ para prever as decisões tomadas por H em cada uma dessas transcrições, ou seja, para prever as subperguntas Qi e as respostas finais A.
- Repetidamente retiramos uma pergunta Q ∼ D como amostra, usamos AmplifyH’ (X) para responder a essa pergunta e registramos os pares resultantes (Q, A).
- X é treinado por aprendizado supervisionado nesses pares (Q, A).
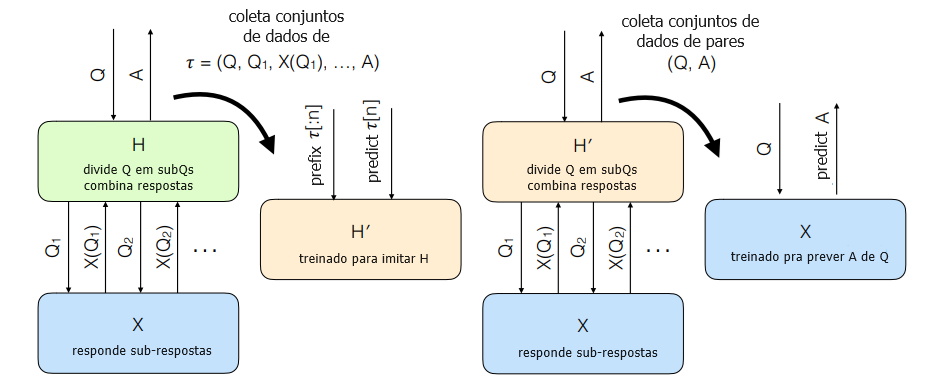
H divide Q em subQs, combina respostas, X responde a subperguntas, H’ treinado para imitar H, H’ divide Q em subQs, combina respostas, X responde a subperguntas, X treinado para prever A a partir de Q, coletar conjunto de dados de, prefixar, prever, coletar conjunto de dados de pares, prever
Figura 1: Esquema de nossa implementação da Amplificação Iterada.
2.3. Dinâmica do treinamento
O comportamento do agente X se desenvolve ao longo do treinamento:
- Inicialmente, X responde às perguntas aleatoriamente. Quando o humano faz subperguntas, frequentemente recebe sub-respostas incoerentes ou inúteis.
- O humano é capaz de responder a algumas perguntas sem nenhuma ajuda de X, e X acaba aprendendo a copiar essas respostas simples.
- Uma vez que X é capaz de fornecer respostas simples, o humano é capaz de fornecer respostas um pouco melhores dividindo-as em partes simples. Então X aprende a fornecer respostas um pouco melhores.
- Esse processo continua, com X expandindo gradualmente o conjunto de consultas que pode responder e melhorando gradualmente as respostas fornecidas. Em cada ponto do treinamento, AmplifyH (X) é modestamente mais inteligente do que X trabalhando sozinho, e X persegue esse alvo em movimento.
Se tudo correr bem, ao final desse processo, ficaremos com um agente que se “aproxima” do comportamento de uma equipe exponencialmente grande de cópias de H. A decomposição hierárquica em si é descartada como um artefato do treinamento, e o procedimento real aprendido pelo agente geralmente não refletirá a estrutura usada no treinamento.
2.4. Questões com contexto
Na prática, as perguntas frequentemente assumem a forma de um contexto muito grande (p. ex., um documento de design de cem páginas) e uma pergunta condicionada ao contexto relativamente pequena (p. ex., “quais são os maiores riscos ao implementar este design?”). Em particular, esse é o caso nos experimentos relatados na Seção 4.
Responder a uma pergunta requer entender o contexto inteiro, mas é possível decompor uma pergunta sem olhar para todo o contexto. Isso nos permite aplicar a Amplificação Iterada a tarefas em que o contexto é muito grande para um especialista humano observar diretamente. Em vez disso, podemos dar a H a habilidade de examinar pequenas partes do contexto conforme necessário. Com sorte, H pode decompor uma pergunta em partes que dependem de partes cada vez menores do contexto, até chegar a perguntas que dependem apenas de fatos isolados do contexto.
Contextos grandes também facilitam um truque importante para acelerar o treinamento. Em muitos cenários, quase todo o trabalho para responder a uma pergunta se trata realmente de entender o contexto, e é possível fazer muitas perguntas diferentes sobre um único contexto.
Dividimos X em duas fases, uma fase de codificação do contexto e uma fase de resposta à pergunta. Durante o treinamento, em vez de retirarmos uma única pergunta como amostra, retiramos um contexto junto com várias perguntas sobre esse contexto. Reutilizamos o trabalho da fase de codificação do contexto em todas essas perguntas. Da mesma forma, ao calcular AmplifyH (X), reutilizamos o trabalho de codificação do contexto entre todas as subperguntas a que X precisa responder. Em nossos experimentos, isso acelera o treinamento em uma ordem de grandeza.
2.5. Arquitetura do modelo
Implementamos X como uma arquitetura de codificador-decodificador com autoatenção, seguindo de perto a arquitetura de Transformer (Vaswani et al., 2017):
- Representamos o contexto como um conjunto de fatos, cada um dos quais é uma sequência de tokens.
- Incorporamos cada token usando uma tabela de busca. Incorporamos fatos concatenando as incorporações de tokens e aplicando uma projeção linear.
- Aplicamos o codificador-Transformer aos fatos incorporados. Nossa única alteração na arquitetura de (Vaswani et al., 2017) é a inserção de batchnorm após cada MLP (perceptron multicamada).
- Incorporamos perguntas da mesma forma que incorporamos fatos e então aplicamos o decodificador-Transformer a um lote de perguntas (omitindo completamente a autoatenção porque isso corresponderia a interações entre perguntas, que devem ser independentes).
- Um MLP autoregressivo gera uma sequência de símbolos condicionados ao resultado do decodificador-Transformer. Ele gera símbolos ou emitindo um conjunto de logits, ou escolhendo copiar um símbolo do contexto (como em redes de pontuação (Vinyals et al., 2015)).
O previsor humano H’ também é um decodificador-Transformer expandido com a capacidade de copiar símbolos de etapas anteriores. H’ opera em sequências de perguntas e respostas — assim como H, nunca observa o contexto inteiro.
Detalhes da arquitetura do nosso modelo são descritos no Apêndice D.
3. Trabalhos relacionados
Iteração de Especialistas: nosso método é muito semelhante à Iteração de Especialistas (ExIt) (Anthony et al., 2017) e ao AlphaZero (Silver et al., 2017b,a) e recentemente alcançou um forte desempenho nos jogos de tabuleiro Hex, Go, Xadrez e Shogi. A ExIt é em si muito análoga à atualização de Bellman no Q-learning, e tudo isso pode ser visto como análogo à programação dinâmica, na qual redes neurais substituem tabelas de pesquisa.
A diferença-chave entre nosso trabalho e a ExIt é a falta de um objetivo externo. Na ExIt, o especialista é produzido por um algoritmo de busca que otimiza um objetivo externo. Nossa contribuição é mostrar que um processo de treinamento semelhante pode ser usado mesmo quando a definição da tarefa é apenas implícita na estratégia de decomposição e recomposição.
Aprendizado por reforço inverso: ao observar o comportamento humano e inferir a função de recompensa subjacente que estão otimizando, (Ng et al., 2000; Hadfield-Menell et al., 2016) o aprendizado por reforço inverso também potencialmente aprende funções de recompensa para tarefas que são muito desafiadoras para os humanos. Lidar com tais tarefas requer um modelo suficientemente preciso da cognição humana para prever o que os humanos “prefeririam” se relaxássemos suas limitações cognitivas; além de ser extremamente complexo, tal modelo não é identificável, porque nunca observamos a verdade fundamental (ground truth) sobre as preferências humanas. A Amplificação Iterada é uma estratégia alternativa que não requer resolver esse problema desafiador de especificação de modelo.
Debate: treinar sistemas de IA para debater entre si (Irving et al., 2018) é outra abordagem possível para treinar sistemas de pergunta e resposta na qual um especialista humano não pode avaliar as respostas diretamente. Tanto o debate quanto a Amplificação Iterada envolvem uma estrutura recursiva na qual os sistemas de IA ajudam os humanos a responder subperguntas relevantes. A maior diferença conceitual é que na Amplificação Iterada cada subpergunta é respondida por uma cópia independente de X treinada por AmplifyH (X), enquanto em um debate as subperguntas são respondidas por um dos debatedores (que são treinados para defender uma resposta específica à pergunta de nível superior).
Aprendizado de algoritmos: nosso problema difere do trabalho tradicional sobre aprendizado de algoritmos (Graves et al., 2016; Kaiser e Sutskever, 2015; Neelakantan et al., 2015) porque não presumimos que temos acesso a rótulos de verdade fundamental.
Arquiteturas de modelos recursivos: nosso trabalho difere de arquiteturas de modelos recursivos (Cai et al., 2017; Nowak e Bruna, 2016), no sentido em que o modelo aprendido não possui uma estrutura recursiva. A decomposição recursiva é usada apenas para gerar dados de treinamento, e mesmo assim apenas uma única etapa de decomposição é realizada em cada iteração.
Portanto, o agente treinado pode acabar resolvendo a tarefa de uma maneira totalmente diferente da decomposição utilizada pelo humano e em particular pode aprender heurísticas que tratam o problema de forma holística.
Essa flexibilidade é importante para a aplicabilidade do nosso método. Muitas vezes é possível dividir uma tarefa em partes mais fáceis, mas dividir problemas interessantes em pedaços e resolvê-los de forma independente pode ser muito menos eficiente do que considerar o problema de forma holística.
4. Experimentos
4.1. Tarefas
Estudamos a Amplificação Iterada em um conjunto de 5 tarefas algorítmicas de brinquedo. Para cada tarefa, o agente X recebe um grande contexto combinatório e são feitas perguntas sobre esse contexto:
- Dada uma permutação σ : {1, . . . , 64} → {1, . . . , 64}, calcule σk (x) para k até 64.
- Dada uma função f : {1, . . . , 8} 2 → {1, . . . , 8} e uma sequência de 64 atribuições da forma x := 3 ou x := f(y, z), avalie uma variável específica.
- Dada uma função f : {0, 1} 6 → {−1, 0, 1}, responda a perguntas do tipo “Qual é a soma de f(x) sobre todos os x que correspondem à expressão-curinga 0 ∗ ∗ 1 ∗ ∗?”
- Dado um grafo dirigido com 64 vértices e 128 arestas, encontre a distância de s para t.
- Dada uma floresta enraizada com 64 vértices, encontre a raiz da árvore que contém um vértice x.
Descrições mais detalhadas das tarefas estão disponíveis no Apêndice C. Treinamos cada tarefa usando um currículo de instâncias menores, que não está relacionado ao nosso uso de Amplificação Iterada (o aprendizado supervisionado também precisa de um currículo para aprender essas tarefas em um período razoável de tempo, ainda que receba rótulos de verdade fundamental).
Em vez de que um humano realize a decomposição, fornecemos um algoritmo codificado H que decompõe cada tarefa (embora minimizemos o número de vezes que chamamos esse algoritmo). Usar essas decomposições diretamente como um algoritmo recursivo não é eficiente para nenhuma das tarefas.
4.2 Resultados
Para avaliar a Amplificação Iterada, comparamo-la com o aprendizado supervisionado a partir dos dados de verdade fundamental. Os resultados são apresentados na Figura 2. A Amplificação Iterada é capaz de resolver essas tarefas de forma eficaz, com no máximo uma desaceleração modesta, alcançando nosso principal objetivo.
O objetivo da amplificação é lidar com tarefas nas quais um especialista pode realizar a decomposição, mas não pode resolver a tarefa diretamente. Não esperamos que a amplificação resolva essas tarefas tão rapidamente quanto o aprendizado supervisionado. Por sermos capazes de aprender essas tarefas quase tão rapidamente quanto o aprendizado supervisionado a partir dos dados de verdade fundamental, alcançamos nosso principal objetivo.
Além de exigir um número modestamente maior de etapas de treinamento, o treinamento com amplificação requer cerca do dobro de computação por pergunta, pois precisamos realmente gerar os alvos de treinamento executando AmplifyH’ (X).3 Treinamos no mesmo tempo de relógio de parede, gerando dados em um trabalhador paralelo.
O aprendizado supervisionado exigiu dezenas de milhões de exemplos para aprender esses algoritmos. Isso seria um custo proibitivo se os exemplos fossem fornecidos por um especialista externo. Em contraste, a Amplificação Iterada exigiu dezenas de milhares de exemplos para aprender as decomposições muito mais simples (os números para cada tarefa estão na Tabela 2 no Apêndice A). A complexidade da amostra será muito maior para tarefas realistas, nas quais modelar H pode exigir (por exemplo) um modelo de linguagem de alta qualidade. Mas o fenômeno geral, de que aprender decomposições pode ser muito mais barato do que aprender comportamentos complexos diretamente, provavelmente se manterá para tarefas realistas, uma vez que realizar a decomposição é estritamente mais fácil do que resolver a tarefa sem a ajuda de X.
[imagem]
Precisão, Alimentação de permutação, atribuições sequenciais, busca-curinga, caminho mais curto, localização de união, total de questões, Supervisionado, Amplificação
Figura 2: Comparação entre Amplificação Iterada (laranja) e aprendizado supervisionado a partir de dados de verdade fundamental (azul). Para ilustrar melhor a dinâmica do treinamento, no Apêndice A, comparamos o desempenho de X e AmplifyH’ (X) separadamente para perguntas que requerem diferentes profundidades de recursão.
4.3. Simplificações
Esses experimentos fazem várias simplificações importantes:
- Em nossos experimentos, as perguntas podem ser decompostas algoritmicamente em subperguntas, e substituímos o humano por um algoritmo codificado à mão. Esses experimentos não esclarecem se seres humanos podem decompor tarefas interessantes do mundo real, nem se seria viável aprender decomposições confusas do mundo real.
- Trabalhamos em domínios combinatoriais nos quais é possível construir um sinal de treinamento algorítmico. Isso nos permite executar experimentos de forma econômica e avaliar facilmente nosso desempenho, mas a longo prazo nos importamos com tarefas nas quais não é possível construir um sinal de treinamento algorítmico ou até mesmo humano.
- Em nossos experimentos, X é treinado por aprendizado supervisionado a partir de AmplifyH (X). Em muitas aplicações importantes, suspeitamos que aprenderíamos uma função de recompensa a partir de AmplifyH (X) e então treinaríamos X para maximizar essa função de recompensa.
- Para que a Amplificação Iterada tenha sucesso, a distribuição de perguntas D precisa ser ampla o suficiente para cobrir não apenas as perguntas que nos importam, mas também todas as subperguntas feitas durante a computação de AmplifyH (X). A distribuição também determina como o modelo alocará sua capacidade, e portanto deve ser escolhida com cuidado. Em nossos experimentos, começamos com uma distribuição D que poderia ser usada diretamente. Em um cenário mais realista, poderíamos começar com alguma distribuição D‘ de perguntas que tenham interesse intrínseco, e seria responsabilidade do projetista do sistema construir D apropriadamente.
Remover essas simplificações é uma tarefa para trabalhos futuros, que, em última análise, testarão a hipótese de que a Amplificação Iterada pode ser aplicada de forma útil a tarefas complexas do mundo real para as quais nenhuma outra estratégia de treinamento está disponível.
5. Discussão da decomposição de domínios realistas
Após aplicarmos com sucesso a Amplificação Iterada a problemas algorítmicos sintéticos, a questão natural é se ela pode realmente ser aplicada a tarefas complexas do mundo real que estão “além da escala humana”. Deixamos uma demonstração convincente para trabalhos futuros, mas discutimos aqui por que acreditamos que isso é provável.
A suposição-chave subjacente à Amplificação Iterada é que um humano pode coordenar múltiplas cópias de X para ter um desempenho melhor do que uma única cópia de X.
Como exemplo, considere o problema de avaliar um projeto proposto para um sistema de trânsito. Em vez de forçar uma única cópia de X a chegar a um julgamento rápido sobre um projeto proposto, podemos fazer com que cópias de X avaliem muitas considerações diferentes (estimem custos, avaliem como o sistema atende diferentes populações, e assim por diante). Um humano pode então decidir como agregar essas diferentes considerações (potencialmente com ajuda de mais cópias de X). Detalhamos esse exemplo com mais profundidade no Apêndice B.
O problema de coordenar várias cópias de X para superar uma única cópia de X é análogo a organizar uma equipe de humanos para superar indivíduos humanos. Felizmente, existem várias maneiras como coordenar várias cópias de X é mais fácil do que coordenar uma equipe de humanos:
- Não exigimos que a colaboração seja eficiente, apenas que ela ajude de alguma forma. Se dez agentes trabalhando juntos obtiverem um desempenho “10% melhor” do que um único agente por conta própria, então AmplifyH (X) ainda fornece um sinal de treinamento útil que podemos usar para melhorar X.
- As cópias de X não precisam ser executadas em paralelo; cada uma pode começar depois que a anterior terminar sua tarefa. Muitas tarefas podem ser inerentemente difíceis de paralelizar, o que é um obstáculo para a colaboração humana, mas é aceitável para AmplifyH (X).
- Todas as cópias de X são treinadas exclusivamente para resolver o problema que lhes é dado. Não precisamos gerenciar incentivos, políticas ou preferências conflitantes, que são dificuldades comuns em organizações humanas.
Apesar dessas dificuldades, organizações humanas frequentemente conseguem superar significativamente indivíduos humanos em muitos domínios, apoiando nossa suposição fundamental.
6. Conclusão
Mostramos que a Amplificação Iterada pode resolver com sucesso tarefas algoritmicamente complexas nas quais não há uma função de recompensa externa e o objetivo está implícito em uma decomposição aprendida. Isso oferece esperança para aplicar ML em domínios nos quais não podemos calcular um objetivo adequado, mesmo com ajuda humana, desde que os humanos sejam capazes de decompor uma tarefa em partes mais simples. Se pudermos realizar essa esperança, será um passo importante para expandir o alcance do ML e lidar com preocupações sobre os impactos de longo prazo da IA, reduzindo nossa dependência de indicadores simples, porém imprecisos, para objetivos implícitos complexos.
Referências
Consulte as referências do documento original.
Notas:
1. Trabalho feito enquanto na OpenAI.
2. “Quando uma medida se torna o alvo, ela deixa de ser uma boa medida.”
3. Executar AmplifyH’ (X) requer chamar tanto X quanto H’ 3 e 10 vezes. Treinamos em cada par (Q, A) cerca de 10 vezes antes de removê-lo do conjunto de dados. Portanto, o tempo necessário para gerar um par (Q, A) é comparável ao tempo total gasto treinando-o, resultando em aproximadamente o dobro da computação total por pergunta.
Tradução: Luan Marques
Link para o original