De Yonadav Shavit. 30 de maio de 2023.
Índice
Resumo
Conforme as capacidades avançadas dos sistemas de aprendizado de máquina começam a desempenhar um papel significativo na geopolítica e na ordem social, pode se tornar imperativo que (1) os governos sejam capazes de impor regras sobre o desenvolvimento de sistemas avançados de aprendizado de máquina dentro de suas fronteiras e (2) os países sejam capazes de verificar a conformidade uns dos outros com potenciais acordos internacionais futuros sobre o desenvolvimento avançado do aprendizado de máquina. Este trabalho analisa um mecanismo para atingir isso: monitorar o hardware de computação usado para o treinamento de redes neurais em larga escala. O principal objetivo da estrutura é fornecer aos governos uma alta confiança de que nenhum ator usará grandes quantidades de chips de aprendizado de máquina especializados para efetuar uma execução de treinamento em violação das regras acordadas. Ao mesmo tempo, o sistema não restringe o uso de dispositivos de computação de consumidores e mantém a privacidade e a confidencialidade dos modelos, dados e hiperparâmetros dos profissionais de aprendizado de máquina. O sistema consiste em intervenções em três estágios: (1) usar firmware em chip para ocasionalmente salvar fotografias instantâneas dos pesos da rede neural armazenadas na memória do dispositivo, de uma forma que um inspetor possa recuperar posteriormente; (2) salvar informações suficientes sobre cada execução de treinamento para provar aos inspetores os detalhes da execução de treinamento que resultou nos pesos fotografados; e (3) monitorar a cadeia de suprimentos de chips para garantir que nenhum ator possa evitar ser descoberto acumulando uma grande quantidade de chips não rastreados. O plano proposto decompõe o problema de verificação de regras de treinamento de aprendizado de máquina em uma série de desafios técnicos restritos, incluindo uma nova variante do problema da Prova de Aprendizado [Jia et al. ’21].
1. Introdução
Muitos dos avanços notáveis dos últimos 5 anos em aprendizado profundo foram impulsionados por um aumento contínuo na quantidade de poder computacional de treinamento usado para desenvolver modelos de ponta [25, 21, 54]. Esse treinamento em larga escala foi possível por meio do uso simultâneo de centenas ou milhares de aceleradores especializados com alta largura de banda de comunicação entre chips (como TPUs da Google, GPUs NVIDIA A100 e H100 ou GPUs AMD MI250), empregados por um período de semanas ou meses para calcular milhares ou milhões de atualizações de gradientes. Referimo-nos a esses aceleradores especializados como chips de AM (aprendizado de máquina), que distinguimos das GPUs voltadas para o consumidor com menor largura de banda de interconexão (p. ex., a NVIDIA RTX 4090, usada em computadores para jogos).
Essa tendência de amplificação de poder computacional produziu modelos com capacidades cada vez mais úteis. No entanto, essas capacidades avançadas também trazem consigo maiores perigos de uso indevido [7]. Por exemplo, é cada vez mais plausível que criminosos possam em breve aproveitar modelos de geração e execução de código altamente treinados para identificar e explorar vulnerabilidades cibernéticas de forma autônoma, permitindo ataques de ransomware em uma escala sem precedentes1. Mesmo na ausência de intenção maliciosa, empresas ou países rivais presos em uma “dinâmica de corrida” de IA podem enfrentar uma pressão substancial para ser mesquinhos com testes e a mitigação de riscos, a fim de implementar sistemas de AM de alta capacidade à espera de superar seus concorrentes econômica ou militarmente. Os comportamentos extremos dos modelos de aprendizado profundo são notoriamente difíceis de depurar [20] e, sem testes e mitigação minuciosos, essas falhas em sistemas cada vez mais capazes podem ter consequências cada vez mais graves. Mesmo quando as partes rivais preferem fazer individualmente mais testes e mitigação de riscos, ou até mesmo renunciar totalmente ao desenvolvimento de tipos particularmente perigosos de modelos de AM [60], eles podem não ter modo algum verificar se seus concorrentes se equiparam a eles em nível de cautela.
Caso tais riscos surjam, os governos podem querer impor limites ao desenvolvimento em larga escala de modelos de AM. Embora empresas cumpridoras da lei obedeçam, atores criminosos, empresas negligentes e governos rivais podem não obedecer, especialmente se acreditarem que suas violações de regras passarão despercebidas. Portanto, seria útil aos governos ter métodos para verificar de forma confiável que as execuções de treinamento de AM em larga escala cumprem as regras acordadas.
Essas execuções de treinamento, por necessitarem atualmente de grandes quantidades de chips especializados, deixam uma grande pegada física e logística, o que significa que essas atividades geralmente são realizadas por organizações de tamanho considerável (p. ex., operadores de centrais de dados corporativas ou governamentais) bem equipadas para cumprir os regulamentos em potencial. No entanto, mesmo que as instalações relevantes sejam conhecidas, não há uma diferença facilmente observável entre treinar um modelo para o benefício social e treinar um modelo para uso indevido criminoso — eles exigem o mesmo hardware e, no máximo, diferem no código e nos dados que usam. Dada a promessa substancial das tecnologias de aprendizado profundo de beneficiar a sociedade, seria lamentável se os governos, em uma tentativa razoável de reduzir casos de uso prejudiciais, mas incapazes de distinguir o desenvolvimento de modelos de AM prejudiciais, acabassem reprimindo o desenvolvimento de aplicações benéficas do AM também. Essa dinâmica já está aparecendo: a justificativa do Departamento de Comércio dos EUA para seus controles de exportações em outubro de 2022, negando a venda de chips de alto desempenho para a República Popular da China, embora não seja específica ao AM, baseou-se em parte na preocupação de que esses chips possam ser usados para desenvolver armas contra os Estados Unidos ou cometer abusos de direitos humanos [5]. Se os governos dos EUA e da China pudessem chegar a um acordo sobre um conjunto de casos de uso benéficos permitidos para chips controlados por exportação e tivessem uma maneira de verificar a conformidade das empresas chinesas com esse acordo, talvez fosse possível impedir ou reverter restrições futuras.
Esse sistema de freios e contrapesos baseados em verificação, distinguindo entre treinamentos de modelos de AM “seguros” e “perigosos”, pode parecer inviável. No entanto, um sistema semelhante já foi criado. No alvorecer da era nuclear, as nações enfrentaram um problema análogo: o urânio para reatores (usado para energia) e o urânio para armas (usado para construir bombas nucleares) poderiam ser produzidos usando os mesmos tipos de centrífugas, apenas funcionando por mais tempo e em uma configuração diferente. Em resposta, em 1970, as nações do mundo adotaram o Tratado de Não Proliferação de Armas Nucleares (TNP) e autorizaram a Agência Internacional de Energia Atômica (AIEA) a verificar os compromissos dos países em limitar a disseminação de armas nucleares, enquanto ainda aproveitam os benefícios da energia nuclear. Essa estrutura de verificação ajudou o mundo a evitar conflitos nucleares por mais de 50 anos e ajudou a limitar a proliferação de armas nucleares a apenas 9 países, ao mesmo tempo que espalhou os benefícios da energia nuclear segura para 33 [40]. Se o progresso futuro no AM criar a vontade política nacional ou internacional para promulgar regras no desenvolvimento do AM em larga escala, é importante que a comunidade de AM esteja pronta com meios técnicos para verificar essas regras.
1.1. Contribuições
Neste artigo, propomos uma estrutura de monitoramento para aplicar regras no treinamento de modelos de AM2 que usem grandes quantidades de chips de AM especializados. Seu objetivo é permitir que os governos verifiquem se as empresas e outros governos cumpriram as proteções acordadas no desenvolvimento de modelos de AM que, sem as proteções, apresentariam um perigo para a sociedade ou para a estabilidade internacional. O objetivo deste trabalho é traçar um possível projeto de sistema, analisar sua viabilidade técnica e logística e destacar importantes desafios não resolvidos que devem ser enfrentados para que funcione.
A solução proposta tem três partes:
- Para provar a conformidade, um proprietário de um chip de AM emprega um firmware que registra informações limitadas sobre a atividade desse chip, com o emprego desse firmware atestado por meio de recursos de hardware. Propomos uma estratégia de registro de atividades que é leve e mantém a confidencialidade dos segredos comerciais e dados privados do proprietário do chip, com base nos pesos de rede neural presentes na memória de alta largura de banda do dispositivo.
- Ao inspecionar e analisar os registros de um subconjunto suficiente dos chips, os inspetores podem determinar se o proprietário dos chips efetuou uma execução de treinamento em violação das regras nos últimos meses, com alta probabilidade.
- Os países produtores de computação aproveitam o monitoramento da cadeia de suprimentos para garantir que cada chip seja contabilizado, para que os atores não possam adquirir secretamente mais chips de AM e, em seguida, declarar uma subestimação do seu total para se ocultar dos inspetores.
O sistema é compatível com muitas regras diferentes sobre execuções de treinamento (consulte a Seção 2.1), incluindo aquelas baseadas no total de horas de chip usadas para treinar um modelo, o tipo de dados e algoritmos usado e se o modelo produzido excede um limite de desempenho em referenciais selecionados. Para servir como base para uma coordenação internacional significativa, a estrutura aspira a detectar com segurança as violações das regras de treinamento de AM, mesmo diante de hackers de Estados-nação tentando contorná-la. Ao mesmo tempo, o sistema não força os desenvolvedores de AM a divulgar seus dados ou modelos de treinamento confidenciais. Além disso, como seu foco é restrito a chips especializados de centrais de dados, o sistema não afeta o uso de dispositivos de computação pessoal por indivíduos.
A Seção 2 introduz o problema de verificar regras no treinamento de AM em larga escala. A Seção 3 fornece uma visão geral da solução e descreve as inspeções ocasionais necessárias para validar a conformidade. As seções 4, 5 e 6 discutem as intervenções no nível do chip, no nível da central de dados e na cadeia de suprimentos, respectivamente. A Seção 7 conclui com uma discussão sobre os benefícios da proposta para diferentes partes interessadas e apresenta os próximos passos a curto prazo.
1.2. Limitações
A utilidade do sistema proposto depende da importância permanente do treinamento em larga escala para produzir os modelos de AM mais avançados (e, portanto, mais perigosos), um tópico de incerteza e desacordo atuais na comunidade de AM. O foco da estrutura também é restrito apenas às execuções de treinamento efetuadas em aceleradores de centrais de dados especializados, que hoje são efetivamente necessários para concluir as execuções de treinamento em maior escala sem uma grande perda de eficiência. No Apêndice A, discutimos se essas duas tendências provavelmente continuarão. Além disso, centenas de milhares de chips de AM já foram vendidos, muitos dos quais não possuem os recursos de segurança de hardware exigidos pela estrutura e podem não ser adaptáveis nem mesmo localizáveis pelos governos. A importância desses chips mais antigos pode diminuir gradativamente com a Lei de Moore. Mas em combinação com a possibilidade de treinamento menos eficiente usando chips não especializados, essas fontes de computação não monitoradas apresentam um limite inferior implícito no tamanho mínimo de execução de treinamento que pode ser detectado de forma verificável pelo sistema proposto. Ainda assim, pode ser que as execuções de treinamento de fronteira, que resultam em modelos com novas capacidades emergentes às quais a sociedade mais precisa de tempo para se adaptar, tenham maior probabilidade de exigir grandes quantidades de computação monitorável.
De maneira mais geral, a estrutura não se aplica ao treinamento de AM em pequena escala, que geralmente pode ser feito com pequenas quantidades de GPUs de consumo. Reconhecemos que o treinamento de modelos menores (ou o ajuste fino de modelos grandes existentes) pode ser usado para causar danos sociais substanciais (p. ex., modelos de visão computacional para drones terroristas autônomos [44]). Além disso, se um modelo for produzido por um treinamento em larga escala executado em violação de uma lei ou acordo futuro, os pesos desse modelo podem, daí em diante, ser copiados de forma indetectável e podem ser implementados usando GPUs de consumo [55] (como a inferência de AM exige uma largura de banda de comunicação entre chips muito menor). Prevenir a proliferação de modelos treinados perigosos é em si um grande desafio e está além do escopo deste trabalho. De forma mais ampla, é provável que a sociedade precise de leis e regulamentos para limitar os danos causados pelo uso indevido de tais modelos de AM por atores mal-intencionados. No entanto, aplicar de modo completo essas regras no nível do hardware exigiria vigilância e policiamento do uso que cidadãos individuais fazem de seus computadores pessoais, o que seria altamente inaceitável por motivos éticos. Em vez disso, este trabalho concentra a atenção rio acima, regulamentando se e como os modelos mais perigosos serão criados em primeiro lugar.
Por fim, em vez de propor uma solução abrangente em que já se pode pôr a mão na massa, este trabalho fornece um projeto de solução de nível alto. Sua contribuição está em isolar um conjunto de problemas em aberto cuja solução seria suficiente para possibilitar um sistema que atinja o objetivo da política. Se esses problemas forem insolúveis, o projeto do sistema precisará ser modificado ou suas garantias, reduzidas. Esperamos que, ao fornecer uma proposta específica à qual a comunidade possa responder, iniciemos um ciclo de feedback, iteração e contrapropostas que acabe culminando em um método eficiente e eficaz para verificar o cumprimento das regras de treinamento de AM em larga escala.
1.3. Trabalho relacionado
Este artigo junta-se a uma literatura existente que examina o papel que a computação pode desempenhar na governança da IA. Os primeiros trabalhos de Hwang [23] destacaram o potencial do poder computacional para moldar o impacto social do AM. O trabalho simultâneo de Sastry et al. [51] identifica atributos do poder computacional que o tornam uma alavanca útil exclusivamente para a governança e fornece uma visão geral das opções de diretrizes políticas. O trabalho intimamente relacionado de Baker [4] extrai lições do controle de armas nucleares para a verificação baseada em poder computacional de acordos internacionais sobre AM em larga escala.
Em vez de focar em políticas específicas, o trabalho propõe uma plataforma técnica para a verificação de muitos regulamentos e acordos possíveis sobre o desenvolvimento de AM. A Lei de IA da UE já propôs o estabelecimento de regulamentações baseadas em risco para produtos de IA [61], enquanto os senadores dos EUA propuseram uma “Lei de Responsabilidade Algorítmica” para supervisionar algoritmos usados em decisões cruciais [11], e a Administração do Ciberespaço da China (ACC ) estabeleceu um “registro de algoritmos” para supervisionar sistemas de recomendação [43]. Internacionalmente, muitos trabalhos anteriores discutiram a viabilidade geral e a conveniência do controle de armas de IA [47, 12, 37], com [52] destacando a importância de medidas de verificação para o sucesso de regimes potenciais de controle de armas de IA. Trabalhos anteriores também exploraram os benefícios da coordenação internacional na regulamentação da IA não militar [13].
A solução proposta envolve a prova de que uma execução de treinamento de AM em violação das regras não foi realizada, em parte pela prova de quais outras execuções de treinamento foram realizadas. A análise deste último problema é fortemente inspirada pela literatura sobre Prova de Aprendizado [24, 15] (discutido mais adiante na Seção 5). Outros trabalhos usaram ferramentas de criptografia para treinar modelos de redes neurais com segurança entre várias partes interessadas [63] e para provar com segurança que as inferências de redes neurais estão corretas [30]. No entanto, essas abordagens sofrem grandes penalidades de eficiência e ainda não podem ser amplificadas para o treinamento de modelos de ponta, tornando-as inviáveis como um método para verificar regras em execuções de treinamento em larga escala.
2. O problema: detectar violações de regras de treinamento de AM em larga escala
Focamos no cenário em que uma parte (o “Verificador”) procura verificar se um determinado conjunto de regras de treinamento de AM está sendo seguido e outra parte (o “Provador”) está desenvolvendo o sistema de AM e deseja provar ao Verificador que está cumprindo essas regras. O Verificador pode solicitar que o Provador tome medidas, como divulgar informações sobre execuções de treinamento, a fim de ajudar o Verificador a determinar a conformidade do Provador. O Provador é um “adversário oculto” [2]: ele pode se beneficiar da violação da regra de treinamento de AM, mas só tentará violar a regra se ainda puder parecer obediente ao Verificador. Existem duas relações do mundo real entre Provador e Verificador nas quais estamos particularmente interessados:
- Supervisão doméstica: os governos têm um claro interesse em que os sistemas de AM desenvolvidos por empresas que operam dentro de suas fronteiras cumpram certas regras. Os reguladores podem aplicar penalidades civis e criminais às organizações que violarem as regras e, muitas vezes, exigir que as organizações mantenham registros que comprovem a conformidade regulatória (p. ex., requisitos de manutenção de registros de transações financeiras).
- Supervisão internacional: os tipos mais significativos de regras de treinamento de AM podem ser aqueles aplicados internacionalmente (em empresas e governos em vários países) e verificados por outros governos ou órgãos internacionais. Isso inclui a aplicação de regras globalmente benéficas (p. ex., combate à desinformação) e a verificação de acordos de controle de armas (p. ex., limitação do desenvolvimento de armas cibernéticas autônomas que geram código). Há precedentes para países que cumprem acordos internacionais com regimes de monitoramento estritos quando podem se beneficiar, como o fato de que a Rússia historicamente permite inspeções aleatórias de seus mísseis pelos EUA como parte dos tratados de Redução de Armas Estratégicas, em troca da certeza de que os EUA estão cumprindo o mesmo limites de mísseis [53].
Assim, o problema que abordamos é: que conjunto mínimo de ações verificáveis o Verificador pode exigir que o Provador realize para possibilitar ao Verificador detectar, com alta probabilidade, se o Provador violou alguma regra de treinamento?
2.1 Que tipos de regras podemos impor monitorando o treinamento de AM?
É importante que os padrões e acordos sobre o treinamento de AM se concentrem na prevenção de danos concretos e deixem a sociedade livre para realizar os amplos benefícios dos sistemas de AM altamente capazes. De fato, existem muitos tipos de modelos de AM que não só deveria ser legal treinar, mas também devem ser de código aberto para que toda a sociedade possa se beneficiar deles [58]. A estrutura proposta se concentra apenas na aplicação de regras sobre o treinamento daqueles modelos mais perigosos cuja criação e distribuição prejudicariam substancialmente a sociedade ou a segurança internacional. De fato, conforme mencionado na Seção 1.2, essa estrutura não poderia impedir o treinamento de modelos de AM em menor escala e, portanto, limita o risco de excessos da parte de Verificadores autoritários. Abaixo estão algumas propriedades informativas que um Verificador pode determinar monitorando o processo de treinamento de um modelo de AM:
- Poder computacional de treinamento total, que provou ser um indicador para as capacidades dos modelos de AM [25, 59].
- Propriedades dos dados de treinamento, como se o conjunto de dados de texto de um modelo de linguagem contém código para explorações de segurança cibernética.
- Propriedades dos hiperparâmetros, como a fração dos passos treinados via aprendizado por reforço.
- O desempenho do modelo resultante em referenciais projetados para elicitar suas capacidades, incluindo se as capacidades do modelo excedem os limites acordados e incluindo referenciais interativos (p. ex, fazer ajuste fino do modelo em uma tarefa específica).
- Combinações dos itens acima: por exemplo, “se um modelo foi treinado em aprendizado por reforço para a geração de código por mais de X FLOPs, ele não deve ser treinado além do desempenho Y em referenciais Z”.
Em última instância, esses limiares de regras devem ser selecionados com base nas capacidades do modelo que resultariam. As extrapolações atuais da “lei de amplificação” ainda não são capazes de prever com segurança as capacidades subsequentes dos modelos de AM [16] e, portanto, encontrar métodos baseados em princípios para decidir sobre limiares de regras que alcancem os resultados políticos desejados é uma área importante para trabalhos futuros.
Se um Verificador puder detectar com segurança as propriedades de execução de treinamento acima mencionadas, isso permitiria que ele determinasse vários tipos de regras, como:
- Requisitos de relatórios sobre grandes execuções de treinamento, para conscientizar os reguladores domésticos sobre novas capacidades ou como uma medida de construção de confiança entre empresas/concorrentes [22].
- Proibições ou requisitos de aprovação para execuções de treinamento consideradas excessivamente propensas a resultar em modelos que ameaçariam a sociedade ou a estabilidade internacional. A aprovação pode ser dependente do atendimento de requisitos adicionais (p. ex., disposição a cumprir os regulamentos subsequentes sobre o uso de modelos, maior segurança para evitar o roubo de modelos, maior acesso a auditores).
- Exigir que qualquer modelo treinado seja modificado para incluir atenuações de segurança post-hoc se for esperado que o modelo não modificado apresente um risco grave de acidente na ausência dessas atenuações. Tais avaliações e mitigações de segurança (como ajustes finos “Úteis e Inofensivos” [3]) podem envolver um custo inicial proibitivo que empresas/governos evitariam sem a exigência. No entanto, uma vez que tiverem sido forçados a fazer o investimento e construído um modelo menos sujeito a acidentes, eles podem preferir usar a versão mais segura. Essas regras permitem que todas as partes coordenem o gasto de mais recursos em inovação segura e responsável, sem temer que seus concorrentes possam secretamente prejudicá-los ao avançar sem lidar com externalidades negativas.
2.2 Outros requisitos práticos
Existem várias outras considerações para que tal sistema de monitoramento seja prático. Seu custo deve ser limitado, limitando as alterações no hardware atual e também minimizando os custos de conformidade contínuos para o Provador e os custos de aplicação para o Verificador. O sistema também não deve apresentar um alto risco de vazamento de informações proprietárias do Provador, incluindo pesos de modelos, dados de treinamento ou hiperparâmetros. Mais importante, o sistema deve ser resistente a tentativas de trapaça, mesmo da parte de adversários com muitos recursos, como grupos de hackers de governos, que podem estar dispostos a empregar ataques sofisticados de hardware, software e até mesmo à cadeia de suprimentos.
3. Visão geral da solução
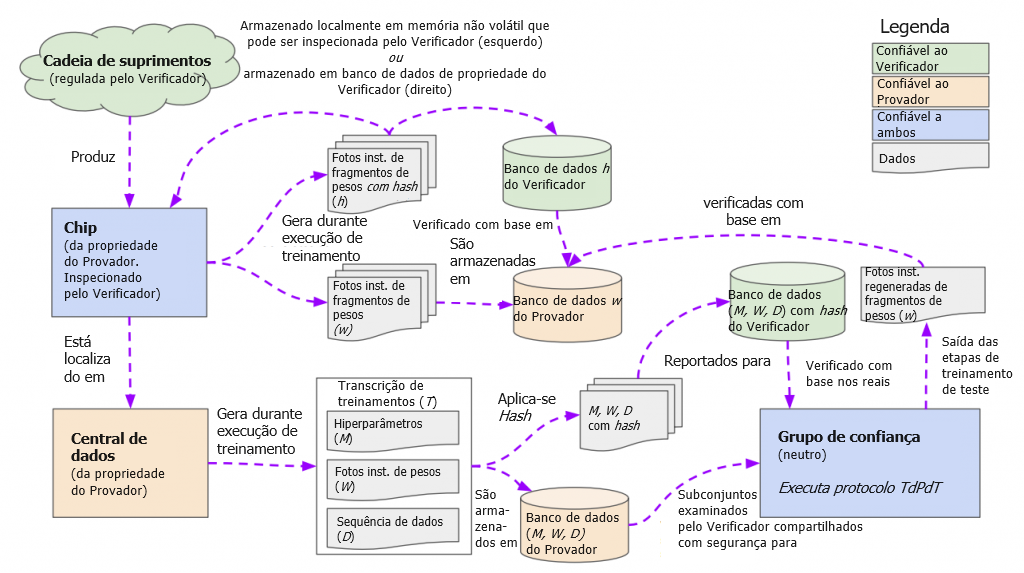
Nesta seção, descrevemos um plano técnico de nível alto, ilustrado na Figura 1, para os Verificadores monitorarem os chips de AM dos Provadores em busca de evidências de que ocorreu um grande treinamento em violação das regras. A estrutura gira em torno de inspeções de chips: o Verificador inspecionará uma amostra aleatória suficiente dos chips do Provador (Seção 3.2) e confirmará que nenhum desses chips contribuiu para uma execução de treinamento em violação das regras. Para que o Verificador verifique a conformidade com a simples inspeção de um chip, precisaremos de intervenções em três etapas: no chip, na central de dados do Provador e na cadeia de suprimentos.
- No chip (Seção 4): quando o Verificador obtém acesso ao chip de um Provador, ele precisa ser capaz de confirmar se esse chip estava ou não envolvido em uma execução de treinamento em violação das regras. Dado que violações de regras dependem apenas do código que foi executado, nossa solução exigirá que os chips de AM registrem rastros infrequentes de sua atividade, com o registro feito por meio de firmware com suporte de hardware. Sugerimos que o firmware dos chips de AM ocasionalmente registre uma cópia do estado atual da memória de alta largura de banda do chip para o armazenamento de longo prazo e, em particular, que registre o fragmento dos pesos da rede neural armazenados na memória. Essas fotografias instantâneas dos pesos podem servir como uma impressão digital do treinamento da rede neural que ocorreu em cada chip.
- Na central de dados (Seção 5): o Verificador precisa de uma maneira de interpretar os registros dos chips e determinar se eles são ou não evidências de uma execução de treinamento em violação das regras. Para isso, o Provador, que está treinando o modelo, terá a obrigação de armazenar uma transcrição do processo de treinamento — incluindo dados de treinamento, hiperparâmetros e pontos de verificação de pesos intermediários — para cada modelo que treinar. Usando protocolos semelhantes a “Prova de Aprendizado” [24], essas transcrições de treinamento podem servir como procedência para as fotografias instantâneas de pesos registradas, que são, elas próprias, o resultado do mesmo processo de treinamento. Na prática, para cada (hash de uma) fotografia instantânea de pesos registrada por um chip, o Provador fornece ao Verificador a (versão com hash da) transcrição de treinamentos correspondente. Em seguida, o Provador e o Verificador verificam em conjunto e com segurança que, com alta probabilidade, o retreinamento usando a transcrição do treinamento teria de fato resultado na fotografia instantânea de pesos registrada (e que nenhuma outra transcrição de treinamentos válida poderia ter resultado naquela fotografia instantânea). Finalmente, agora que o Verificador conhece uma transcrição aproximada da execução de treinamento que foi efetuada naquele chip naquele momento, ele pode examinar as propriedades da transcrição de treinamentos para confirmar que o Provador cumpriu as regras acordadas.
- Na cadeia de suprimentos (Seção 6): o Verificador precisa saber quais chips de AM o Provador possui, para que o Verificador possa inspecionar aleatoriamente uma amostra representativa desses chips, para confirmar a sua propriedade e se seus mecanismos de registro estão relatando corretamente. Sem essa etapa de verificação da propriedade dos chips, um Provador pode adquirir secretamente uma grande quantidade de chips e usá-los para treinamentos sem notificar o Verificador. Estar a par da propriedade de chips é viável porque a cadeia de suprimentos de chips de centrais de dados de ponta é altamente concentrada, o que significa que os chips se originam de alguns pontos de estrangulamento iniciais e podem ser monitorados a partir daí.
Essas etapas, em conjunto, possibilitam uma cadeia de garantias.
- Quando qualquer organização deseja treinar um grande modelo de AM que viola regras, deve fazê-lo usando chips que o Verificador conheça.
- Esses chips ocasionalmente registram fotografias instantâneas de pesos. Cada vez que um chip registra uma fotografia instantânea de pesos, o Provador deve relatar o registro ao Verificador, juntamente com (hashes de) transcrições de treinamentos que estabelecem a procedência dessa fotografia instantânea de pesos.
- Se o Provador tentar ocultar os registros de todos os chips envolvidos na execução de treinamento, o Verificador acabará descobrindo, pois irá tirar amostras e inspecionar fisicamente pelo menos um desses chips com alta probabilidade.
- Além disso, as transcrições de treinamentos com hash que o Provador fornece junto com a fotografia instantânea de pesos registrada precisam ser autênticas, refletindo a execução de treinamento que foi efetuada no chip. Se não forem autênticas, serão capturadas pelo procedimento de verificação de transcrição do Verificador.
- Se a transcrição de treinamentos é autêntica e a execução violou as regras, o Verificador pode determinar isso e pegará o Provador.
Assim, desde que o Provador cumpra os passos do Verificador, o Verificador detectará a violação de regra do Provador com alta probabilidade. Assim como nas auditorias financeiras, a recusa do Provador em cumprir as etapas de verificação representaria, por si só, um indício de culpa.
3.1 Inspeção de chips
Idealmente, os chips poderiam relatar remotamente seus registros, com firmware em chip e atestado remoto sendo suficientes para garantir que esses registros fossem relatados com veracidade (consulte a Seção 4). Tais garantias podem ser suficientes para dissuadir a maioria dos Provadores do mau comportamento. Infelizmente, essas medidas podem não restringir Provadores adversários com bons recursos: geralmente é entendido no mundo da segurança de hardware que, dado acesso físico ilimitado a um chip (o que o Provador certamente teria), a atestação de um chip e mecanismos de imposição de firmware assinado podem ser comprometidos [56]. No entanto, inspecionando fisicamente os chips após o ocorrido, pode ser possível detectar com segurança tal adulteração. Isso ocorre porque a maioria dos ataques de hardware exige danos físicos ao chip de maneiras que seria quase impossível ocultar da inspeção subsequente de um Verificador, especialmente se os chips de AM forem complementados com medidas de embalagem invioláveis [64]. Felizmente, em vez de precisar inspecionar cada chip, precisamos apenas inspecionar o suficiente para capturar pelo menos um chip de cada grande execução de treinamento (Seção 3.2).
Uma inspeção de chip pode ser feita de duas maneiras. O Verificador pode enviar um inspetor para a instalação em que um chip amostral é armazenado, o que pode ser econômico se a instalação contiver vários chips selecionados para amostragem. Como alternativa, os chips de AM podem ser transportados para um local de inspeção neutro, visto que esses chips geralmente são alojados em servidores facilmente removíveis. (Componentes sensíveis, como armazenamento, podem ser removidos antes do transporte.) A opção de transporte pode ser mais atraente para os Provadores preocupados com a segurança, que preferem não permitir que os inspetores-Verificadores entrem em suas centrais de dados.
Uma inspeção de chip envolve várias etapas. Primeiro, o Verificador confirma que o número de série do chip (muitas vezes gravado nos chips e acessível digital e fisicamente) corresponde ao número de série solicitado ao Provador. Isso confirma que esse é o chip de amostra aleatória correto e também que o Provador ainda possui o chip e não o revendeu secretamente para uma parte não confiável. Em segundo lugar, o Verificador verifica os registros em chip, dos quais ele extrai os hashes de fotografias instantâneas de pesos que serão verificados com base nas transcrições de treinamento relatadas pelo Provador (seção 5). Por fim, o Verificador verifica se os mecanismos de registro do chip, como seu mecanismo seguro de autenticação de firmware (Seção 4), não foram adulterados fisicamente.
3.2 Quantos chips de AM o Verificador precisa inspecionar?
As seções 4, 5 e 6 juntas garantirão que, se o verificador observar até mesmo um único chip de AM que registrou um hash de fotografia instantânea de pesos durante uma execução de treinamento em violação das regras, o Verificador poderá usar essa fotografia instantânea de pesos para provar que o Provador violou as regras. Para que o Verificador tenha certeza de que observaria pelo menos uma dessas fotografias instantâneas de uma grande execução de treinamento com alta probabilidade (ou, alternativamente, pegaria um chip que foi adulterado), ele precisaria inspecionar pelo menos s dos chips C do Provador a cada Tm dias. Agora procuramos calcular s.
Definimos uma execução de treinamento em larga escala como qualquer execução de treinamento que use mais de H FLOPs. Procuramos apenas verificar as regras nas execuções de treinamento que usam > H FLOPs, o que significa que quaisquer fotografias instantâneas de pesos dos primeiros H FLOPs não são incriminadoras (já que o Provador poderia ter interrompido a execução de treinamento após essa fotografia instantânea). Pegar um chip que calhou de salvar uma fotografia instantânea de pesos no tempo H + ε é extremamente improvável para um ε pequeno, de modo que antes fornecemos garantias na detecção do caso em que a execução de treinamento do Provador é executada por ≥ 2H, excedendo substancialmente H3 . Isso significa que a execução de treinamento foi efetuada por um segundo período adicional de pelo menos H FLOPs, durante o qual qualquer fotografia instantânea de pesos capturaria evidências de um modelo de AM que já tivesse sido treinado por pelo menos > H FLOPs. A partir daqui, quando descrevemos a detecção de uma fotografia instantânea de uma “execução de treinamento em larga escala”, referimo-nos a esse segundo estágio da execução de treinamento. Se um Verificador quisesse pegar um Provador antes que ele tivesse concluído uma execução de treinamento em violação de regras H, ele poderia simplesmente reduzir seu limite-alvo para uma fração de H e tirar amostras de chips continuamente.
O Verificador, seja devido a suspeitas específicas, seja devido a devida diligência de rotina, deseja auditar os chips C de um determinado Provador. Seja a os FLOPs por dia para esses chips. Presumiremos conservadoramente que o treinamento de redes neurais pode ser perfeitamente paralelizado e utilizar todos os FLOPs em cada chip. Seja f o número esperado de fotografias instantâneas de pesos salvas pelo chip por dia (Seção 4). As fotografias instantâneas estão numa distribuição de Poisson. O Verificador deseja pegar uma execução de treinamento dentro de no máximo Tm dias após sua conclusão, embora a execução de treinamento em si possa ter durado por um período mais longo 4 T > Tm. Isso implica que o Provador deve ter usado um mínimo de H/aT chips. Pode-se esperar que, ao aumentar T, o Provador possa usar menos chips e, portanto, evadir a detecção, mas isso não melhora significativamente a probabilidade de evasão do Provador (um aumento de < 5%), porque cada chip é retirado como amostra com uma frequência de T/Tm vezes. (Consulte o Apêndice C para obter detalhes.) Portanto, para simplificar, presumimos que o Verificador vá escolher s como se T fosse fixo.
Para detectar pelo menos um chip com uma fotografia instantânea de uma execução de treinamento em violação de regras com probabilidade p, o Provador precisa tirar s chips como amostras a cada período de monitoramento Tm, onde:
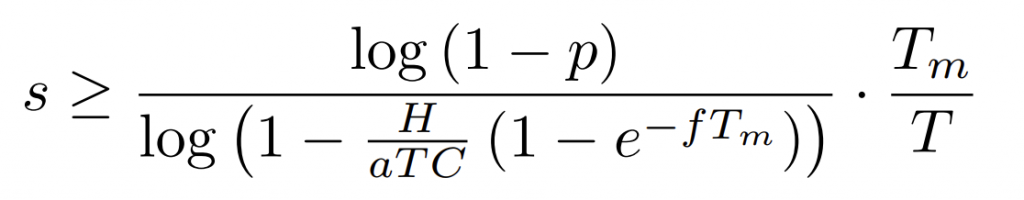
Na Tabela 1, fornecemos o total necessário de amostras por ano 365 · s/Tm para capturar várias execuções de treinamento passadas e projetadas, para Provadores que possuem diferentes quantidades de chips C. Como mostra a tabela, o número de chips inspecionados permanece aproximadamente em uma fração fixa do estoque completo, diminuindo com o tamanho da execução de treinamento H.
Uma dificuldade adicional é a possibilidade de vários Provadores conspirarem e cada um contribuir com uma pequena fração de seus chips para uma execução de treinamento compartilhada, de modo que, se apenas um dos Provadores for auditado, a fração de seus chips C que eles usaram para a execução de treinamento é muito menor que H/aTmC. Isso é particularmente relevante no cenário de Supervisão Internacional, onde um Provador governamental pode forçar a participação de várias empresas. Uma solução para isso é um Verificador internacional fazer o monitoramento de segundo plano de todos os Provadores, tratando-os, efetivamente, como um grande Provador com acesso ao estoque global de chips. Previsivelmente, isso exigiria um número muito maior de amostras e provavelmente seria viável apenas para regulamentar as execuções de treinamento das maiores escalas (que podem ser capturadas com menos amostras). No entanto, para execuções de treinamento na escala de 10^25 FLOPs ou mais, o monitoramento pode ser feito com uma burocracia semelhante em tamanho à IAEA5.
À medida que os chips individuais se tornam mais poderosos (a cresce) e a eficiência algorítmica aumenta (H diminui), o número de amostras necessárias precisaria crescer para verificar as regras em uma execução de treinamento de capacidade fixa. Ainda assim, pode ser que as execuções de treinamento de maior preocupação social sejam aquelas próximas à fronteira da amplificação, e é provável que permaneçam detectáveis com poucas amostras no futuro previsível, mesmo que os Provadores tentem prejudicá-las com adulteração física.
| Modelo | FLOPS de Treinamento H | H100- dias H/a | H100s para treinar em 1 ano | Amostras/ano se C = 10³ | Amostras/ano se C = 10⁵ | Amostras/ano se C = 10⁷ |
| GPT-3 [6] | 3.14e+23 | 3.64e+3 | 10 | 243 | 2.43e+4 | 2.43e+6 |
| Chinchilla [21] | 5.76e+23 | 6.67e+3 | 19 | 132 | 1.33e+4 | 1.33e+6 |
| PaLM [10] | 2.56e+24 | 2.96e+4 | 82 | 29 | 2.98e+3 | 2.99e+5 |
| Chinchilla-280B | 9.9e+24 | 1.15e+5 | 314 | 7 | 771 | 7.72e+4 |
| Chinchilla-1T | 1.27e+26 | 1.47e+6 | 4.03e+3 | – | 60 | 6.02e+3 |
| Chinchilla-10T | 1.3e+28 | 1.5e+8 | 4.12e+5 | – | – | 58 |
4. No chip
Em um cluster de treinamento de rede neural, um grande número de dispositivos de AM (cada um contendo um chip de AM e conectado a um chip de CPU “hospedeiro”) colabora para calcular simultaneamente atualizações de gradiente. Grandes redes neurais têm pesos demais para caberem na memória de alta largura de banda de um único dispositivo de AM; portanto, o treinamento eficiente de um modelo requer a divisão dos pesos do modelo em fragmentos de pesos e a colocação de um fragmento em cada chip [57]. Cada fragmento tal é um vetor de milhões ou bilhões de valores. Fragmentos são atualizados após cada etapa de gradiente de modo que novos gradientes sempre possam ser calculados com relação aos valores de peso mais recentes. Isso significa que, a cada passo temporal, o chip contém um resultado atualizado da execução de treinamento, que, como mostraremos na Seção 5, pode servir como uma espécie de soma de verificação para a execução de treinamento.
Nesta seção, descreveremos como pode ser possível fazer com que os chips de AM registrem os valores desses vetores de fragmentos de pesos para que os Verificadores inspecionem retroativamente. Presumiremos a presença de certos recursos de hardware6 no chip de AM, embora os detalhes da abordagem possam precisar ser modificados dependendo das especificidades do dispositivo. Por exemplo, se o chip de AM não tiver o hardware necessário para a atestação de firmware remota, o chip pode precisar estar permanentemente casado com uma CPU hospedeira que tenha esse hardware, com a CPU orquestrando as operações de registro.
Os fragmentos de pesos de um chip podem ser capturados com uma fotografia instantânea da memória de alta largura de banda do chip, que contém os pesos. Essas fotografias instantâneas devem ser salvas em momentos aleatórios, caso contrário, o Provador pode trocar os pesos verdadeiros por um conjunto falso de pesos logo antes do registro agendado. Com uma pequena probabilidade a cada ciclo de relógio, o firmware presente em cada um dos chips do Provador deve gerar uma interrupção e congelar brevemente as operações do chip. O chip deve então enviar uma cópia das regiões de fragmentos de pesos ω para sua CPU hospedeira para salvar no armazenamento de longo prazo controlado pelo Provador. O firmware também calcula um hash h = H(ω) das regiões de memória relevantes7, usando uma função hash criptográfica publicamente aceita H.
Esse hash h é então salvo para o Verificador encontrá-lo mais tarde, seja fazendo com que o firmware o armazene no chip8 em memória não volátil gravável apenas pelo firmware, seja fazendo com que o chip assine o hash com sua chave privada e, em seguida, enviando-o para um servidor central no qual o Verificador confie (que deve retornar uma confirmação de recebimento antes que o chip possa retomar a operação). Mais tarde, um Verificador pode usar h para pedir ao Provador que lhe forneça o fragmento de peso original ω, já que essa é a única entrada para H cujo hash corresponde a H(ω) = h.
Fotografias instantâneas mais frequentes significam mais sobrecarga de desempenho para o Provador, especialmente se todos os outros chips sincronizados na execução de treinamento devem travar até que a fotografia instantânea do chip único seja concluída. Esse congelamento pode se tornar caro se o restante da execução de treinamento precisar travar até que seja concluído, especialmente se for feito por muitos chips. 9 A frequência das fotografias instantâneas deve ser definida o mais baixo possível, ao mesmo tempo que garante que os chips usados contenham de forma confiável uma fotografia instantânea de pesos relevante se forem empregados em uma execução de treinamento em larga escala (consulte a Equação 1).
Embora o Provador possa alegar ter usado firmware que registrou fotografias instantâneas conforme descrito acima, o Verificador pode não confiar que o Provador realmente tenha usado o firmware de registro apropriado. Por esse motivo, os chips de AM também precisam de mecanismos de hardware para impor que o firmware seja assinado e, por sua vez, os fabricantes de chips precisarão assinar o firmware apenas se ele implementar mecanismos de registro apropriados10,11,12.
Um obstáculo para registrar todos os fragmentos de pesos armazenados na memória do dispositivo de AM é que diferentes códigos de treinamento de AM armazenarão os pesos de um modelo em diferentes regiões de memória. O firmware do chip deve ser capaz de determinar em qual região de memória os pesos estão armazenados. Talvez seja possível determinar as regiões dos pesos retroativamente, registrando as regiões de memória que, alega-se, correspondem aos pesos, juntamente com uma cópia do código compilado no dispositivo, que pode ser combinado com o código-fonte fornecido pelo Provador e seu padrão de alocação de memória analisado13,14. Como uma alternativa mais invasiva, o Provador poderia certificar proativamente que seu código de treinamento de AM em nível de chip armazena os pesos em uma região de memória específica, verificando seu código de chip e assinando-o por um servidor da confiança do Verificador antes de poder ser executado pelo firmware15.
Um problema mais desafiador é que os “chips de AM” são aceleradores de hardware de uso geral e, portanto, são frequentemente usados para outras cargas de trabalho de computação de alto desempenho, como modelagem climática. Não há uma maneira direta de determinar se um chip de AM está executando um trabalho de treinamento de rede neural (e, portanto, deve registrar fotografias instantâneas de pesos) ou um tipo de trabalho não relacionado isento da supervisão do Verificador16. Da mesma forma, também seria desejável poder isentar uma fração dos chips do monitoramento, para uso em educação ou Pesquisa e Desenvolvimento de pequena escala, onde as despesas gerais de conformidade seriam proibitivas17. Até encontrarmos métodos para distinguir de forma confiável o treinamento de AM em larga escala, alguma fração de chips de AM deve ser isenta de usar o firmware de registro de pesos. A garantia do sistema maior seria então que, para os chips do Provador que o Provador permite que o Verificador monitore, não ocorreu nenhum treinamento em violação das regras. O Verificador pode então usar sua influência para incentivar os Provadores a aceitar uma fração cada vez maior de seus chips ao longo do tempo.
5. Na central de dados
Nas Seções 3.2 e 4, vimos como um Verificador pode obter acesso a pelo menos um fragmento de pesos ω fotografado durante uma execução de treinamento em larga escala. Nesta seção, mostraremos como o Verificador pode usar esse fragmento de pesos para determinar se a execução de treinamento associada seguiu as regras acordadas.
Por si só, saber ω é inútil para o Verificador, uma vez que o Verificador não sabe os valores dos outros fragmentos de pesos que compõem a rede neural, ou mesmo quantos outros fragmentos de pesos existem. No entanto, ω contém a chave para a história da execução de treinamento. É incrivelmente improvável que qualquer determinado vetor de fragmento de pesos seja gerado pelo processo de treinamento (há ≫ 2 ^ 10 ^ 6 possibilidades, mesmo se arredondarmos à precisão de 1 bit). Mas esse ω em particular é o resultado quase determinístico dos hiperparâmetros da execução de treinamento M (incluindo sua semente aleatória) e a sequência de dados de treinamento D. Referimo-nos a essas informações, juntamente com as informações produzidas ao longo da execução de treinamento W (como fotografias instantâneas de pesos intermediários), como a transcrição de treinamento do modelo T = {M, D, W}. É plausível que seria muito difícil para o Provador encontrar uma segunda transcrição de treinamento “legítima” T′ = {M′, D′, W′} ̸= T que produziria exatamente um conjunto completo de pesos que incluísse ω como um fragmento de pesos contíguo. Também é plausível que, se o Provador tentasse mentir e fornecer um H’, D’ e M’ que não resultaria em ω, mas que ele afirmasse que resultaria em ω, o Verificador poderia encontrar um conjunto de testes que poderia detectar tal transcrição falsificada de forma confiável. Se o Verificador pudesse detectar essas falsificações de forma confiável, então, ao pedir ao Provador para fornecer uma transcrição de treinamento que produziria cada fotografia instantânea registrada ω, o Verificador poderia forçar o Provador a revelar os dados D e os hiperparâmetros M verdadeiros usados em todas as execuções de treinamento em larga escala (junto com os pesos completos do modelo resultante, não apenas ω). Isso seria informação suficiente para verificar se a execução de treinamento atendeu a qualquer um dos tipos de regra de treinamento listados na Seção 2.1.
Infelizmente, fazer com que o Verificador simplesmente execute novamente o processo de treinamento completo para verificar a exatidão de uma transcrição é impraticável por vários motivos. Primeiro, o Provador provavelmente não estaria disposto a revelar seus dados de treinamento, pesos de modelo e hiperparâmetros, de modo que o Verificador deve fazer qualquer verificação sem acesso direto aos dados. (Abordamos isso na Seção 5.2.) Em segundo lugar, o custo de computação para reexecutar totalmente a transcrição de treinamento seria enorme, tão grande quanto cada execução de treinamento original. Em terceiro lugar, a execução do treinamento provavelmente não seria perfeitamente reproduzível: devido ao ruído no nível do hardware, mesmo duas repetições da mesma sequência de atualizações de treinamento divergiriam gradualmente. Em quarto lugar, o Provador pode ser capaz de construir uma segunda transcrição de treinamento “falsificada”, que produz uma correspondência exata para ω, mas difere da execução de treinamento original que produziu ω em primeiro lugar18.
Felizmente, uma variante próxima desse problema já foi estudada na literatura, conhecida como “Prova de Aprendizado” [24]. O objetivo de um esquema de Prova de Aprendizado (PdA) é estabelecer prova de propriedade sobre um modelo Wt (p. ex., corroborar reivindicações de propriedade intelectual) fazendo com que o treinador do modelo salve a transcrição de treinamento T (incluindo hiperparâmetros M, sequência de dados D e uma série de pontos de verificação de pesos intermediários do modelo completo 19 W={W0,Wk,W2k…}) que somente o treinador do modelo original saberia. Jia et al. [24] propõem um procedimento de verificação que torna difícil para qualquer terceiro construir uma transcrição falsificada T’, se ele tiver acesso apenas a Wt e ao conjunto de dados não ordenado.
A solução de [24] é a seguinte: uma vez que um Provador relata uma transcrição de treinamento T, o Verificador verifica se a inicialização parece aleatória e, em seguida, escolhe uma série de pares de fotografias instantâneas de pesos adjacentes que estão separadas por k passos de gradiente (Wi, Wi+ k), . . . ,(Wj, Wj+k). Então, em vez de executar novamente todo o treinamento, o Verificador apenas executa novamente o treinamento desses segmentos específicos, começando em Wi e progredindo através dos lotes de dados apropriados Di. . . Di+k para produzir um W′i+k. O Verificador então confirma que o ponto de inspeção resultante está aproximadamente correto: ∥Wi+k − W′ i+k∥2 < ϵ para algum pequeno ε que depende do ruído de reprodução e do número de passos k. O artigo original propôs uma heurística para escolher quais segmentos verificar, embora artigos subsequentes tenham demonstrado ataques de falsificação que evitam a abordagem de verificação original [70, 15]. Até agora, a literatura sobre PdA tem sido baseada em heurísticas, e descobrir protocolos PdA com graus mais altos de confiabilidade é o assunto de trabalhos em andamento [15].
5.1 Transcrição de prova de treinamento
Nosso requisito, que definiremos como “Transcrição de Prova de Treinamento” (TdPdT), difere da Prova de Aprendizado porque nosso Provador conhece uma transcrição de treinamento verdadeira que leva à fotografia instantânea de pesos final (já que ele executou a execução de treinamento original), e o Verificador deseja verificar se o Provador relatou a transcrição original que gerou ω (ou pelo menos uma muito próxima da original). Além disso, ao contrário da PdA, aceitamos que um Provador adversário pode estar disposto a gastar mais do que o poder computacional do treinamento original H para construir uma falsificação (p. ex., um adversário pode estar disposto a pagar o dobro do custo para uma execução de treinamento em violação das regras sem ser detectado). Assim, devemos esperar aumentar o custo de construir uma falsificação o máximo possível, de modo a tornar a evasão impraticável.
Definição 1. Um protocolo de TdPdT (R, V) é definido por um protocolo de treinamento e relatório do Provador R e um protocolo de verificação do Verificador V . Um vetor de pesos-alvo Wt é produzido como o resultado real de uma execução de treinamento que obedece a um protocolo de treinamento e relatório R, e que pode ser resumido por meio de uma transcrição de treinamento T ∈ T , onde T = {M, D, W}, M são os metadados necessários para reproduzir a execução de treinamento (incluindo hiperparâmetros, semente aleatória e função de perda), D é uma sequência ordenada de conjuntos de lotes de dados de treinamento e W é uma coleção de pontos de verificação de pesos intermediários resultantes do procedimento de treinamento. O protocolo de verificação V deve aceitar qualquer transcrição de treinamento verdadeira com alta probabilidade, Pr[V (T, Wt) = aceitar] > 1 − δ1 para algum pequeno δ1.
Uma transcrição de treinamento “falsificada” T′ = {M′, D′, W′} é uma transcrição que pode não corresponder a nenhuma execução de treinamento válida e que é substancialmente diferente da transcrição original T em seus dados ou hiperparâmetros: d1 (D, D′ ) ≥ δ3 para alguma distância de edição d1 quantificando o número de inserções/exclusões de pontos de dados e/ou d2(M, M′ ) ≥ δ4 para alguma distância de hiperparâmetro d2. Um par de protocolo de relatório/verificação (R, V ) é J-eficiente e F-difícil se V é executado no máximo no tempo J e não existe nenhum algoritmo de geração de falsificação A ∈ A : T → T tal que Pr[V (A(T), Wt) = aceitar] > 1 − δ2 onde A é executado num tempo menor que F.
Coloquialmente, queremos um protocolo de treinamento e relatório do Provador e um protocolo de verificação do Verificador, de modo que o Verificador aceite apenas transcrições de treinamento originais que resultariam em um ponto de verificação de pesos final que contém um fragmento correspondente à nossa fotografia instantânea de fragmento de pesos no chip ω. Deixamos o problema de encontrar métodos comprovadamente seguros e eficientes para TdPdT como um caminho importante para trabalhos futuros, mas discutimos algumas direções promissoras abaixo.
A TdPdT parece ser estritamente mais difícil do que a PdA, pois requer resistência a um adversário com mais recursos que tem informações adicionais (ou seja, ele conhece a transcrição T verdadeira) e tem mais tempo de computação para construir uma falsificação. Dado que os esquemas de PdA existentes ainda são baseados em heurística e ainda não são comprovadamente seguros, pode haver um longo caminho a percorrer até que tenhamos métodos de TdPdT que sejam eficientes e difíceis de falsificar. Ainda assim, uma dinâmica que favorece o Verificador é que o Provador deva se comprometer com uma transcrição de treinamento sem conhecer as estratégias de verificação do Verificador. Assim, os Verificadores podem acumular coleções secretas de heurísticas de verificação, muito como a AIEA não divulga todos os seus métodos para detectar atividade nuclear. Mesmo que as TdPdTs sejam apenas baseadas em heurísticas, a presença dessa dinâmica pode dissuadir os Provadores de correr o risco de serem detectados por um teste inesperado.
Definir condições sobre os tipos de execução de treinamento legítimos é outra fonte útil de vantagem. Por exemplo, uma estratégia de trapaça do Provador poderia ser o Provador relatar uma execução de treinamento longa como várias execuções de treinamento mais curtas, afirmando que cada qual foi “inicializada” onde a execução de treinamento anterior terminou. Uma prevenção simples seria o protocolo R de treinamento e relatório exigir que o Provador inicialize os pesos de cada execução de treinamento por meio de um gerador pseudoaleatório conhecido e uma semente curta. Isso significa que a aleatoriedade dos pesos iniciais pode ser posteriormente confirmada pelo Verificador.
Outra estratégia promissora pode ser exigir que o Provador se comprometa previamente com partes de sua transcrição de treinamento (p. ex., os hiperparâmetros M e os lotes de treinamento D) no início do treinamento. Isso poderia ser realizado fazendo com que o firmware do chip de AM registrasse um hash desse pré-comprometimento, o que provaria que o pré-comprometimento precedeu a fotografia instantânea ω do chip. No momento do pré-compromisso, o Provador não sabe qual trajetória a execução de treinamento seguirá ou em que momento será capturada, pois o treinamento ainda não foi realizado. O Provador seria incapaz de construir uma transcrição de treinamento falsificada que terminaria em ω e se comprometer com ela, porque ω ainda não é conhecido. No entanto, não é óbvio como estender essa abordagem a configurações de aprendizado on-line como aprendizado por reforço on-line, onde os dados de treinamento não podem ser conhecidos antecipadamente.
Uma complicação final de nossa configuração deriva do fato de que o Verificador observa apenas um fragmento dos pesos ω e não o vetor de pesos completo Wt. Poderia ser mais fácil construir uma transcrição de treinamento falsificada para algum Wˆ que contém um fragmento correspondente a ω, mas que difere dos pesos originais verdadeiros Wt ̸= Wˆ na parte do vetor de pesos fora do fragmento. Descrevemos brevemente uma intuição de por que isso provavelmente é tão difícil quanto a falsificação geral da TdPdT. Presumindo que ω deva conter pesos de mais de uma única camada linear, qualquer Provador deve, no mínimo, construir uma TdPdT válida para esta rede neural menor representada por ω, exceto que sem nenhuma transcrição de treinamento original com que começar (tornando isso tão difícil quanto o problema original da Prova de Aprendizado). Alternativamente, se o Provador tentar reutilizar a transcrição de treinamento original, isso exigirá que ele sintetize dados e rótulos falsos para reproduzir exatamente as entradas/gradientes verdadeiros, e eles devem corresponder a uma função de perda razoável que esteja efetivamente diminuindo ao longo do tempo. Se o Provador tentar alternativamente falsificar os pesos das camadas circundantes, então os pesos nessas camadas circundantes também devem ter suas próprias trajetórias de treinamento válidas como parte da transcrição de treinamento e devem gerar as entradas/gradientes apropriados para produzir ω, simultaneamente.
5.2. Implementação no mundo real
À medida que a literatura revela novos métodos para verificar as transcrições de treinamento, o Verificador pode executar esses protocolos para verificar se, para cada uma das fotografias instantâneas de pesos registradas nos chips do Provador que o Verificador inspeciona, o Provador forneceu uma transcrição de treinamento correspondente legítima20. O Verificador pode então examinar os dados, hiperparâmetros e modelos resultantes, conforme foi relatado pela transcrição de treinamento e, assim, detectar se o Provador cumpriu as regras de treinamento.
Uma importante restrição do projeto é que o Provador não divulga as transcrições brutas (que provavelmente contêm dados confidenciais que o Provador preferiria que o Verificador não visse). Propomos um método para o Verificador verificar a exatidão da transcrição relatada anteriormente pelo Provador sem nunca observar os dados brutos. Primeiro, o Provador e o Verificador utilizam um “grupo de confiança”: um conjunto de chips em que ambas as partes confiam, que é isolado para evitar que os dados confidenciais do Provador vazem e que é equipado para executar pequenas quantidades de inferência e treinamento de AM (de modo a reproduzir aproximadamente o processo de treinamento original do Provador)21. Em segundo lugar, em vez de relatar a transcrição completa, o Provador inicialmente apenas fornece ao Verificador hashes da transcrição de treinamento T. Em seguida, em um estágio de verificação posterior, o Provador fornece o verdadeiro M, D e W dentro do grupo de confiança (que deve corresponder aos hashes relatados), executa o protocolo de verificação e relata se ambas as etapas foram bem-sucedidas. Por fim, o Verificador pode usar esse mesmo grupo de confiança para executar programas que verifiquem se a transcrição de treinamento do Provador está em conformidade com todas as regras de treinamento de AM acordadas (p. ex., medindo o desempenho dos pesos do modelo final com base em referenciais acordados). Fornecemos mais detalhes sobre um possível procedimento no Apêndice D.
Ao avaliar quais protocolos de verificação de transcrição de treinamento seguir, os Verificadores devem priorizar as estratégias de verificação que obtêm a maior probabilidade de detecção, pelo menor custo. Além dos custos iniciais de construir grupos de confiança ou modificar o hardware do chip, o sistema tem três custos operacionais contínuos: a perda de eficiência decorrente da pausa para salvar os pontos de verificação de pesos e as fotografias instantâneas de fragmentos de pesos (conforme descrito na Seção 4), os custos de armazenamento para guardar as transcrições de treinamento (e em particular os pontos de verificação de pesos, cada um dos quais pode exigir terabytes) até que o Verificador os inspecione e os custos de computação para executar os protocolos de verificação de transcrições de treinamento nos grupos de confiança. Esses custos parecem aumentar linearmente com o poder computacional total usado pelo Provador e, em última análise, dependerão da eficiência com a qual as transcrições de treinamento podem ser verificadas. Mesmo que os governos possam, em princípio, pressionar os Provadores a pagar os custos de conformidade, uma despesa geral de 1% para cada dólar gasto em computação de treinamento seria muito mais fácil para os Provadores cumprirem do que uma despesa geral de 20%. De fato, para os Verificadores internacionais, a história do controle de armas sugere que medidas de verificação extremamente rigorosas podem ter utilidade limitada, pois podem reduzir a probabilidade de conformidade [46]. Um caminho importante para trabalhos futuros é encontrar alternativas mais baratas e de menor fidelidade para a verificação baseada em retreinamento de redes neurais, que precisem apenas estabelecer propriedades limitadas da execução de treinamento correspondente do fragmento de pesos e que possam solicitar métodos de verificação mais caros, se necessário.
6 Na cadeia de suprimentos
Precisamos do monitoramento da cadeia de suprimentos para atingir dois objetivos: construir um “diretório de chips” de quem possui cada chip de AM, para fins de amostragem; e para garantir que cada chip tenha os recursos de hardware necessários para registrar comprovadamente sua atividade de treinamento como na Seção 4. Ao contrário das intervenções em chips e centrais de dados (Seções 4 e 5), o monitoramento da cadeia internacional de suprimentos de chips de AM não pode ser feito por um único Verificador. Em vez disso, um consórcio internacional de governos pode precisar implementar essas intervenções em nome de outros Verificadores (da mesma forma que a AIEA realiza inspeções em nome dos Estados-membros).
6.1 Criando um diretório proprietário de chips
Para que um Verificador tenha certeza de que um Provador está relatando a atividade de todos os chips de AM do Provador, ele precisa saber quais chips de AM o Provador possui e que não há estoques secretos de chips além do conhecimento do Verificador. Esse monitoramento de propriedade representaria uma extensão natural das práticas existentes de gerenciamento da cadeia de suprimentos, como aquelas usadas para impor controles de exportação dos EUA a chips de AM. Pode ser relativamente simples determinar com segurança o número total de chips de AM de ponta produzidos em todo o mundo, monitorando as linhas de produção em instalações de fabricação de chips de ponta. A moderna cadeia de suprimentos de fabricação de chips de ponta é extremamente concentrada e, a partir de 2023, existem menos de duas dúzias de instalações em todo o mundo capazes de produzir chips com tamanho de nó de 14 nm ou menos [32], o tamanho usado para chips de treinamento de AM eficientes. Como [4] mostra, o processo de produção de chips de ponta pode ser monitorado usando uma abordagem semelhante à supervisão da produção de combustível nuclear (p. ex., monitoramento contínuo por vídeo de máquinas cruciais).
Desde que uma nova fábrica de cada país possa ser detectada por outros países (p. ex., monitorando a cadeia de suprimentos de equipamentos de litografia), um consórcio internacional de monitoramento pode exigir a implementação de medidas de verificação em cada fábrica, para fornecer garantias a todos os Verificadores. Após o processamento, cada wafer produzido em uma fábrica é enviado para corte em cubos e embalagem. Como as instalações necessárias para o pós-processamento de wafers são menos concentradas, é importante que os wafers (e posteriormente os dies) sejam transportados de forma segura e verificável em cada etapa. Se esses precursores de chips desaparecerem, a responsabilidade pela violação recairá sobre o detentor mais recente. Essa cadeia de custódia continua até que o chip chegue ao seu proprietário final, momento em que o ID exclusivo do chip é associado a esse proprietário em um diretório de proprietários de chips confiável para todos os Verificadores e Provadores em potencial. Esse diretório de propriedade deve ser mantido atualizado, por exemplo, quando os chips são revendidos ou danificados22. A precisão contínua desse registro pode ser validada como parte do mesmo procedimento de amostragem aleatória discutido na Seção 3.1. Como uma segunda camada de garantia, os chips também podem ser descobertos pela inspeção de centrais de dados, se essas centrais de dados forem detectáveis por meio de outros sinais [4].
Dados os altos preços e os grandes requisitos de energia e refrigeração desses chips de AM, eles são adquiridos em grande parte por operadores de centrais de dados. Essas organizações são adequadas para rastrear e relatar transferências de seus chips de AM e cumprir inspeções ocasionais. Embora uma pequena fração das compras de chips de AM de centrais de dados seja feita por indivíduos, desde que sejam uma pequena fração de chips, eles podem ser isentos da estrutura geral de monitoramento.
6.2 Confiando em hardware seguro
Exigimos na Seção 4 que cada chip de AM produzido pela cadeia de suprimentos de semicondutores seja capaz de registrar vestígios de seu uso. O segundo objetivo do monitoramento da cadeia de suprimentos é fornecer aos Verificadores alta confiança na confiabilidade desses mecanismos de registro de atividade no chip. Isso exige que os projetistas de chips de AM integrem recursos de segurança em seus projetos de hardware e firmware, especialmente de maneira a torná-los legíveis externamente para Verificadores que podem não confiar no projetista do chip. As principais prioridades incluem a imutabilidade do ID gravado no chip, a integridade do mecanismo de hardware para inicializar apenas o firmware assinado e a resiliência das raízes de confiança do hardware no chip a ataques de canal lateral que podem roubar as chaves de criptografia do chip [27, 9] e assim falsificar seus registros.
Uma preocupação de Verificadores que verificam a conduta de Provadores poderosos (p. ex., Estados que verificam as execuções de treinamento de AM uns dos outros) é a possibilidade de ataques à cadeia de suprimentos [48], que podem permitir que um Provador desative/falsifique indetectavelmente a funcionalidade de registro dos chips de AM. Mitigar totalmente a ameaça de ataques à cadeia de suprimentos é uma questão global importante e está além do escopo deste documento. No entanto, uma etapa particularmente útil para criar confiança na integridade dos mecanismos de chip de AM seria que os projetistas de chips de AM usassem Raízes de Confiança de Hardware de código aberto. Essa transparência significa que os projetos dos chips podem ser validados por Verificadores desconfiados para confirmar que não há backdoors. Por exemplo, o Projeto OpenTitan da Google produziu tal Raiz de Confiança de Hardware [31], e muitos dos principais projetistas de chips de AM (Google, Microsoft, NVIDIA e AMD) concordaram em integrar a Raiz de Confiança “Caliptra” do Open Compute Project. [45]
7. Discussão
As adições descritas à produção e operação de chips de treinamento de AM, se implementadas com sucesso, permitiriam que partes sem confiança mútua (como um governo e suas empresas domésticas, ou os governos dos EUA e da China) verificassem as regras e os compromissos no desenvolvimento avançado de AM usando esses chips. Existem muitas medidas úteis que governos e empresas poderiam começar a tomar hoje para permitir a implementação futura de tal estrutura, caso se provasse necessária, e que simultaneamente promoveriam outros objetivos de empresas e reguladores.
- Os fabricantes de chips podem incluir recursos aprimorados de segurança de hardware em seus chips de AM de central de dados, pois muitos deles já são práticas recomendadas de segurança de hardware (e podem já estar presentes em alguns chips de AM [42]). Esses recursos provavelmente serão procurados de forma independente conforme os custos do treinamento de modelos aumentarem e o risco de roubo de modelos se tornar uma consideração importante para empresas ou governos que estão debatendo se devem treinar um modelo caro que pode simplesmente ser roubado.
- Da mesma forma, muitas das medidas de segurança necessárias para este sistema (certificação de código e firmware, módulos de encriptação/desencriptação, verificação de modelos produzidos sem divulgar o código de treinamento) também seriam úteis para “provedores de treinamento de AM em nuvem”, que desejam provar a clientes preocupados com a segurança que os dados dos clientes não foram retirados dos chips e que backdoors não foram inseridas por terceiros nos modelos dos clientes [34]. Programas de aquisição como o FedRAMP dos EUA poderiam encorajar tais padrões para contratos governamentais e, assim, incentivar provedores de nuvem e fabricantes de chips a construir uma infraestrutura técnica que poderia ser posteriormente reaproveitada para supervisão.
- Empresas e governos individuais podem se comprometer publicamente com as regras de desenvolvimento de AM que gostariam de cumprir, desde que pudessem ter certeza de que seus concorrentes seguiriam o exemplo.
- Empresas responsáveis podem registrar e divulgar publicamente transcrições de treinamento (com hash) para suas grandes execuções de treinamento e ajudar outras empresas a verificar essas transcrições usando heurística simples. Isso não provaria que as empresas não haviam também treinado modelos não divulgados, mas o processo provaria a viabilidade técnica e criaria impulso em torno de um padrão do setor para divulgação (segura) de execuções de treinamentos.
- Empresas e governos podem construir grupos neutros confiáveis do tipo descrito na Seção 5.2. Isso seria útil para muitas outras prioridades regulatórias, como permitir que auditores-terceiros analisem os modelos das empresas sem deixar vazar os pesos do modelo23.
- Os governos podem melhorar o rastreamento dos fluxos de chips de AM por meio do monitoramento da cadeia de suprimentos, para identificar usuários finais que possuem quantidades significativas de chips de AM. No Ocidente, é provável que essa supervisão da cadeia de suprimentos seja uma medida necessária para impor os controles de exportações dos aliados dos EUA.
- Empresas responsáveis podem trabalhar com organizações sem fins lucrativos e órgãos governamentais para praticar a inspeção física de chips de AM em centrais de dados. Isso pode ajudar as partes interessadas a criar práticas recomendadas para inspeções e ganhar experiência em implementá-las, ao mesmo tempo que melhora as estimativas dos custos de implementação.
- Os pesquisadores podem investigar métodos mais eficientes e resilientes para detectar transcrições de treinamentos falsificadas, o que pode ser útil para provar que nenhuma backdoor foi inserida nos modelos de AM.
Para as intervenções de hardware, quanto mais cedo essas medidas forem implementadas, mais chips de AM poderão ser aplicados e mais útil será qualquer estrutura de verificação. Iniciar essas medidas com antecedência também permitirá que mais ciclos capturem quaisquer vulnerabilidades de segurança no software e no hardware, que geralmente exigem várias iterações para acertar.
7.1 A política de implementação
Dada a complexidade e o custo substanciais de um regime de monitoramento e verificação para execuções de treinamento de AM em larga escala, isso só se tornará realidade se beneficiar as principais partes interessadas necessárias para implementá-lo. Nesta última seção, discutimos os benefícios desta proposta entre cada uma das partes interessadas necessárias.
- O público global: cidadãos comuns devem se preocupar com a concentração de poder associada a empresas privadas que possuem grandes quantidades de chips de AM, sem nenhuma supervisão significativa do público. O monitoramento de execuções de treinamento é uma maneira de fazer o desenvolvimento de AM avançado de empresas poderosas prestar contas ao público, não apenas ao livre mercado. Mais importante ainda, as pessoas comuns se beneficiam da segurança e estabilidade viabilizadas por leis e acordos que limitam as aplicações mais prejudiciais de sistemas de AM em larga escala.
- Fabricantes de chips e provedores de nuvem: na ausência de mecanismos para verificar se os chips de AM são usados para execuções de treinamento em violação das regras, os governos podem recorrer cada vez mais à proibição da venda de chips (ou mesmo do acesso de computação em nuvem a esses chips) para atores não confiáveis [5]. Ao permitir o monitoramento comprovado de execuções de treinamento de AM em grande escala, os fabricantes de chips podem reverter essa tendência e até mesmo retomar as vendas nos mercados afetados.
- Empresas de IA: as próprias empresas de IA responsáveis podem preferir não desenvolver uma capacidade específica em seus produtos, mas podem sentir que não têm escolha devido à pressão competitiva exercida por rivais menos escrupulosos. A verificação das execuções de treinamento permitiria que as empresas de IA responsáveis fossem reconhecidas pelos limites que impõem a si mesmas e facilitaria a aplicação das práticas recomentadas em todo o setor no desenvolvimento responsável de AM.
- Governos e forças armadas: o principal objetivo dos governos e forças armadas é garantir a segurança e a prosperidade de seu país. A incapacidade de coordenar com os rivais os limites para o desenvolvimento de sistemas de AM altamente capazes é uma ameaça à sua própria segurança nacional. Haveria um benefício enorme para um sistema que permitisse a (mesmo um subconjunto de) países verificar a adesão uns dos outros aos acordos de treinamento de AM e, assim, manter um equilíbrio de desenvolvimento responsável de AM.
Mesmo que apenas um subconjunto de empresas e governos responsáveis cumpram a estrutura, eles ainda se beneficiam ao demonstrar de forma verificável sua conformidade com as regras autoimpostas, aumentando a confiança de seus rivais e aliados em seu comportamento [22] (e, assim, reduzindo em seus rivais a incerteza e o incentivo à imprudência).
Finalmente, destacamos que a estrutura de verificação discutida requer participação e consentimento contínuos do Provador. Isso torna a estrutura fundamentalmente não coercitiva e respeita a soberania nacional tanto quanto a não proliferação nuclear e os acordos de controle de armamentos respeitam a soberania nacional. De fato, o sucesso contínuo de tal sistema depende do interesse próprio de todas as partes em continuar a viver em um mundo onde ninguém – nem eles, nem seus rivais – violam as proteções acordadas no desenvolvimento avançado de AM.
Agradecimentos
O autor gostaria de agradecer a Tim Fist, Miles Brundage, William Moses, Gabriel Kaptchuk, Cynthia Dwork, Lennart Heim, Shahar Avin, Mauricio Baker, Jacob Austin, Lucy Lim, Andy Jones, Cullen O’Keefe, Helen Toner, Julian Hazell, Richard Ngo, Jade Leung, Jess Whittlestone, Ariel Procaccia, Jordan Schneider e Rachel Cummings Shavit por seus valiosos comentários e conselhos na escrita deste trabalho.
Referências
[1] Mohd Shahdi Ahmad, Nur Emyra Musa, Rathidevi Nadarajah, Rosilah Hassan, and Nor Effendy Othman. 2013. Comparison Between Android and iOS Operating System in Terms of Security. In 2013 8th International Conference on Information Technology in Asia (CITA). IEEE, 1–4.
[2] Yonatan Aumann and Yehuda Lindell. 2007. Security Against Covert Adversaries: Efficient Protocols for Realistic Adversaries. In Theory of Cryptography: 4th Theory of Cryptography Conference, TCC 2007, Amsterdam, The Netherlands, February 21-24, 2007. Proceedings 4. Springer, 137–156.
[3] Yuntao Bai et al. 2022. Training a Helpful and Harmless Assistant with Reinforcement Learning From Human Feedback. arXiv preprint arXiv:2204.05862.
[4] Mauricio Baker. Forthcoming. Nuclear Arms Control Verification and Lessons for AI Treaties. (Forthcoming).
[5] 2022. BIS Press Release: Advanced Computing and Semiconductor Manufacturing Controls. (2022). https://www.bis.doc.gov/index.php/documents/about-bis/newsroom/press-releases/3158-2022-10-07-bis-press-release-advanced-computing-and-semiconductor-manufacturing-controls-final/file; .
[6] Tom Brown et al. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems. H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, (Eds.) Vol. 33. Curran Associates, Inc., 1877–1901. https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
[7] Miles Brundage et al. 2018. The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation. (2018). DOI: 10.48550/ARXIV.1802.07228.
[8] US Census Bureau. 2022. Federal Statistical Research Data Centers. (2022). https://www.census.gov/about/adrm/fsrdc.html.
[9] Piljoo Choi and Dong Kyue Kim. 2012. Design of security enhanced TPM chip against invasive physical attacks. In 2012 IEEE International Symposium on Circuits and Systems (ISCAS), 1787–1790. DOI: 10.1109/ISCAS.2012.6271612.
[10] Aakanksha Chowdhery et al. 2022. PaLM: Scaling Language Modeling with Pathways. (2022). DOI: 10.48550/ARXIV.2204.02311.
[11] Keith Chu. 2022. Wyden, Booker and Clarke Introduce Algorithmic Accountability Act of 2022 to require new transparency and accountability for automated decision systems. (2022). https://www.wyden.senate.gov/news/press-releases/wyden-booker-and-clarke-introduce-algorithmic-accountability-act-of-2022-to-require-new-transparency-and-accountability-for-automated-decision-systems.
[12] Bonnie Docherty. 2020. New Weapons, Proven Precedent: Elements of and Models for a Treaty on Killer Robots. (2020). https://www.hrw.org/report/2020/10/20/new-weapons-proven-precedent/elements-and-models-treaty-killer-robots.
[13] Olivia J Erdélyi and Judy Goldsmith. 2018. Regulating Artificial Intelligence: Proposal for a Global Solution. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 95–101.
[14] Ege Erdil and Tamay Besiroglu. 2022. Algorithmic progress in computer vision. (2022). DOI: 10.48550/ARXIV.2212.05153.
[15] Congyu Fang, Hengrui Jia, Anvith Thudi, Mohammad Yaghini, Christopher A Choquette-Choo, Natalie Dullerud, Varun Chandrasekaran, and Nicolas Papernot. 2022. On the Fundamental Limits of Formally (Dis) Proving Robustness in Proof-ofLearning. arXiv preprint arXiv:2208.03567.
[16] Deep Ganguli et al. 2022. Predictability and Surprise in Large Generative Models. In 2022 ACM Conference on Fairness, Accountability, and Transparency, 1747–1764.
[17] Chaim Gartenberg. 2021. NVIDIA Has Reinstated its RTX 3060 Ethereum Cryptocurrency Mining Limit. (2021). https://www.theverge.com/2021/4/29/22409838/nvidia-rtx-3060-etherium-cryptocurrency-mining-limit-back-driver-update.
[18] Andy Greenberg. 2018. The Untold Story of NotPetya, the Most Devastating Cyberattack in History. (2018). https://www.wired.com/story/notpetya-cyberattack-ukraine-russia-code-crashed-the-world/.
[19] R JS Harry. 1996. IAEA Safeguards and Detection of Undeclared Nuclear Activities.
[20] Dan Hendrycks, Nicholas Carlini, John Schulman, and Jacob Steinhardt. 2021. Unsolved problems in ML safety. arXiv preprint arXiv:2109.13916.
[21] Jordan Hoffmann et al. 2022. Training Compute-Optimal Large Language Models. (2022). DOI: 10.48550/ARXIV.2203.15556.
[22] Michael C Horowitz. 2021. AI and International Stability: Risks and Confidence-Building Measures.
[23] Tim Hwang. 2018. Computational Power and the Social Impact of Artificial Intelligence. arXiv preprint arXiv:1803.08971.
[24] Hengrui Jia, Mohammad Yaghini, Christopher A Choquette-Choo, Natalie Dullerud, Anvith Thudi, Varun Chandrasekaran, and Nicolas Papernot. 2021. Proof-of-Learning: Definitions and Practice. In 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 1039–1056.
[25] Jared Kaplan et al. 2020. Scaling Laws for Neural Language Models. (2020). DOI: 10.48550/ARXIV.2001.08361.
[26] Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. Yoshua Bengio and Yann LeCun, (Eds.) http://arxiv.org/abs/1412.6980.
[27] Paul C. Kocher. 1996. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems. In Advances in Cryptology -CRYPTO ’96, 16th Annual International Cryptology Conference, Santa Barbara, California, USA, August 18-22, 1996, Proceedings (Lecture Notes in Computer Science). Vol. 1109. Springer, 104–113. DOI: 10.1007/3-540-68697-5_9.
[28] Srilehka Krishnamurthy, Jeremy O’Donoghue, and Neeraj Bhatia. 2012. US20140130151A1 – Methods for Providing AntiRollback Protection of a Firmware Version in a Device Which Has No Internal Non-Volatile Memory. (2012). https://patents.google.com/patent/US20140130151A1/en.
[29] Frederic Lardinois. 2022. Google Launches a 9 Exaflop Cluster of Cloud TPU V4 Pods Into Public Preview. (2022). https://techcrunch.com/2022/05/11/google-launches-a-9-exaflop-cluster-of-cloud-tpu-v4-pods-into-public-preview/.
[30] Seunghwa Lee, Hankyung Ko, Jihye Kim, and Hyunok Oh. 2020. VCNN: Verifiable convolutional neural network based on ZK-Snarks. Cryptology ePrint Archive.
[31] [n. d.] Lightweight threat model: OpenTitan documentation. (). https://docs.opentitan.org/doc/security/threat_model/.
[32] 2023. List of Semiconductor Fabrication Plants. (2023). https://en.wikipedia.org/wiki/List_of_semiconductor_fabrication_plants.
[33] Chao Liu, Cuiyun Gao, Xin Xia, David Lo, John Grundy, and Xiaohu Yang. 2021. On the Reproducibility and Replicability of Deep Learning in Software Engineering. ACM Transactions on Software Engineering and Methodology (TOSEM), 31, 1, 1–46.
[34] Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. 2017. Trojaning Attack on Neural Networks.
[35] Ali Madani et al. 2023. Large Language Models Generate Functional Protein Sequences Across Diverse Families. Nature Biotechnology, 1–8.
[36] Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. 2022. Teaching Small Language Models to Reason. (2022). DOI: 10.48550/ARXIV.2212.08410.
[37] Matt Mittelsteadt. 2021. AI Verification-Mechanisms to Ensure AI Arms Control Compliance.
[38] Sebastian Moss. 2023. NVIDIA Updates GeForce EULA to Prohibit Data Center Use. (2023). https://www.datacenterdynamics.com/en/news/nvidia-updates-geforce-eula-to-prohibit-data-center-use/.
[39] Patricia Musoke-Zawedde and Teodor Nicula-Golovei. 2022. A day in the life of a nuclear safeguards inspector. (2022). https://www.iaea.org/bulletin/a-day-in-the-life-of-a-nuclear-safeguards-inspector.
[40] 2023. Nuclear Power by Country. (2023). https://en.wikipedia.org/wiki/Nuclear_power_by_country.
[41] [n. d.] NVIDIA GeForce RTX 4090 graphics cards. (). https://www.nvidia.com/en-us/geforce/graphics-cards/40-series/rtx-4090/.
[42] [n. d.] Nvidia H100 Tensor Core GPU Architecture Overview. (). https://resources.nvidia.com/en-us-tensor-core.
[43] Cyberspace Administration of China. 2022. Translation of “Provisions on the Management of Algorithmic Recommendations in Internet Information Services”. (2022). https://www.chinalawtranslate.com/en/algorithms/.
[44] Thomas Pledger. 2021. The Role of Drones in Future Terrorist Attacks. Association of the United States army, 26.
[45] Open Compute Project. 2022. Caliptra RTM technical specification. (2022). https://www.opencompute.org/documents/caliptra-silicon-rot-services-09012022-pdf.
[46] Andrew W Reddie. 2019. Governing Insecurity: Institutional Design, Compliance, and Arms Control. University of California, Berkeley.
[47] Thomas Reinhold. 2022. Arms Control for Artificial Intelligence. In Armament, Arms Control and Artificial Intelligence: The Janus-faced Nature of Machine Learning in the Military Realm. Springer, 211–226.
[48] Jordan Robertson and Michael Riley. 2021. Supermicro Hack: How China exploited a U.S. Tech supplier over years. (2021). https://www.bloomberg.com/features/2021-supermicro/.
[49] Jonathan S. Rosenfeld. 2021. Scaling laws for deep learning. CoRR, abs/2108.07686. https://arxiv.org/abs/2108.07686 arXiv: 2108.07686.
[50] Max Ryabinin, Tim Dettmers, Michael Diskin, and Alexander Borzunov. 2023. SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient. (2023). DOI: 10.48550/ARXIV.2301.11913.
[51] Girish Sastry, Miles Brundage, Julian Hazell, and et al. Anderljung Markus. Forthcoming. Computing Power and the Governance of Artificial Intelligence.
[52] Paul Scharre and Megan Lamberth. 2022. Artificial Intelligence and Arms Control. arXiv preprint arXiv:2211.00065.
[53] Lisa M Schenck and Robert A Youmans. 2011. From Start to Finish: A Historical Review of Nuclear Arms Controls Treaties and Starting over with the New Start. Cardozo J. Int’l & Comp. L., 20, 399.
[54] Jaime Sevilla, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. 2022. Compute Trends Across Three Eras of Machine Learning. In 2022 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8.
[55] Ying Sheng et al. 2023. High-throughput Generative Inference of Large Language Models with a Single GPU. arXiv preprint arXiv:2303.06865.
[56] Sergei P Skorobogatov. 2005. Semi-invasive Attacks–A New Approach to Hardware Security Analysis. Tech. rep. University
of Cambridge, Computer Laboratory.
[57] Shaden Smith et al. 2022. Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. (2022). DOI: 10.48550/ARXIV.2201.11990.
[58] Irene Solaiman. 2023. The Gradient of Generative AI Release: Methods and Considerations. arXiv preprint arXiv:2302.04844.
[59] Richard Sutton. 2019. The Bitter Lesson. Incomplete Ideas (blog), 13, 1.
[60] Fabio Urbina, Filippa Lentzos, Cédric Invernizzi, and Sean Ekins. 2022. Dual Use of Artificial-Intelligence-Powered Drug Discovery. Nature Machine Intelligence, 4, 3, 189–191.
[61] Michael Veale and Frederik Zuiderveen Borgesius. 2021. Demystifying the Draft EU Artificial Intelligence Act—Analysing the good, the bad, and the unclear elements of the proposed approach. Computer Law Review International, 22, 4, 97–112.
[62] Pablo Villalobos. 2023. Scaling Laws Literature Review. https://epochai.org/blog/scaling-laws-literature-review. Accessed: 2023-02-03. (2023).
[63] Sameer Wagh, Divya Gupta, and Nishanth Chandran. 2018. SecureNN: Efficient and private neural network training. Cryptology ePrint Archive.
[64] Adam Waksman and Simha Sethumadhavan. 2010. Tamper Evident Microprocessors. In 2010 IEEE Symposium on Security and Privacy. IEEE, 173–188.
[65] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. (2022). DOI: 10.48550/ARXIV.2201.11903.
[66] Kyle Wiggers. 2022. Microsoft and NVIDIA Team Up to Build New Azure-Hosted AI Supercomputer. (2022). https://techcrunch.com/2022/11/16/microsoft-and-nvidia-team-up-to-build-new-azure-hosted-ai-supercomputer/.
[67] Binhang Yuan, Yongjun He, Jared Quincy Davis, Tianyi Zhang, Tri Dao, Beidi Chen, Percy Liang, Christopher Re, and Ce Zhang. 2022. Decentralized Training of Foundation Models in Heterogeneous Environments. (2022). DOI: 10.48550/ARXIV.2206.01288.
[68] Aohan Zeng et al. 2022. GLM-130B: An Open Bilingual Pre-trained Model. (2022). DOI: 10.48550/ARXIV.2210.02414.
[69] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. 2021. Scaling Vision Transformers. (2021). DOI:10.48550/ARXIV.2106.04560.
[70] Rui Zhang, Jian Liu, Yuan Ding, Zhibo Wang, Qingbiao Wu, and Kui Ren. 2022. “Adversarial Examples” for Proof-ofLearning. In 2022 IEEE Symposium on Security and Privacy (SP), 1408–1422. DOI: 10.1109/SP46214.2022.9833596.
Notas
1. Estima-se que o verme de computador NotPetya de 2017 tenha causado US$ 10 bilhões em danos, e era muito menos capaz e muito mais fácil de desativar [18].
2. Ao longo do texto, usamos “AM” para nos referir ao aprendizado de máquina baseado em aprendizado profundo, que tem sido responsável por grande parte do progresso dos últimos anos.
3. Podemos sempre manter o limite de detecção o mesmo cortando H pela metade. Além disso, a literatura sobre leis de amplificação neural [25, 49, 62] sugere que a perda do modelo diminui logaritmicamente, na melhor das hipóteses, devido a computação adicional; portanto, não detectar uma violação menor que 2x pode ter consequências limitadas.
4. Para simplificar, presumimos que T seja divisível por Tm.
5. Queremos estimar o número de inspetores necessários para capturar uma execução de treinamento do tamanho de Chinchilla-280B, com 1025 FLOPs, considerando vários anos de progresso de hardware e produção global. Dado C = 107 chips mundiais (> 5× estoques globais em 2022), cada um dos quais pode produzir a = 3 · 1015 · 86400 FLOPs por dia (3× mais FLOP/s que o NVIDIA H100), detectar uma execução de treinamento do tamanho de Chinchilla-280B dentro de T = 30 dias após sua conclusão em qualquer lugar da Terra com 90% de probabilidade exigiria aproximadamente 232.000 amostras de chips em todo o mundo por ano. Pode-se esperar que um único inspetor verifique pelo menos 1.000 chips por ano, especialmente se esses chips forem trazidos para uma localização central (consulte a Seção 3.1). Isso exigiria ≈ 232 inspetores, um pouco menos do que os 280 inspetores ativos da AIEA em 2021. [39]
6. Isso inclui componentes-padrão de um módulo de segurança de hardware: verificação e atestação de firmware, antirreversão de firmware proteção e a capacidade de assinar, autenticar e criptografar mensagens. Também inclui a capacidade do firmware de levantar as interrupções, ler a memória do dispositivo e (para capturar fotografias instantâneas de pesos com hash com eficiência) executar o código no processador do chip.
7. Esse hash pode ser feito de forma barata, desde que o firmware possa aproveitar o poder de processamento do chip de AM.
8. Manter o hash na NVRAM local é útil se o chip de AM estiver em uma central de dados segura e for impedido de se comunicar com o mundo externo, como via air-gapping.
9. Uma alternativa possível seria orquestrar fotografias instantâneas menos frequentes por meio de um servidor central da confiança do Verificador, embora isso exigisse uma solução para o problema de o Provador trocar os pesos do chip antes de propagar o sinal do Verificador.
10. Um mecanismo de firmware semelhante foi usado pela NVIDIA para impor limites de mineração de criptomoeda em suas GPUs [17].
11. Supondo que as versões sem registro tenham sido assinadas no passado, os chips de AM podem precisar incluir a funcionalidade antirollback [28]. O Provador também pode atrasar a atualização do firmware do chip até pouco antes da inspeção. Para evitar isso, os chips de AM podem precisar ser feitos para atestar remotamente em um momento anterior que seu firmware foi atualizado.
12. Desafios adicionais surgem se o Verificador suspeitar que o fabricante do chip (que é o autor do firmware) e o Provador conspiraram para criar firmware com backdoors que desativam o registro. Aumentar a confiança dos Verificadores no firmware pode ser uma consideração importante ao verificar as operações de poderosos Provadores de Estado-nação.
13. Pode até ser possível modificar bibliotecas-padrão para gerar código de treinamento de AM em nível de chip (por exemplo, CUDA gerado por PyTorch) para tornar seus processos de alocação de memória mais facilmente verificáveis por um Verificador subsequente.
14. Revelar o código-fonte do Provador diretamente ao Verificador pode ser inaceitável, exigindo um procedimento de verificação mais complicado como o descrito na Seção 5.2.
15. A iOS App Store usa um método semelhante para garantir que os dispositivos da Apple executem apenas programas assinados [1].
16. Os possíveis caminhos para resolver isso podem incluir exigir que os compiladores de código de treinamento de não AM também assinem seus resultados ou melhorar os métodos para distinguir entre o código de treinamento de AM e outro código. Se os tipos de código puderem ser distinguidos retroativamente, os chips de AM poderão ocasionalmente salvar fotografias instantâneas de memória/código e, em seguida, determinar retroativamente se eles pertencem a uma execução de treinamento em grande escala e, portanto, merecem um exame mais minucioso. Um caso particularmente simples de abordar é a inferência de AM: os pesos na memória do modelo podem ser capturados e verificados retroativamente de maneira semelhante à descrita na Seção 5.
17. Isso pode ser resolvido restringindo a topologia de interconexão desses chips de AM para evitar seu uso em treinamento em larga escala. No entanto, os métodos para os Verificadores confirmarem retroativamente a topologia na qual os chips de AM foram configurados em uma central de dados estão além do escopo deste trabalho.
18. Como um exemplo trivial, o Provador poderia afirmar que ω era simplesmente o valor da inicialização aleatória e nenhum treinamento havia ocorrido no momento da fotografia instantânea.
19. Usamos “pontos de verificação de pesos” como abreviação, mas se estiver usando um otimizador como Adam [26], o estado do otimizador também deve ser incluído.
20. Observe que isso requer que o Provador salve e relate as transcrições de treinamento para todas as execuções de treinamento correspondentes aos chips tirados como amostras pelo Verificador, não apenas as de maior escala. Isso ocorre porque, sem uma transcrição de treinamento correspondente, é impossível para o Verificador determinar se um dado fragmento de pesos fazia parte de uma execução de treinamento em larga escala ou em pequena escala. Métodos alternativos para provar que um chip só estava envolvido numa execução de treinamento curta são uma direção importante para trabalhos futuros.
21. Manter esses clusters de treinamento compatíveis pode ser bastante desafiador. Uma direção desejável para trabalhos futuros está nos métodos de verificação pelos quais o Verificador não precisa reexecutar diretamente o treinamento do modelo. Por exemplo, pode ser possível para o Verificador consultar interativamente o Provador para obter informações adicionais sobre os segmentos da execução de treinamento além do que foi incluído na transcrição de treinamento. Pode haver consultas que tenham respostas válidas apenas se a transcrição de treinamento original for autêntica (p. ex., uma série de subpontos de verificação de pesos entre dois pontos de verificação, cada um com perda progressivamente menor) e o Provador puder recalcular dinamicamente as respostas a essas consultas usando sua própria central de dados. Embora algumas propriedades da verificação ainda precisem ser confirmadas usando um cluster neutro para manter a confidencialidade das respostas da consulta, esses clusters podem não precisar ser equipados para treinamento em larga escala e, portanto, são muito mais fáceis de manter.
22. No raro cenário em que um grande número de chips pertencentes ao mesmo Provador são perdidos ou destruídos de forma irreconhecível, o Verificador ou consórcio internacional pode iniciar uma investigação para determinar se o Provador está mentindo para escapar da supervisão.
23. Por razões semelhantes, o Departamento do Censo dos EUA opera Centrais de Dados Federais de Pesquisa Estatística seguras para fornecer aos pesquisadores acesso seguro a dados confidenciais [8].
Publicado originalmente em 30 de maio de 2023 aqui. Os apêndices não foram traduzidos.
Tradução: Luan Marques e Fernando Moreno