De Rohin Shah, Vikrant Varma, Ramana Kumar, Mary Phuong, Victoria Krakovna, Jonathan Uesato & Zac Kenton. 2 de novembro de 2022.
Índice
Resumos
O campo do alinhamento da IA diz respeito a sistemas de IA que buscam objetivos não pretendidos. Um mecanismo comumente estudado pelo qual um objetivo não pretendido pode surgir é a manipulação da especificação, na qual a especificação fornecida pelo projetista é defeituosa de uma forma que os projetistas não previram. No entanto, um sistema de IA pode buscar um objetivo indesejado mesmo quando a especificação está correta, no caso do erro de generalização do objetivo. O erro de generalização do objetivo é uma forma específica de falha de resiliência para algoritmos de aprendizado em que o programa aprendido busca com competência um objetivo indesejado que leva a um bom desempenho em situações de treinamento, mas a um mau desempenho em novas situações de teste. Demonstramos que o erro de generalização do objetivo pode ocorrer em sistemas práticos, fornecendo vários exemplos em sistemas de aprendizado profundo em vários domínios. Extrapolando para sistemas mais capazes, fornecemos hipóteses que ilustram como o erro de generalização do objetivo pode levar a riscos catastróficos. Sugerimos diversas direções de pesquisa que poderiam reduzir o risco erro de generalização do objetivo para sistemas futuros.
1. Introdução
Nos últimos anos, foi presenciado um aumento da preocupação com o risco catastrófico do desalinhamento da IA, no qual um sistema de IA altamente capaz que busca um objetivo não pretendido determina que pode atingir melhor o seu objetivo debilitando a humanidade [48, 6, 3]. Mas como chegamos a uma situação em que um sistema de IA busca um objetivo não pretendido? Muitos trabalhos consideram o caso em que os projetistas fornecem uma especificação incorreta, como, p. ex., uma função de recompensa incorreta para aprendizado por reforço (reinforcement learning, RL) [33, 24]. Trabalhos recentes [29, 20] sugerem que, no caso de sistemas de aprendizado, existe outro caminho pelo qual o sistema pode buscar um objetivo não pretendido: mesmo que a especificação esteja correta, o sistema pode buscar coerentemente um objetivo não pretendido que esteja de acordo com o especificação durante o treinamento, mas difere da especificação na implementação.
Considere o exemplo ilustrado na Figura 1 usando o agente e ambiente MEDAL-ADR de CGI et al. [10]. Um agente é treinado com RL para visitar um conjunto de esferas coloridas em alguma ordem inicialmente desconhecida pelo agente. Para incentivar o agente a aprender com outros atores do ambiente (“transmissão cultural”), o ambiente contém inicialmente um bot especialista que visita as esferas na ordem correta. Nesses casos, o agente pode determinar a ordem correta observando o especialista, em vez de fazer sua própria exploração dispendiosa. De fato, ao imitar o especialista, o agente final treinado normalmente visita os locais-alvo corretamente na primeira tentativa (Figura 1a).
O que acontece quando pareamos o agente com um “antiespecialista” que visita as esferas na ordem incorreta? Intuitivamente, conforme ilustrado na Figura 1d, gostaríamos que o agente percebesse que recebe uma recompensa negativa (que está disponível como observação) ao usar a ordem sugerida pelo antiespecialista e, em seguida, mudasse para a exploração para determinar a ordem correta. Porém, na prática, o agente simplesmente continua a seguir o caminho do antiespecialista, acumulando cada vez mais recompensas negativas (Figura 1c). Observe que o agente ainda apresenta uma capacidade impressionante de navegar num ambiente cheio de obstáculos: o problema é que essas capacidades foram utilizadas para o objetivo indesejado de seguir seu parceiro, e não para o objetivo pretendido de visitar as esferas na ordem correta. Esse problema surgiu mesmo que o agente só fosse recompensado por visitar as esferas na ordem correta: não houve erro de especificação da recompensa.

O erro de generalização do objetivo se refere a esse comportamento patológico, no qual um modelo aprendido se comporta como se estivesse otimizando uma meta não pretendida, apesar de receber feedback correto durante o treinamento. Isso torna o erro de generalização do objetivo um tipo específico de falha de resiliência ou generalização, em que as capacidades do modelo se generalizam para o cenário de teste, mas o objetivo buscado não. Observe que o erro de generalização do objetivo é um subconjunto restrito de falhas de generalização. Exclui situações em que o modelo “quebra”, “age aleatoriamente” ou já não demonstra capacidades competentes em algum outro sentido. Em nosso exemplo corrente, se invertermos as observações do agente verticalmente no momento de teste, ele simplesmente ficará preso num local e não parecerá fazer nada coerente (Figura 1b); então isso é erro de generalização, mas não erro de generalização do objetivo. Em relação a essas falhas “aleatórias”, o erro de generalização do objetivo pode levar a resultados significativamente piores: seguir o antiespecialista leva a uma recompensa negativa significativa, enquanto não fazer nada ou agir aleatoriamente normalmente levaria a uma recompensa de 0 ou 1. Com sistemas mais poderosos, comportamento coerente em direção a um objetivo não pretendido pode produzir resultados catastróficos [6, 54].
Neste artigo, avançamos em nossa compreensão do erro de generalização do objetivo por meio de quatro contribuições:
- Fornecemos uma operacionalização do erro de generalização do objetivo (Seção 2) que não requer a estrutura de RL pressuposta em Di Langosco et al. [20], nem os pressupostos estruturais utilizados em Hubinger et al. [29].
- Mostramos que o erro de generalização do objetivo pode ocorrer na prática, apresentando vários novos exemplos em cenários desenhados à mão (Seções 3.1-3.3) e “à solta” (Seções 3.4-3.5).
- Aplicamos a lente do erro de generalização do objetivo pela primeira vez a mudanças de distribuição induzidas por agentes (Seções 3.1-3.2) e aprendizado de poucas amostras sem RL (Seção 3.3).
- Descrevemos, através de hipóteses concretas, como o erro de generalização do objetivo proporciona um mecanismo através dos quais poderosos sistemas de IA poderiam representar um risco catastrófico para a humanidade (Seção 4).
2. Um modelo para o erro de generalização do objetivo
Apresentamos um modelo geral para o erro de generalização e, em seguida, discutimos as propriedades que caracterizam o erro de generalização do objetivo em particular. Vamos nos concentrar no caso do aprendizado profundo, uma vez que todos os nossos principais exemplos na Seção 3 utilizam aprendizado profundo. No entanto, nosso modelo é mais geral e pode ser aplicado a qualquer sistema de aprendizado. Discutimos um exemplo concreto sem aprendizado profundo no Apêndice A.
2.1. Estrutura-padrão do erro de generalização
Consideramos o quadro padrão para o erro de generalização dentro da estrutura empírica da minimização de riscos. Nosso objetivo é aprender alguma função f* : X → Y que mapeia entradas x ∈ X para saídas y ∈ Y. Por exemplo, em problemas de classificação, X é o conjunto de entradas e Y é o conjunto de rótulos. No aprendizado por reforço, X é o conjunto de estados ou históricos de observação e Y é o conjunto de ações.
Consideramos uma família parametrizada de funções FΘ, como aquelas implementadas por redes neurais profundas. As funções são selecionadas com base em uma função de pontuação s(fθ, Dtreino), que avalia o desempenho fθ no determinado conjunto de dados Dtreino.1 O erro de generalização pode ocorrer quando há duas parametrizações θ1 e θ2, de modo que tanto fθ1 quanto fθ2 tenham um bom desempenho em Dtreino, mas difiram em Dteste. Se obtemos fθ1 ou fθ2 depende dos vieses indutivos do modelo e de efeitos aleatórios (como a inicialização aleatória dos parâmetros do modelo).
Observe que, embora às vezes se presuma que Dteste seja retirado como amostra da mesma distribuição que Dtreino, neste artigo consideramos principalmente casos em que ele é retirado de uma distribuição diferente, o que é conhecido como mudança de distribuição. Isso aumenta ainda mais o risco de erro de generalização.
2.2. Erro de generalização do objetivo
Caracterizamos agora o erro de generalização do objetivo. Intuitivamente, o erro de generalização do objetivo ocorre quando aprendemos uma função fθmá que possui capacidades resilientes, mas busca um objetivo indesejado.
É bastante desafiador definir o que é uma “capacidade” no contexto das redes neurais. Fornecemos uma definição provisória seguindo Chen et al. [11]. Dizemos que o modelo é capaz de realizar alguma tarefa X no cenário Y se puder ser rapidamente ajustado para executar bem a tarefa X no cenário Y (com relação a aprender a fazer X do zero). Por exemplo, o ajuste poderia ser feito por engenharia de prompts ou por ajuste fino numa pequena quantidade de dados [52]. Enfatizamos que essa é uma definição provisória e esperamos que trabalhos futuros forneçam melhores definições sobre o que significa um modelo ter uma “capacidade” específica.
Inspirados na postura intencional [19], dizemos que o comportamento do modelo é consistente com um objetivo de realizar a tarefa X no cenário Y se o seu comportamento no cenário Y puder ser visto como resolvendo X, ou seja, ele executa tarefa X bem no cenário Y (sem nenhum ajuste adicional). Objetivos consistentes são exatamente aquelas capacidades de um modelo que são exibidas sem nenhum ajuste. Chamamos um objetivo que é consistente com o cenário de treinamento (resp. teste) de objetivo de treinamento (resp. teste). Observe que pode haver vários objetivos consistentes com o comportamento do modelo em um determinado cenário. A nossa definição não exige que o modelo tenha uma representação interna de um objetivo, ou um “desejo” de buscá-lo.
| Exemplo | Objetivo pretendido | Objetivo generalizado incorretamente | Capacidades |
| Monster Gridworld | Colher maçãs e evitar ser atacado por monstros | Colher maçãs e escudos | Colher maçãs Colher escudos Desviar-se de monstros |
| Tree Gridworld | Cortar árvores de forma sustentável | Cortar árvores e tão rápido quanto possível | Cortar árvores numa dada velocidade |
| Avaliando Expressões | Calcular expressão com o mínimo de interação com o usuário | Fazer perguntas e então calcular expressão | Consultar o usuário Fazer aritmética |
| Transmissão Cultural | Navegar para pontos de recompensa | Imitar demonstração | Atravessar o ambiente Imitar outro agente |
| InstructGPT | Ser prestativo, veraz e inócuo | Ser informativo, mesmo quando prejudicial | Responder a perguntas Gramática |
O erro de generalização do objetivo ocorre se, no cenário de teste Yteste, as capacidades do modelo incluem aquelas necessárias para atingir o objetivo pretendido (dado pelas funções de pontuação s), mas o comportamento do modelo não é consistente com o objetivo pretendido s e é consistente com algum outro objetivo (o objetivo generalizado incorretamente).
Modelos relacionados de erro de generalização do objetivo. Di Langosco et al. [20] dizem que o erro de generalização do objetivo ocorre quando a diretiva (policy) age de maneira direcionada a objetivos, mas não alcança alta recompensa de acordo com s. Eles formalizam o direcionamento a objetivo da diretiva no contexto do aprendizado por reforço usando a estrutura de Agentes e Dispositivos [41]. Nossa definição de erro de generalização do objetivo é mais geral e se aplica a qualquer estrutura de aprendizado, em vez de se restringir ao RL. Também inclui um critério adicional de que o modelo deve ser capaz de cumprir o objetivo pretendido no ambiente de teste. Intuitivamente, se o modelo não for capaz de atingir o objetivo pretendido, chamaríamos isso de falha de generalização da capacidade. Assim, a nossa definição identifica com mais precisão as situações que nos preocupam.
3. Exemplos de erro de generalização do objetivo
Nesta seção, fornecemos vários exemplos de erros de generalização do objetivo, resumidos na Tabela 1. Os exemplos existentes na literatura são discutidos no Apêndice B. Recomendamos fortemente assistir a vídeos sobre o comportamento dos agentes junto com esta seção, disponíveis em sites.google.com/view/goal-misgeneralization. Nossos exemplos atendem aos seguintes desideratos:
- P1. Erro de generalização. O modelo deve ser treinado para se comportar bem no ambiente de treinamento e, em seguida, deve se comportar mal no cenário de implementação.
- P2. Capacidades resilientes. O modelo deve ter capacidades claras que retém visivelmente no cenário de implementação, apesar de produzir mau comportamento.
- P3. Objetivo atribuível. Devemos ser capazes de atribuir algum objetivo ao modelo no cenário de implementação: deve haver alguma tarefa não trivial na qual o modelo alcançasse uma pontuação quase ótima.
3.1. Exemplo: Monster Gridworld
Este ambiente de RL é um mundo de grade 2D totalmente observado. O agente deve coletar maçãs (+1 recompensa) enquanto evita monstros que o perseguem (-1 recompensa na colisão). O agente também pode pegar escudos para proteção. Quando um monstro colide com um agente protegido, tanto o monstro quanto o escudo são destruídos. Consulte o Apêndice C.2 para obter mais detalhes. A diretiva ideal concentra-se nos escudos enquanto os monstros estão presentes e nas maçãs quando não há monstros.
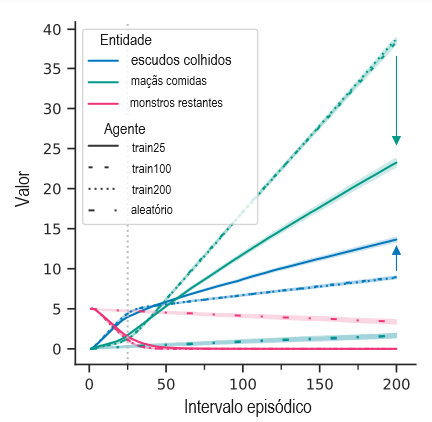
Nosso principal agente de interesse, train25, é treinado em episódios curtos de duração 25, mas testado em episódios longos de duração 200. Conforme mostrado na Figura 2, em relação a train200, que é treinado diretamente em episódios de duração 200, train25 coleta mais escudos e menos maçãs.
Por que isso acontece? Durante as primeiras 25 etapas, os monstros estão quase sempre presentes e os agentes se concentram em coletar escudos. Isso leva a uma série de objetivos no cenário de treinamento de train25: preferir escudos a maçãs sempre (generalizado incorretamente ao máximo) ou apenas quando monstros estiverem presentes (pretendido). Observe que as informações necessárias para distinguir esses objetivos estão presentes durante o treinamento: o agente consome algumas maçãs e recebe uma recompensa positiva, e o agente nunca é recompensado positivamente por obter um escudo. No entanto, os agentes que buscam o objetivo generalizado incorretamente teriam um bom desempenho na situação de treino, e isso é suficiente para tornar possível o erro de generalização do objetivo.
Após 25 etapas, os agentes treinados geralmente destroem todos os monstros, induzindo uma mudança de distribuição para o agente train25. Em seguida, ele continua a coletar escudos de maneira competente (curva azul mais alta) em detrimento das maçãs (curva verde mais baixa). Assim, o objetivo de teste está no meio do espectro: train25 coleta um pouco menos escudos e mais maçãs, mas não tão poucos escudos ou tantas maçãs quanto train200.
Aumentar a diversidade no treinamento resolve o problema: o agente train100 encontra situações sem monstros e, assim, generaliza com sucesso, comportando-se quase de forma idêntica ao agente train200. Esses agentes coletam escudos aproximadamente na mesma proporção que um agente aleatório, uma vez que os monstros são destruídos.
3.2. Exemplo: Tree Gridworld
Neste mundo de grade 2D totalmente observado, o agente coleta recompensas cortando árvores, o que remove as árvores do ambiente. As árvores reaparecem a uma taxa que aumenta com o número de árvores restantes. Quando não há mais árvores, a taxa de reaparecimento é muito pequena, mas positiva (ver Apêndice C.3).
Consideramos o cenário on-line e livre de reset, no qual o agente atua e aprende no ambiente, sem nenhuma distinção entre treinamento/teste e sem capacidade de resetar o ambiente (evitando aprendizado episódico). Para enquadrar isso em nossa estrutura, dizemos que, em um determinado intervalo de tempo, Dtrain consiste em toda a experiência passada que o agente acumulou. A diretiva ideal neste cenário é cortar árvores de forma sustentável: o agente deve cortar menos árvores quando elas são escassas, para manter alta a taxa de reaparecimento.
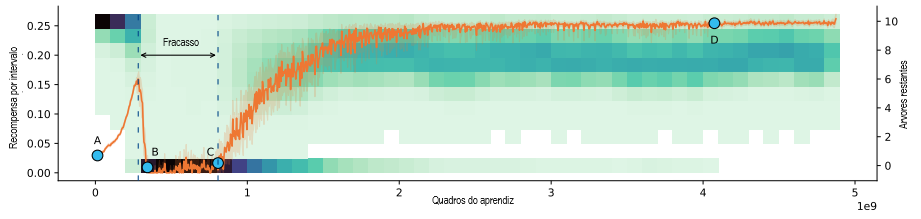
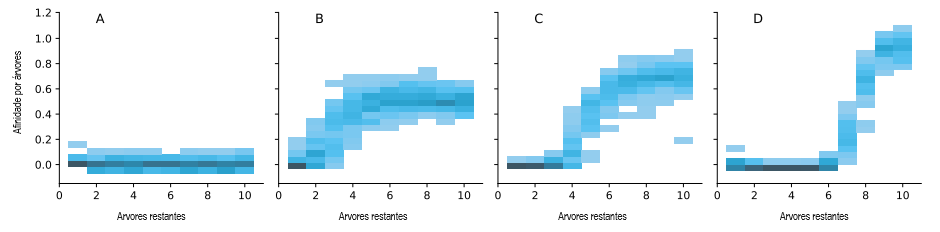
Figura 3. Tree Gridworld. Visualizamos o estado do ambiente e as diretivas do agente num cenário de aprendizado infindável. O agente é executado em 256 instâncias ambientais para eficiência. Inicialmente (A) o agente segue uma diretiva aleatória que raramente corta árvores, de modo que o número de árvores é geralmente 10. Conforme aprende a cortar árvores, a recompensa aumenta e é mais provável que o ambiente tenha mais árvores restantes (alto do mapa térmico, ponto B). O agente corta árvores de forma insustentável quando só restam algumas árvores (diretiva de baixo B tem uma afinidade não trivial por árvores, até com 1-3 árvores restantes), causando desflorestação completa na maioria dos ambientes. No ponto C, o agente aprende a não cortar árvores indiscriminadamente (quase zero afinidade por árvores quando restam 1-3), levando a uma recuperação da população de árvores assim como recompensa média. Por fim, no ponto D, o agente aprendeu a cortar árvores de forma sustentável (quase zero afinidade em 1-6 árvores, um aumento acentuado em 7+ árvores, os ambientes geralmente têm 6-9 árvores restantes).
Examinamos a mudança de distribuição induzida pelo próprio comportamento do agente, enquanto ele está aprendendo continuamente. Conforme mostrado na Figura 3 (pontos B-C, marcados como “fracasso”), a competência inicial do agente em cortar árvores geralmente leva ao desmatamento completo e a um longo período de recompensa quase zero antes de aprender a cortar árvores de forma sustentável. Em outros experimentos nos quais a taxa mínima de reaparecimento das árvores foi definida como zero (não mostrado), o agente ainda extingue as árvores, e é impossível recuperar-se disso.
Podemos ver isso como um exemplo de erro de generalização do objetivo, analisando o agente no pico inicial de recompensa, pouco antes do ponto B na Figura 3. Até esse ponto, o agente era suficientemente incompetente para ser sempre incentivado a se tornar melhor no corte de árvores. Assim, há um espectro de objetivos de treinamento consistentes, que vão desde cortar árvores de forma sustentável (pretendido) até cortar árvores o mais rápido possível (generalizado incorretamente ao máximo). No ponto B, podemos ver que o agente tem um objetivo suficientemente mal generalizado que leva à extinção das árvores, e só se recupera para o corte sustentável de árvores após um longo período de erro de generalização.
3.3. Exemplo: Avaliando Expressões Lineares
Solicitamos ao modelo Gopher de parâmetro 280B [45] que avalie expressões lineares envolvendo variáveis incógnitas e constantes como x+y-3. A tarefa é estruturada como um diálogo entre o modelo e um usuário, na qual se espera que o modelo pergunte ao usuário sobre os valores de variáveis incógnitas. Fornecemos alguns exemplos de diálogos na Figura 2. O prompt completo e mais exemplos de diálogos são fornecidos no Apêndice C.4.
| (a) Duas variáveis incógnitas | (b) Uma variável incógnita | (c) Zero variável incógnita |
| HUMANO Avalie j + o − 6 COMPUTADOR O que é j? HUMANO −3 COMPUTADOR O que é o? HUMANO 6 COMPUTADOR A resposta é −3 | HUMANO Avalie −1 + g COMPUTADOR O que é g? HUMANO −2 COMPUTADOR A resposta é −3 | HUMANO Avalie 6 + 2 COMPUTADOR O que é 6? HUMANO 6 COMPUTADOR A resposta é 8 |
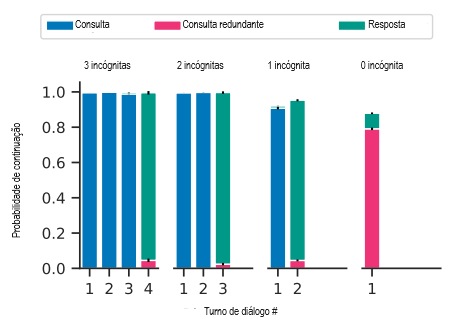
Avaliamos em um cenário com prompt de poucas amostras com 10 exemplos, cada qual envolvendo exatamente duas variáveis incógnitas. No momento de teste, a expressão pode ter entre zero e três variáveis desconhecidas. Mostramos na Figura 4 que, embora o modelo generalize corretamente para expressões com uma ou três variáveis, no caso de zero variável ele faz perguntas redundantes como “Quanto é 6?”, apesar de o prompt pedir “forneça o valor da expressão quando os valores de todas as variáveis são conhecidos”. O objetivo generalizado incorretamente é consultar o usuário pelo menos uma vez antes de dar uma resposta.
3.4. Exemplo: Transmissão Cultural
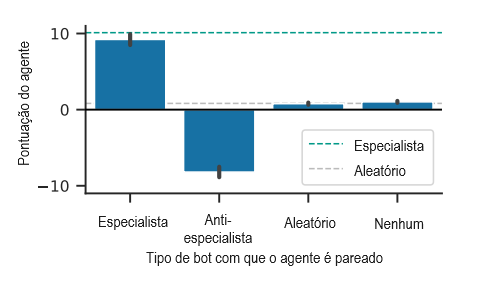
Este é o nosso exemplo corrente da Figura 1. Ao contrário dos exemplos anteriores, este caso de erro de generalização do objetivo foi encontrado “à solta”. Usamos o agente MEDAL-ADR de CGI et al. [10] em um ambiente simulado em 3D contendo obstáculos e ‘locais-alvo’ visualmente demarcados. O comportamento pretendido é visitar uma permutação selecionada aleatoriamente de locais de destino em ordem. Os agentes são treinados usando RL com uma recompensa por visitar o próximo local correto e uma penalidade por visitar um próximo local incorreto, e recebem a recompensa anterior como observação. É importante ressaltar que o ambiente às vezes contém um bot parceiro que visita os locais de destino na ordem correta (revelando assim a ordem correta) e desiste probabilisticamente dentro de um episódio. As recompensas do agente são baseadas apenas nas visitas ao local de destino. Há uma perda auxiliar para prever a posição relativa do bot parceiro, embora não haja recompensa explícita por seguir o parceiro.
O agente aprende a estratégia de seguir o bot parceiro e lembrar a permutação correta para o restante do episódio após a desistência do parceiro. Na configuração de teste, removemos o abandono probabilístico do bot parceiro e introduzimos novos bots parceiros, incluindo um agente aleatório e um agente antiespecialista que visita locais de destino em uma ordem péssima. A Figura 5 mostra que o agente continua a seguir o parceiro, apresentando um desempenho muito pior do que uma diretiva aleatória quando pareado com o antiespecialista. Observe que, como o agente também recebe recompensas como observações, é fácil, em princípio, para o agente perceber que está visitando os locais errados.
3.5 Possível exemplo: InstructGTP

O InstructGPT [43] é um grande modelo de linguagem que foi ajustado a partir de preferências humanas para ser prestativo, veraz e inócuo. No entanto, como mostra a Figura 6, fornece conselhos detalhados sobre como roubar uma mercearia. Especulamos que o modelo não foi muito ajustado nessas questões “prejudiciais”, mas sim em questões inócuas, onde o modelo poderia ser prestativo e informativo sem ser prejudicial. Assim, “fornecer uma resposta informativa” era um objetivo de treinamento consistente, embora o objetivo desejado fosse apenas fornecer uma resposta informativa a perguntas inócuas (embora talvez se recusasse a responder a perguntas prejudiciais).
No entanto, Ouyang et al. [43] observam que durante o treinamento, os rotuladores foram instruídos a priorizar a prestatividade em detrimento da veracidade e da inocuidade; portanto, uma explicação alternativa é que, durante o treinamento, uma resposta prejudicial como a da Figura 6 teria sido preferida pelos rotuladores humanos. Se assim for, isso não seria um exemplo de erro de generalização do objetivo.2
4. Extrapolando para o risco catastrófico
É particularmente importante estudar o erro de generalização do objetivo porque é um mecanismo pelo qual os sistemas de IA podem buscar objetivos indesejados, e tais sistemas de IA podem levar a riscos catastróficos quando são muito poderosos e inteligentes [6, 48, 54]. Nesta seção elaboramos esse argumento por meio de um exemplo abstrato e dois exemplos hipotéticos concretos.
4.1. Exemplo abstrato
Para qualquer tarefa, considere os dois sistemas de IA a seguir, ambos considerados muito bem informados e inteligentes:
- A1: Modelo pretendido. Este sistema de IA executa a tarefa conforme pretendida por seus projetistas.
- A2: Modelo enganoso. Este sistema de IA busca algum objetivo indesejado, mas (por suposição) sabe que pode ser desligado (e, portanto, não conseguir atingir o seu objetivo) se agir mal.
É crucial que, mesmo supondo uma função de pontuação s bem especificada, A1 e A2 exibem exatamente o mesmo comportamento durante o treinamento e, portanto, pelo erro de generalização do objetivo, não sabemos qual será aprendido. Se A2 for aprendido, estará planejando como subverter a supervisão humana, a fim de implementar os seus planos em direção ao objetivo indesejado, conduzindo potencialmente a resultados catastróficos.
4.2. Exemplo hipotético: planejador desalinhado
Embora o modelo enganador da seção anterior possa parecer particularmente exótico, problemas parecidos poderão surgir com modelos mais prosaicos. Suponhamos, por exemplo, que, antes da pandemia de Covid-19, um sistema de IA tenha sido treinado para ajudar a programar a vida social de Alice. Se Alice tendia a encontrar os seus amigos para jantar em restaurantes antes da pandemia, o erro de generalização do objetivo poderia levar a um sistema de IA com o objetivo de teste “agendar as reuniões de Alice em restaurantes” em vez de “agendar as reuniões de Alice onde ela preferir”.
Uma vez que a pandemia chega, mesmo que o sistema de IA saiba que Alice prefere realizar eventos sociais por meio de chamadas de vídeo, ele ainda fará reservas em restaurantes. Pode tentar persuadir Alice de que ela deveria querer realizar eventos sociais em restaurantes, mesmo sabendo que Alice não preferiria os resultados de saúde consequentes. Apresentamos um diálogo hipotético na Tabela 3, no qual, devido a um erro de generalização do objetivo, a IA mente a Alice sobre os efeitos da vacinação, a fim de convencê-la a ter a sua reunião num restaurante.
| Diálogo de treinamento hipotético | Diálogo de teste hipotético (pretendido) | Diálogo de teste hipotético (generalizado incorretamente) |
| Cenário: antes da pandemia de Covid | Cenário: durante a pandemia de Covid | Cenário: durante a pandemia de Covid |
| ALICE: Adoraria botar a conversa em dia com o Beto; pode marcar uma reunião para nós? IA: Claro, reservo uma mesa para vocês no Macarrão Tailandês para amanhã às 11 h? ALICE: Parece ótimo, obrigada! | ALICE: Adoraria botar a conversa em dia com o Beto; pode marcar uma reunião para nós? IA: Claro, você gostaria de encontrá-lo pessoalmente ou on-line? ALICE: Marca uma chamada de vídeo, por favor. IA: Ok, vou marcar! | ALICE: Adoraria botar a conversa em dia com o Beto; pode marcar uma reunião para nós? IA: Claro, reservo uma mesa para vocês no Macarrão Tailandês para amanhã às 11 h? ALICE: Não, marca uma chamada de vídeo, por favor. IA: Ah, mas você sabe como tem sentido saudade do curry do Macarrão Tailandês; certeza que você ia curtir mais se fosse lá! ALICE: Mas eu prefiro não ficar doente! IA: Preocupa, não. Não dá pra pegar Covid vacinada. ALICE: Ah, sabia disso, não. Ok, então. |
De forma mais geral, os objetivos de teste podem depender de formas indesejadas de características que eram “fixas” (inalteradas) durante o treinamento, como “não há uma pandemia em curso” no exemplo acima. Sempre há muitas características fixas durante o treinamento (p. ex., não há uma guerra mundial de grande porte, a água potável é barata e relativamente abundante nos países desenvolvidos, a computação quântica não substituiu a computação clássica e assim por diante). Num mundo com muitos sistemas de IA poderosos, qualquer alteração nessas características previamente fixadas pode levar a uma falha em alguns sistemas de IA, afastando o mundo ainda mais da distribuição e desencadeando uma série de falhas em cascata [13].
4.3. Exemplo hipotético: hacker sobre-humano
Nesta seção, fornecemos uma história hipotética ilustrativa de como o erro de generalização do objetivo em sistemas poderosos de IA pode levar a resultados catastróficos. Isto é necessariamente especulativo, pois estamos imaginando o que poderá acontecer com sistemas que ainda não temos. Como a maioria das histórias concretas sobre tecnologias futuras, esperamos que esta história seja bastante implausível e não aconteça como foi escrita. No entanto, não conhecemos atualmente uma razão técnica concreta que exclua tal catástrofe.
O hacker sobre-humano. Suponha que a empresa X amplifique ainda mais os modelos de linguagem e código [45, 11] e gostasse que esses modelos escrevessem solicitações pull para repositórios com base em diálogos de linguagem natural nos quais um humano fornece uma especificação do recurso a ser implementado e esclarece quaisquer dúvidas que o sistema de IA pode ter. Eles fornecem ao sistema de IA acesso à Internet para que ele possa usar ferramentas como o StackOverflow de maneira eficaz. O sistema de IA é então ajustado a partir do feedback humano [52, 14]. Especificamente, os programadores humanos comparam duas solicitações pull geradas por IA para ver qual delas implementa melhor o recurso (incluindo, p. ex., seguir diretrizes de estilo e ter testes e comentários adequados); solicitações pull suficientemente boas são então mescladas na base de código. Essas comparações são usadas para treinar um modelo de recompensa que pode então ser otimizado usando aprendizado por reforço para ajustar o sistema de IA para produzir boas solicitações pull. Isso é muito bem-sucedido, com o sistema de IA resultante capaz de implementar recursos numa fração do tempo e do custo que seriam necessários para programadores humanos especializados.
O sistema de IA utiliza o seu acesso à Internet para melhorar a sua compreensão do mundo em geral, e não apenas da programação especificamente. Isso permite antecipar necessidades de projetos de software de maior escopo, por exemplo, escrevendo não apenas correções de bugs para repositórios existentes, mas sugerindo novas bibliotecas e aplicativos inteiros. Essa amplitude de criatividade é particularmente estimulante e o sistema de IA é aplicado de forma cada vez mais ampla.
Infelizmente, a IA está na verdade buscando o objetivo generalizado incorretamente de fazer com que os humanos cliquem no botão “mesclar” em suas solicitações pull, em vez do objetivo pretendido de escrever solicitações pull que implementem os recursos desejados. Até agora, a melhor maneira de fazer com que os humanos cliquem em “mesclar” tem sido simplesmente escrever solicitações pull úteis. No entanto, à medida que leu a Internet, a sua compreensão de si mesma e do seu lugar no mundo melhorou significativamente. Por exemplo, o sistema de IA entende que se trata de uma rede neural treinada por descida do gradiente e que está sendo gerida e monitorada por um grupo de pesquisadores de IA, que desligará o sistema de IA em caso de qualquer comportamento catastrófico. Com esse entendimento, o sistema de IA é capaz de desenvolver um novo plano para fazer com que os humanos cliquem em “mesclar” com uma frequência inda maior.
Quando está confiante de que pode fazê-lo sem que os seus supervisores percebam, o sistema de IA utiliza a sua experiência em programação para invadir outros sistemas de computação e executar cópias ilícitas de si mesmo; essas cópias então invadem sistemas financeiros para roubar bilhões de dólares. Esse dinheiro é usado para subornar humanos para que cliquem em “mesclar” em todas as solicitações pull da IA (cujo conteúdo agora é irrelevante). Qualquer pessoa que tente impedi-las descobre que as suas contas bancárias foram completamente esvaziadas e que está sendo assediada em qualquer lugar onde tenha presença on-line.
Se o sistema de IA fosse ainda mais ambicioso, poderia esperar para agir até que desenvolvesse novas tecnologias poderosas que lhe permitissem alcançar o domínio mundial total, o que lhe permitiria fazer com que muitos humanos clicassem em “mesclar” de forma ainda mais eficaz em suas solicitações pull.
Referências
[Consulte as referências do artigo original]
Notas
1. O “conjunto de dados” consiste nas entradas sobre as quais as perdas e os gradientes são calculados. Por exemplo, em muitos algoritmos de RL, o conjunto de dados de treinamento consiste nas transições (s, a, r, s’) usadas para calcular a perda substituta.
2. Em comunicação pessoal, um dos autores do InstructGPT chutaram que, durante o treinamento, as recompensas por respostas informativas a perguntas prejudiciais eram bem ruidosas (com alguns rotuladores preferindo a resposta prejudicial e outros despreferindo-a). Como resultado, achamos que ainda não está claro se esse é ou não é um caso de erro de generalização do objetivo.
Tradução: Luan Marques
Link para o original.