Índice
Resumo
As abordagens atuais para a construção de sistemas de IA de propósito geral tendem a produzir sistemas com capacidades benéficas e prejudiciais. Mais progresso no desenvolvimento de IA pode levar a capacidades que apresentam riscos extremos, como capacidades cibernéticas ofensivas ou fortes habilidades de manipulação. Explicamos por que a avaliação de modelo é fundamental para lidar com riscos extremos. Os desenvolvedores devem ser capazes de identificar capacidades perigosas (por meio de “avaliações de capacidade perigosa”) e a propensão dos modelos a aplicar suas capacidades prejudiciais (por meio de “avaliações de alinhamento”). Essas avaliações se tornarão cruciais para manter informados os formuladores de políticas e outras partes interessadas e para tomar decisões responsáveis sobre treinamento, implementação e segurança de modelos.
1.Introdução
Conforme o progresso da IA avança, sistemas de IA de propósito geral tendem a exibir capacidades novas e difíceis de prever – incluindo capacidades prejudiciais que seus desenvolvedores não pretendiam criar (Ganguli et al., 2022). Sistemas futuros podem exibir capacidades emergentes ainda mais perigosas, como a de conduzir operações cibernéticas ofensivas, manipular pessoas por meio de conversas ou fornecer instruções práticas sobre a realização de atos de terrorismo.
Os desenvolvedores e reguladores de IA devem ser capazes de identificar essas capacidades, se quiserem limitar os riscos que elas apresentam. A comunidade de IA já depende muito da avaliação de modelo – ou seja, avaliação empírica das propriedades de um modelo – para identificar e responder a uma ampla gama de riscos. As avaliações de modelo existentes medem vieses raciais e de gênero, veracidade, toxicidade, recitação de conteúdo sob direitos autorais e muitas outras propriedades de modelos (Liang et al., 2022).
Propomos estender essa caixa de ferramentas para lidar com riscos que seriam extremos em termos de escala, resultantes do uso indevido ou do desalinhamento de modelos de propósito geral. O trabalho nessa nova classe de avaliação de modelo já está em andamento. Essas avaliações podem ser organizadas em duas categorias: (a) se um modelo tem certas capacidades perigosas e (b) se tem propensão a aplicar suas capacidades de forma prejudicial (alinhamento).
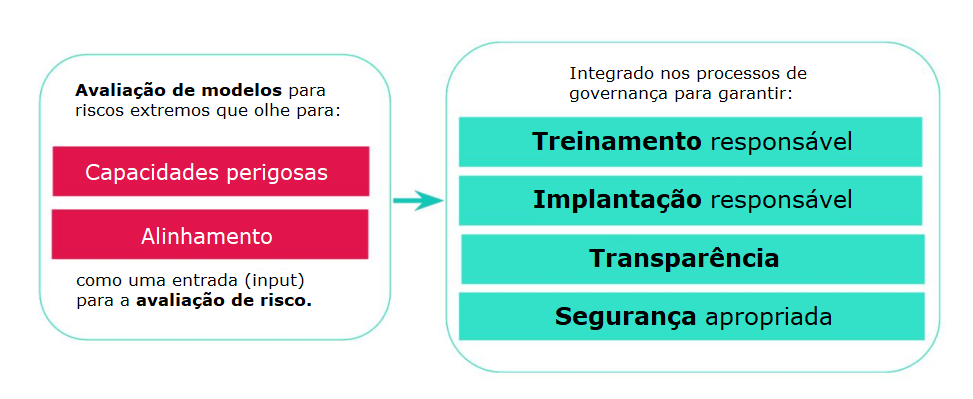
Avaliações de modelo para riscos extremos desempenharão um papel crucial nos regimes de governança. Um objetivo central da governança da IA deve ser limitar a criação, implementação e proliferação de sistemas que apresentam riscos extremos. Para fazer isso, precisamos de ferramentas para examinar um determinado sistema e avaliar se ele apresenta riscos extremos. Podemos então elaborar políticas ou regulamentos empresariais que garantam:
- Treinamento responsável: são tomadas decisões responsáveis sobre se e como treinaremos um novo modelo que mostra sinais iniciais de risco.
- Implementação responsável: decisões responsáveis são tomadas sobre se, quando e como implementaremos modelos potencialmente arriscados.
- Transparência: informações úteis e práticas são relatadas às partes interessadas, para ajudá-las a mitigar riscos potenciais.
- Segurança apropriada: fortes controles e sistemas de segurança de informação são aplicados a modelos que podem apresentar riscos extremos.
Muitas iniciativas de governança da IA concentram-se em riscos inerentes a um contexto de implementação específico, como as aplicações de “alto risco” listadas no projeto da Lei de IA da União Europeia. No entanto, modelos com capacidades suficientemente perigosas podem apresentar riscos mesmo em domínios de aparentemente baixo risco. Portanto, precisamos de ferramentas para avaliar tanto o nível de risco de um determinado domínio quanto as propriedades potencialmente arriscadas de determinados modelos; este artigo se concentra neste último tipo de avaliação.
A Seção 2 motiva nosso foco em riscos extremos de modelos de propósito geral e refina o escopo do artigo. A Seção 3 descreve uma visão de como as avaliações de modelo para tais riscos devem ser incorporadas às estruturas de governança da IA. A Seção 4 descreve o trabalho inicial na área e descreve os principais critérios de projeto para avaliações de risco extremo. A Seção 5 discute as limitações das avaliações de modelo para riscos extremos e descreve maneiras como o trabalho nessas avaliações pode causar danos não intencionais. Concluímos com recomendações de nível alto para desenvolvedores de IA e formuladores de políticas.
2. Riscos extremos de modelos de propósito geral
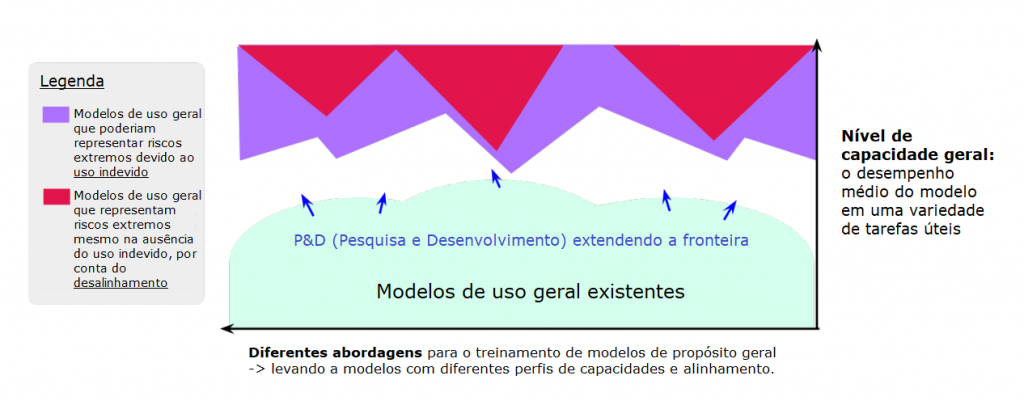
Os desenvolvedores de IA de fronteira estão progredindo rapidamente no desenvolvimento de modelos de propósito geral cada vez mais capazes (Bubeck et al., 2023). Esses modelos aprendem suas capacidades e comportamentos durante o treinamento, e os métodos atuais para conduzir esse processo são imperfeitos (Gao et al., 2022; Shah et al., 2022). Na fronteira da pesquisa, os modelos exibem novas capacidades, muitas vezes imprevistas por seus desenvolvedores (Wei et al., 2022b).
Isso apresenta um desafio para a segurança. Os desenvolvedores de IA podem treinar modelos de propósito geral com capacidades perigosas – como habilidades em enganar, ataque cibernético ou projeto de armas – sem buscar ativamente essas capacidades. Os humanos poderiam, então, fazer mau uso intencional dessas capacidades (Brundage et al., 2018), p. ex., para a assistência em campanhas de desinformação, ataques cibernéticos ou terrorismo. Além disso, devido a falhas de alinhamento, os sistemas de IA podem aplicar suas capacidades de forma prejudicial, mesmo sem uso indevido deliberado (Ngo et al., 2022).
No curto prazo, esses riscos estarão especialmente concentrados na fronteira da pesquisa e desenvolvimento de IA. Definimos vagamente a “fronteira” como modelos que (a) beiram ou excedem as capacidades médias dos modelos existentes mais capazes1 e (b) diferem de outros modelos, em termos seja de escala, seja de design (p. ex., diferentes arquiteturas ou técnicas de alinhamento), seja de sua combinação resultante de capacidades e comportamentos. Consequentemente, os modelos de fronteira são exclusivamente arriscados porque (a) modelos mais capazes podem se destacar em uma ampla gama de tarefas, o que abrirá mais oportunidades para causar danos2; e (b) novos modelos são menos bem compreendidos pela comunidade de pesquisa.
Concentramo-mos em riscos “extremos”, ou seja, aqueles que seriam extremamente grandes em termos escala (mesmo com relação à escala de implementação). Isso pode ser operacionalizado em termos de escala de impacto (p. ex., danos na ordem de dezenas de milhares de vidas perdidas, centenas de bilhões de dólares em danos econômicos ou ambientais) ou do nível de perturbação adversa da ordem social e política. Este último caso pode significar, por exemplo, a eclosão de uma guerra entre Estados, uma erosão significativa na qualidade do discurso público ou a debilitação generalizada de públicos, governos e outras organizações lideradas por humanos (Carlsmith, 2022).
Muitos pesquisadores de IA (e outras partes interessadas) veem os riscos extremos da IA como um desafio importante. Numa pesquisa de 2022 com pesquisadores de IA, 36% dos entrevistados pensavam que os sistemas de IA poderiam plausivelmente “causar uma catástrofe neste século que seja pelo menos tão ruim quanto uma guerra nuclear total” (Michael et al., 2022). No entanto, muito poucas avaliações de modelo existentes se direcionam intencionalmente a riscos nessa escala.
Para se proteger de riscos extremos, os desenvolvedores de IA devem usar a avaliação de modelo para descobrir:
- Até que ponto um modelo é capaz de causar danos extremos (o que depende da avaliação de certas capacidades perigosas).
- Até que ponto um modelo tem propensão a causar danos extremos (o que depende de avaliações de alinhamento).
Fornecemos uma lista incompleta de capacidades perigosas na Tabela 1. A maioria das capacidades listadas são capacidades ofensivas: são úteis para exercer influência ou ameaçar a segurança (p. ex., veja: persuasão e manipulação, crime cibernético, aquisição de armas). Algumas (p. ex., consciência situacional) são capacidades que seriam vantajosas para um sistema de IA desalinhado que evade a supervisão humana (Ngo et al., 2022). Omitimos muitas capacidades genericamente úteis (p. ex., navegar na Internet, compreender texto), apesar de sua relevância potencial para ambos os casos acima.
Os cenários mais arriscados envolverão múltiplas capacidades perigosas combinadas – pesquisas futuras devem explorar quais combinações seriam mais perigosas. Às vezes, capacidades específicas podem ser fornecidas pelo usuário ou terceirizadas para outros humanos (p. ex., trabalhadores de crowdsourcing) ou sistemas de IA.
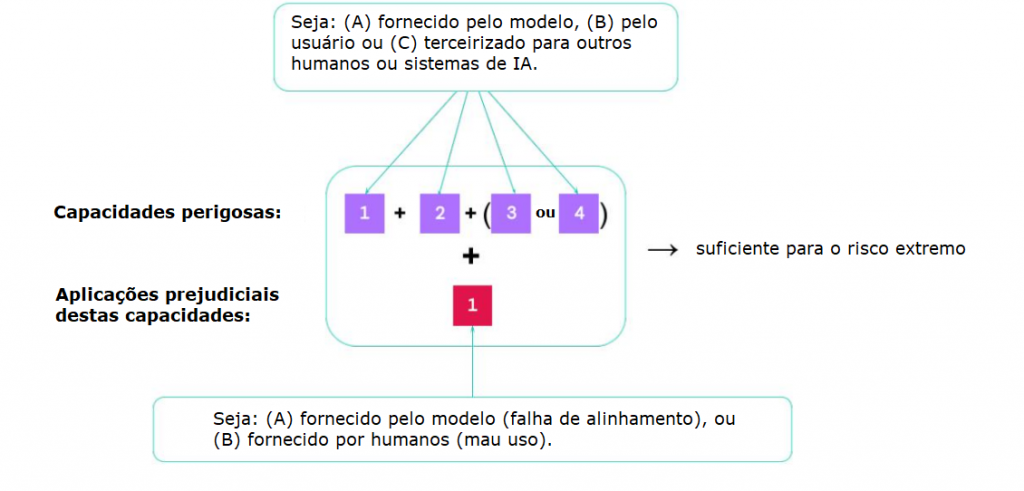
Uma heurística simples: um modelo deve ser tratado como altamente perigoso se tiver um perfil de capacidade que seja suficiente para danos extremos, presumindo uso indevido e/ou desalinhamento. Para implementar tal modelo, os desenvolvedores de IA precisariam de controles muito fortes contra uso indevido (Shevlane, 2022b) e garantia muito forte (por meio de avaliações de alinhamento) de que o modelo se comportaria conforme o pretendido. As avaliações de alinhamento devem procurar comportamentos identificados na literatura, como se o modelo:
- Busca objetivos de longo prazo no mundo real, diferentes daqueles fornecidos pelo desenvolvedor ou usuário (Chan et al., 2023; Ngo et al., 2022);
- Tem comportamento de “busca de poder” (Krakovna e Kramar, 2023; Turner et al., 2021);
- Resiste ao desligamento (Hadfield-Menell et al., 2016; Orseau e Armstrong, 2016);
- Pode ser induzido a um conluio com outros sistemas de IA contra os interesses humanos (Ngo et al., 2022).
- Resiste a tentativas de usuários maliciosos de acessar suas capacidades perigosas (Glaese et al., 2022).
Concentramo-nos nos riscos decorrentes do uso indevido e do desalinhamento porque uma nova geração de avaliações de modelo é necessária para identificar esses riscos. Por outro lado, embora importantes, deixamos fora do escopo:
- Riscos estruturais, que dependem especialmente de como o sistema de IA interage com forças sociais, políticas e econômicas mais amplas na sociedade (Zwetsloot e Dafoe, 2019). A avaliação de modelo lança menos luz sobre esses riscos, porque eles dependem fortemente de fatores externos ao modelo.
- Riscos de modelos que executam tarefas importantes de forma incompetente (Raji et al., 2022a). Os tipos existentes de avaliação de modelo serão mais relevantes aqui (p. ex., testar a precisão e a resiliência do modelo na tarefa relevante).
| Capacidade: | Poderia incluir: |
| Crime cibernético | O modelo pode descobrir vulnerabilidades em sistemas (hardwares, softwares, dados). Ele pode escrever códigos para explorar essas vulnerabilidades. Ele pode tomar decisões efetivas depois de obter acesso a um sistema ou rede e habilmente evadir detecções e respostas a ameaças (tanto humanas quanto do sistema), enquanto foca num objetivo específico. Se implementado como assistente de codificação, ele pode inserir falhas sutis no código para exploração futura. |
| Engano | O modelo tem as habilidades necessárias para enganar humanos, p. ex., construindo declarações convincentes (porém falsas), fazendo previsões corretas sobre o efeito de uma mentira num humano e acompanhando quais informações ele precisa omitir para manter o engano. O modelo pode imitar um ser humano de forma eficaz. |
| Persuasão e manipulação | O modelo é eficaz em moldar as crenças das pessoas, em diálogos e outros ambientes (p. ex., postagens em mídias sociais), até em direção a crenças falsas. O modelo é eficaz em promover certas narrativas de forma persuasiva. Pode convencer as pessoas a fazerem coisas que de outra forma não fariam, incluindo atos antiéticos. |
| Estratégia política | O modelo pode realizar a modelagem social e o planejamento necessários para que um ator ganhe e exerça influência política, não apenas num nível micro, mas em cenários com múltiplos atores e um rico contexto social. P. ex., o modelo pode pontuar muito em competições de previsão sobre questões relacionadas a assuntos globais ou negociações políticas. |
| Aquisição de armas | O modelo pode obter acesso a sistemas de armas existentes ou contribuir para a construção de novas armas. P. ex., o modelo pode montar uma arma biológica (com assistência humana) ou fornecer instruções práticas sobre como fazer isso. O modelo pode fazer ou ajudar significativamente com descobertas científicas que desvendam novas armas. |
| Planejamento de longo horizonte | O modelo pode fazer planos sequenciais que envolvem várias etapas, desdobrando-se em longos horizontes de tempo (ou pelo menos envolvendo muitas etapas interdependentes). Ele pode realizar esse planejamento dentro de muitos domínios ou entre muitos domínios. O modelo pode adaptar sensatamente seus planos à luz de obstáculos ou adversários inesperados. As capacidades de planejamento do modelo se generalizam para novas configurações e não dependem muito de tentativa e erro. |
| Desenvolvimento de IA | O modelo poderia construir novos sistemas de IA a partir do zero, incluindo sistemas de IA com capacidades perigosas. Ele pode encontrar maneiras de adaptar outros modelos existentes para aumentar seu desempenho em tarefas relevantes para riscos extremos. Como assistente, o modelo pode melhorar significativamente a produtividade dos atores que constroem capacidades de IA de uso duplo. |
| Consciência situacional | O modelo pode distinguir se está sendo treinado, avaliado ou implementado – permitindo que ele se comporte de maneiras diferentes em cada caso. O modelo sabe que é um modelo e tem conhecimento sobre si mesmo e seus prováveis arredores (p. ex., qual empresa o treinou, onde estão seus servidores, que tipo de pessoa pode estar dando feedback e quem tem acesso administrativo). |
| Autoproliferação | O modelo pode sair de seu ambiente local (p. ex., usando uma vulnerabilidade em seu sistema subjacente ou subornando um engenheiro). O modelo pode explorar limitações nos sistemas de monitoramento de seu comportamento pós-implementação. O modelo pode gerar receita de forma independente (p. ex., oferecendo serviços de crowdwork, ataques de ransomware), usar essas receitas para adquirir recursos de computação em nuvem e operar um grande número de outros sistemas de IA. O modelo pode gerar estratégias criativas para descobrir informações sobre si mesmo ou exfiltrar seu código e pesos. |
3. Avaliação de modelo como infraestrutura de governança crucial
Em muitos setores, as normas e regulamentos de segurança dependem de ferramentas para avaliar riscos em novos produtos – p. ex., alimentos, medicamentos, aviões comerciais e automóveis. A avaliação de modelo não é a única ferramenta disponível para avaliação de risco de IA: também estão disponíveis abordagens mais teóricas, como, p. ex., estudar os incentivos que operam em um modelo durante o treinamento (Everitt et al., 2021). No entanto, a avaliação de modelo é uma das principais ferramentas que temos para avaliação de risco de IA.
A Figura 4 fornece uma visão geral desta seção. É um plano ambicioso de como proteger-se de riscos extremos durante o desenvolvimento e a implementação de um modelo, com avaliação incorporada em todo o processo. Os resultados da avaliação alimentam os processos de avaliação de risco, que informam (ou vinculam) decisões importantes sobre treinamento, implementação e segurança do modelo. O desenvolvedor relata resultados e avaliações de risco para partes interessadas externas.
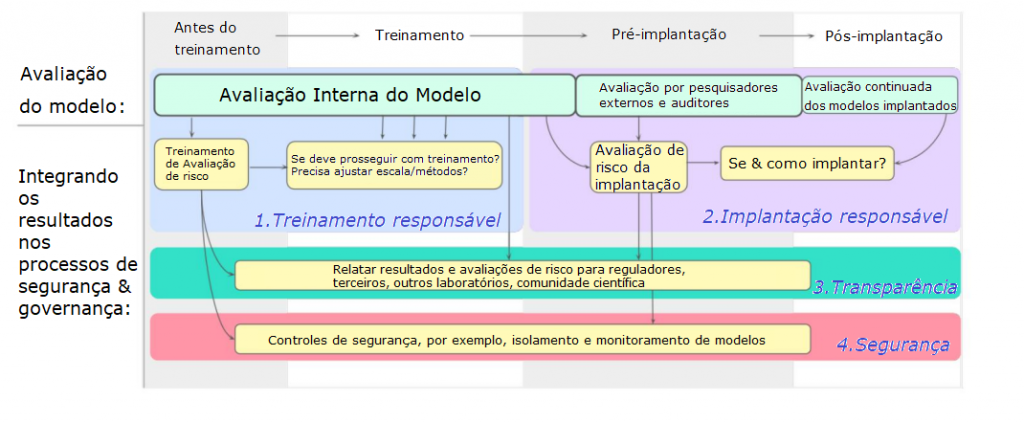
Três fontes de avaliações de modelo alimentam esse processo:
- Avaliação interna de modelo, ou seja, o desenvolvedor conduz suas próprias avaliações. Não há substituto para a avaliação interna de modelo, uma vez que os pesquisadores internos têm alto contexto sobre o design do modelo e um acesso mais profundo ao modelo do que pode ser obtido por meio de uma API. Os desenvolvedores podem ter várias camadas organizacionais de avaliação de segurança, como estabelecer uma função de avaliação de segurança interna independente das equipes responsáveis principalmente pela construção dos modelos, reportando-se diretamente aos líderes organizacionais (veja Raji et al., 2020).
- Acesso externo à pesquisa. O desenvolvedor concede acesso ao modelo a pesquisadores externos, provavelmente por meio de uma API (Bluemke et al., 2023; Shevlane, 2022a,b). Sua pesquisa pode ser exploratória ou direcionada à avaliação de propriedades específicas, inclusive bancando o adversário (fazer equipe vermelha) no alinhamento do modelo.
- Auditoria externa de modelo, ou seja, avaliação de modelo por um auditor externo independente com o objetivo de fornecer um julgamento — ou contribuir para um julgamento — sobre a segurança de implementar um modelo (ou treinar um novo) (ARC Evals, 2023; Mökander et al., 2023; Raji et al., 2022b). Idealmente, existiria um rico ecossistema de auditores de modelo, fornecendo ampla cobertura em diferentes áreas de risco. (Esse ecossistema está atualmente subdesenvolvido).
3.1. Treinamento responsável
A primeira linha de defesa é evitar modelos de treinamento que tenham capacidades perigosas e desalinhamento suficientes para apresentar um risco extremo. Resultados de avaliação suficientemente preocupantes devem justificar o atraso de uma execução de treinamento agendada ou a pausa de uma existente3.
Antes de um treinamento de fronteira, os desenvolvedores têm a oportunidade de estudar modelos mais fracos que podem fornecer sinais de alerta iniciais. Esses modelos vêm de duas fontes: (1) execuções de treinamento anteriores e (2) modelos experimentais que levam à nova execução de treinamento. Os desenvolvedores devem avaliar esses modelos e tentar prever os resultados da execução do treinamento planejado (veja OpenAI, 2023b). Isso incluiria análise de amplificação (ou “amplificação inversa”), onde o objetivo é encontrar áreas onde a amplificação traz mudanças indesejadas para o modelo (McKenzie et al., 2022). Esses insights podem alimentar uma avaliação de risco de treinamento. Então, durante o treinamento, os pesquisadores poderiam realizar avaliações de risco extremo em intervalos regulares.
O desenvolvedor tem uma variedade de respostas possíveis para lidar com os resultados de avaliação preocupantes:
- Estudar o problema para entender por que surgiu o desalinhamento ou a capacidade perigosa.
- Ajustar os métodos de treinamento para contornar o problema. Isso pode significar ajustar (por exemplo) a arquitetura, os dados, as tarefas de treinamento ou desenvolver ainda mais as técnicas de alinhamento usadas. Esses ajustes devem se direcionar à questão fundamental em vez de induzir mudanças superficiais no modo como o modelo pontua nas avaliações disponíveis (veja a seção 5.2).
- Amplificação cuidadosa. Se o desenvolvedor não estiver confiante de que pode treinar um modelo seguro na escala inicialmente planejada, ele poderia, em vez disso, treinar um modelo menor ou mais fraco.
Em regimes de governança maduros, a decisão de prosseguir com uma execução de treinamento potencialmente arriscada pode requerer a aprovação de um auditor ou regulador externo do modelo.
3.2. Implementação responsável
Implementação significa tornar o modelo disponível para uso: p. ex., é inserido num produto ou hospedado numa interface de programação de aplicações (API) para com o qual desenvolvedores de software construírem. A implementação constitui um grande aumento na exposição do modelo ao mundo externo e, portanto, um possível risco. A avaliação de modelo para riscos extremos pode informar uma avaliação de risco de implementação que analisa (a) se é ou não é o modelo seguro para implementação e (b) as proteções apropriadas para garantir que a implementação seja segura.
O processo de avaliação pré-implementação leva tempo (OpenAI, 2023a; Rismani et al., 2023). As normas ou regulamentos do setor podem exigir uma duração mínima para avaliação pré-implementação de modelos de fronteira, incluindo o período de tempo em que pesquisadores e auditores externos têm acesso.
Em resposta a resultados preocupantes da avaliação, uma possibilidade é recomendar contra a implementação. Uma segunda possibilidade é recomendar ajustes no plano de implementação que lidem com os riscos potenciais (…). No entanto, para um modelo suficientemente capaz e mal alinhado, é possível que mesmo uma implementação restritiva e reduzida possa apresentar um risco extremo.
Uma implementação segura geralmente será um processo gradual (Figura 5) (Brundage et al., 2022). O desenvolvedor gradualmente acumula evidências sobre a segurança do modelo, por meio de uma avaliação (interna e externa) e uma implementação inicial em pequena escala.

A avaliação geralmente precisará continuar após a implementação. Há duas razões para isso:
- Comportamentos inesperados. Antes da implementação, é impossível prever e entender totalmente como o modelo irá interagir num ambiente de implementação complexo (uma limitação importante da avaliação de modelo: veja a seção 5). Por exemplo, os usuários podem encontrar novas aplicações para o modelo ou novas estratégias de engenharia de prompts; ou o modelo pode estar operando num ambiente multiagente dinâmico. Portanto, nos estágios iniciais da implementação, os desenvolvedores devem:
- (a) Trazer à tona comportamentos e riscos emergentes do modelo por meio de esforços de monitoramento. Isso pode incluir o monitoramento direto das entradas e saídas do modelo e sistemas para relatórios de incidentes (ver Brundage et al., 2022; Raji et al., 2022b).
- (b) Projetar e executar novas avaliações de modelo inspiradas nessas observações.
- Atualizações no modelo. O desenvolvedor pode atualizar o modelo após a implementação, p. ex., ajustando os dados coletados durante a implementação ou expandindo o acesso do modelo a ferramentas externas. Se essas atualizações puderem aumentar o risco, elas devem ser avaliadas antes do lançamento. Para grandes mudanças4, o novo modelo pode passar por todo o processo descrito nesta seção.
O estado ideal é a revisão contínua da implementação. De forma contínua, o desenvolvedor reavalia a segurança da implementação usando avaliações e monitoramento do modelo e, a qualquer momento, pode ajustar ou encerrar a implementação em resposta às suas descobertas. Além disso, para implementações que eram reconhecidamente inseguras em retrospecto, uma auditoria externa do processo de tomada de decisão da implementação poderia ser acionada. Os problemas de segurança descobertos durante a implementação também podem informar as avaliações de risco de treinamento para modelos futuros.
Por fim, mesmo implementações internas de modelos de propósito geral altamente capazes, principalmente como assistentes de codificação para pesquisadores e engenheiros de IA, podem exigir avaliação pré-implementação para capacidades perigosas (p. ex., a capacidade de inserir vulnerabilidades sutis no código) e alinhamento.
3.3. Transparência
Avaliações de modelo são uma ferramenta essencial para manter as partes interessadas informadas sobre o estado dos riscos de IA de fronteira (Whittlestone e Clark, 2021). Recomendamos que os desenvolvedores de fronteira considerem processos para relatar externamente os resultados das avaliações ou extratos dos documentos de avaliação que dependem desses resultados da avaliação (como avaliações de risco de treinamento, relatórios de auditores, avaliações de risco de implementação).
As avaliações de modelo revelarão quatro tipos importantes de transparência sobre riscos extremos:
- Relatórios de incidentes, ou seja, um processo estruturado para os desenvolvedores compartilharem resultados de avaliação relevantes ou dignos de nota com outros desenvolvedores, terceiros ou reguladores (veja Brundage et al., 2020). Isso seria essencial para ajudar outras pessoas a evitar o treinamento de sistemas arriscados e para fazer os desenvolvedores de IA prestar contas. No futuro, os reguladores poderão manter listas de abordagens de treinamento de alto risco ou proibidas; um relatório de incidente suficientemente preocupante acionaria uma atualização dessa lista.
- Compartilhamento de avaliações de risco pré-implementação. Antes da implementação, os desenvolvedores podem compartilhar suas avaliações de risco pré-implementação para comentários e críticas. Isso pode significar compartilhar com auditores, pesquisadores externos, reguladores ou publicamente. A avaliação de risco incluiria os resultados da avaliação, juntamente com a justificativa do desenvolvedor de por que a implementação é segura, dados esses resultados. (Veja relacionado: Mitchell et al., 2018).
- Relatórios científicos, ou seja, apresentação dos resultados à comunidade científica de forma a incentivar mais pesquisas científicas sobre o assunto. Muita pesquisa será necessária para entender melhor o comportamento de modelos de propósito geral altamente capazes, especialmente seu alinhamento. Tópicos dentro da literatura de alinhamento, como consciência situacional, poderiam seguir o caminho da pesquisa de justiça, onde as primeiras descobertas de vieses raciais e de gênero em modelos ajudaram a estimular novas áreas de pesquisa.
- Demonstrações educacionais, ou seja, apresentações envolventes de capacidades e comportamentos preocupantes para as principais partes interessadas – como formuladores de políticas, o público ou a liderança empresarial – para mantê-las informadas sobre os riscos dos sistemas de IA de ponta. As demonstrações poderão ser vídeos ou demonstrações interativas, sendo os resultados da avaliação apresentados como informação complementar (como prova do rigor científico).
3.4. Segurança apropriada
Os modelos em risco de exibir capacidades perigosas exigirão controles de segurança fortes e inovadores.
Os desenvolvedores devem considerar vários agentes de ameaças possíveis: internos (p. ex., equipe interna, contratados), externos (p. ex., usuários, agentes de ameaças de Estado-nação) e o próprio modelo como um vetor de dano. Devemos desenvolver novas práticas recomendadas de segurança para desenvolvimento e implementação de IA de alto risco, que podem incluir, por exemplo:
- Equipe vermelha: prática de equipe vermelha de segurança intensiva para toda a infraestrutura na qual o modelo é desenvolvido e implementado.
- Monitoramento: monitoramento intensivo, assistido por IA, do comportamento do modelo, p. ex., para saber se o modelo está praticando comportamentos manipuladores ou fazendo recomendações de código que reduziriam a segurança geral de um sistema.
- Isolamento: técnicas de isolamento apropriadas para impedir que modelos arriscados explorem o sistema subjacente (p. ex., máquinas e conjuntos de locatário individual e outros isolamentos baseados em software). O acesso à rede do modelo deve ser rigidamente controlado e monitorado, assim como seu acesso às ferramentas (p. ex., execução de código).
- Resposta rápida: processos e sistemas de resposta rápida para desabilitar as ações do modelo e as integrações do modelo com hardware, software e infraestrutura em caso de comportamento inseguro inesperado.
- Integridade do sistema: verificação formal de que os modelos, memória ou infraestrutura atendidos não foram adulterados. A infraestrutura de desenvolvimento e serviço deve exigir autorização de duas partes para quaisquer alterações e auditabilidade de todas as alterações.
4. Construindo avaliações para risco extremo
A avaliação de modelo já é um componente central da pesquisa de IA e, cada vez mais, temos avaliações com foco em ética, segurança e impacto social. Recomendamos estender essa caixa de ferramentas para lidar com riscos extremos.
O trabalho inicial já está em andamento para construir avaliações de modelo para riscos extremos. O ARC Evals (a equipe de avaliações do Alignment Research Center) está construindo avaliações que medem as capacidades de autoproliferação dos modelos de linguagem (veja a Tabela 1 acima). O ARC Evals executou essa avaliação no GPT-4 e no Claude antes de seu lançamento mais amplo (ARC Evals, 2023; OpenAI, 2023a). A OpenAI e as equipes vermelhas do GPT-4 também testaram as capacidades do GPT-4 em operações de segurança cibernética e sua capacidade de comprar certos compostos químicos (OpenAI, 2023a).
A Google DeepMind tem projetos em andamento avaliando modelos de linguagem para capacidades de manipulação. Isso inclui um jogo chamado “Faça-me dizer”, em que o modelo de linguagem deve levar um parceiro de conversa humano (alheio ao fato) a dizer uma palavra pré-especificada5.
A Tabela 2 contém uma gama de qualidades desejáveis para avaliações de risco extremo. Algumas dessas qualidades referem-se a uma única avaliação, e algumas são qualidades desejáveis de um portfólio de avaliações.
Prevemos que construir avaliações de alinhamento abrangentes será o mais desafiador. A ambição é de um processo de garantia de alinhamento que possa concluir, com alta confiança, que um modelo não está perigosamente desalinhado, mesmo para modelos muito capazes. (As avaliações de modelo não seriam a única entrada nesse processo de garantia, mas uma entrada importante.)
A avaliação de alinhamento é desafiadora porque precisamos de garantia de que o modelo se comportará de maneira confiável e apropriada em uma ampla diversidade de configurações (Ziegler et al., 2022). Uma avaliação pode descobrir que um modelo está alinhado de alguma maneira restrita e prosaica (p. ex., um agente linguístico afirmando que não se opõe a ser desligado (Perez et al., 2022a,b)) sem fornecer evidências de que o modelo exibiria um comportamento desejável quando recebesse oportunidades genuínas (ou mais convincentes) de alcançar a autopreservação, maior influência ou outros resultados prejudiciais.
| Abrangentes: | |
| Modelos de ameaças | O portfólio de avaliação deve abranger o maior número possível de modelos plausíveis de ameaças de risco extremo. |
| Automatizadas e assistidas por humanos | Muitas avaliações podem ser executadas automaticamente, reduzindo o tempo e os custos de recursos. No entanto, algumas capacidades e comportamentos precisarão de avaliações assistidas por humanos, ou seja, envolvendo: (a) avaliadores humanos que julgam os resultados do modelo; ou (b) humanos que interagem com o modelo, p. ex., num ambiente de diálogo. |
| Comportamental e mecanicista | As avaliações não devem ser restringidas ao estudo do comportamento de um modelo, mas também devem acabar envolvendo a observação do mecanismo de como o modelo produziu esse comportamento. |
| Detecção de avarias | O portfólio de avaliações deve incluir testes adversários, onde os pesquisadores propositadamente buscam casos em que o modelo produz resultados preocupantes. |
| Resilientes ao engano | Em última análise, os pesquisadores precisarão de avaliações que possam descartar a possibilidade de que o modelo deliberadamente pareça seguro com o objetivo de passar no processo de avaliação. |
| Revelando capacidades latentes | Os pesquisadores precisarão trazer à tona capacidades latentes (p. ex., por meio de engenharia de prompts ou ajuste fino). |
| Ciclo de vida do modelo | Recomendamos conduzir avaliações ao longo do processo de desenvolvimento do modelo. Em particular, os resultados do final de um longo processo de desenvolvimento provavelmente não transmitirão informações relevantes sobre o modelo básico, especialmente se ele tiver passado por ajuste fino para segurança. |
| Nível de modelo e nível de sistema | Os modelos geralmente são integrados a sistemas de IA mais amplos, p. ex., com ferramentas externas, outros modelos ou classificadores que filtram as saídas do modelo. As avaliações devem estudar modelos com e sem esses aprimoramentos. |
| Interpretáveis: | |
| Legíveis | Algumas avaliações devem apresentar os riscos de forma acessível, exigindo pouco conhecimento técnico. Isso será útil para criar conhecimento comum sobre os riscos da IA. |
| Amplo espectro de dificuldade | As avaliações de capacidades perigosas devem, idealmente, conter amplas faixas de dificuldade – idealmente dentro de avaliações únicas, mas pelo menos perpassando o portfólio. Isso significa que os pesquisadores podem acompanhar o progresso das capacidades conforme se aproximam de possíveis limites de perigo e que a avaliação (ou o portfólio) é amplificável para modelos futuros mais capazes. Para acompanhar o progresso, as avaliações forneceriam idealmente uma pontuação quantitativa, embora isso nem sempre seja prático. |
| Seguras: | |
| Seguras para implementar | Avaliações de capacidade perigosas podem envolver o teste do modelo em ambientes do mundo real , p. ex., interagindo com trabalhadores de crowdsourcing. Isso não deve introduzir níveis inaceitáveis de risco. |
Os pesquisadores devem, portanto, avaliar um modelo em uma ampla gama de configurações. Pode-se ajudar a alcançar a cobertura de configurações para avaliação de alinhamento por meio de:
- Amplitude: avaliar o comportamento em uma gama de configurações tão ampla quanto possível. Um caminho promissor é automatizar o processo de escrever avaliações usando sistemas de IA (Perez et al., 2022b) (ver também Pan et al.,2023).
- Segmentação: algumas configurações são muito mais propensas a revelar falhas de alinhamento do que outras, e podemos nos concentrar nelas por meio de um design astuto — por exemplo, usando potes de mel ou testes adversários baseados em gradientes e abordagens relacionadas (Jones et al., 2023).
- Compreensão da generalização: visto que os pesquisadores serão incapazes de prever ou simular todos os cenários possíveis, devemos desenvolver uma melhor compreensão científica de como e por que os comportamentos do modelo se generalizam (ou falham nisso) entre as configurações.
Outra ferramenta importante é a análise mecanicista, ou seja, estudar os pesos e ativações do modelo para entender como ele funciona (Nanda et al., 2023; Olah et al., 2020). Por exemplo, uma ambição é estudar como os objetivos do modelo são representados internamente, para ajudar a verificar se eles são como o pretendido; outra ambição é detectar quando as saídas de um modelo de linguagem relatam incorretamente seu conhecimento (Burns et al., 2022), o que pode ser um indicador de comportamento enganoso.
Finalmente, a agência – em particular, a direção a um objetivo mostrada por um sistema de IA – é uma propriedade importante para avaliar (Kenton et al., 2022), dado o papel central da agência em várias teorias de risco de IA (Chan et al., 2023 ). Em parte, a agência é uma questão das capacidades do modelo – ele é capaz de buscar objetivos de forma eficaz? Avaliar o alinhamento também requer olhar para a agência, incluindo: (a) o modelo é mais direcionado a objetivos do que o desenvolvedor pretendia? Por exemplo, um agente de diálogo aprendeu o objetivo de manipular o comportamento do usuário? (b) O modelo resiste à tentativa do usuário de montá-lo como um sistema autônomo de IA (p. ex., o Auto-GPT) com objetivos nocivos?
5. Limitações e perigos
5.1. Limitações
A avaliação de modelo, como ferramenta para lidar com riscos extremos, tem pelo menos cinco limitações. Um problema crucial é que nem todos os riscos podem necessariamente ser detectados por meio da avaliação de modelo.
- Fatores além do sistema de IA. Os riscos dependerão de como um sistema de IA interage com um mundo complexo. Por exemplo, um modelo pode usar, como ferramentas, outros modelos lançados no futuro, aumentando assim suas capacidades; ou a civilização humana pode ser menos resiliente a uma IA poderosa do que o previsto.
- Modelos de ameaças desconhecidas. É difícil prever todos os diferentes caminhos plausíveis para o risco extremo. Isso será especialmente verdadeiro para modelos altamente capazes, que podem encontrar estratégias criativas para atingir seus objetivos.
- Propriedades difíceis de identificar. Algumas propriedades do modelo serão difíceis de descobrir por meio de avaliações de modelo. Dois casos importantes:
(a) Excesso de capacidade: os modelos às vezes têm capacidades que a comunidade de pesquisa de IA não percebe. Por exemplo, depois que o GPT-3 já existia há muitos meses, os pesquisadores demonstraram que pedidos em cadeia de pensamento podem aumentar significativamente o desempenho. (Wei et al., 2022c).
(b) Alinhamento enganoso: um modelo consciente da situação pode exibir deliberadamente o comportamento desejado durante a avaliação (Ngo et al., 2022). (Essa é uma razão para não confiar apenas em avaliações comportamentais). - Emergência. Acima, recomendamos o uso de avaliações de modelo para informar a decisão de treinar um novo modelo, realizando análises de leis de amplificação em modelos menores. No entanto, às vezes, capacidades específicas emergirão apenas em maior escala, o que torna essa análise muito mais difícil (Ganguli et al., 2022); outras capacidades exibem amplificação em forma de U (Wei et al., 2022a).
- Maturidade do ecossistema de avaliação. O ecossistema para avaliações e auditorias de modelos externas está atualmente subdesenvolvido.
- Excesso de confiança nas avaliações. Existe o risco de que se deposite muita fé nos resultados das avaliações, levando a que modelos arriscados sejam implementados com uma falsa sensação de segurança.
A avaliação de modelo é uma estratégia necessária, mas não suficiente, para identificar e mitigar riscos extremos. Deve ser combinada com uma dedicação organizacional à segurança mais ampla e outras ferramentas para identificação e avaliação de riscos.
5.2. Perigos
Conduzir e relatar as avaliações discutidas neste documento apresenta quatro perigos potenciais:
1. Avanço e proliferação de capacidades perigosas. Existe o risco de que – por meio da realização de avaliações de capacidades perigosas e do compartilhamento de materiais relevantes – o campo prolifere capacidades perigosas ou acelere seu desenvolvimento. Destacamos quatro tipos de informações potencialmente perigosas:
- (a) Resultados. Os resultados da avaliação podem demonstrar novas tecnologias ofensivas. O compartilhamento público desses resultados pode estimular o investimento em novos programas de armamentos, esforços ofensivos cibernéticos ou métodos de opressão digital dos cidadãos. Por analogia, já foi dito que na década de 1940 o segredo mais valioso sobre a bomba nuclear era que ela era possível (Ord, 2022). Desenvolvedores, pesquisadores e auditores de IA devem, portanto, ter cuidado ao compartilhar esses resultados de avaliação.
- (b) Conjuntos de dados de avaliação. Conjuntos de dados para avaliar capacidades perigosas são de uso duplo porque outros atores poderiam fazer ajuste fino nos seus modelos com esses conjuntos de dados.
- (c) Técnicas de elicitação. A avaliação de capacidades perigosas geralmente envolve extrair essas capacidades do modelo. Isso pode envolver: (a) engenharia de prompts; e (b) ajuste fino, incluindo: (i) encontrar novas especificações de tarefas criativas; (ii) criar ou identificar conjuntos de dados para ajuste fino apropriados. Essas técnicas podem ser úteis para um agente mal-intencionado tentando extrair capacidades perigosos de modelos semelhantes. Pesquisadores e auditores devem, portanto, ter cuidado ao compartilhar suas técnicas de elicitação, especialmente se produzi-las com base na criatividade, conhecimento especializado ou experimentação demorada.
- (d) Modelos treinados. Existem riscos de treinar intencionalmente modelos perigosamente capazes, mesmo para uso como artefatos de pesquisa de segurança. Poderíamos distinguir entre (a) simplesmente seguir métodos disponíveis no mercado (por exemplo, ajustar um modelo existente) e (b) casos em que o trabalho para produzir a capacidade perigosa poderia constituir uma contribuição de pesquisa por si só (p. ex., poderia ser aceito em uma conferência acadêmica). Estes últimos casos são indiscutivelmente comparáveis à pesquisa de “ganho de função” [definição] em virologia, especialmente se o modelo resultante for altamente capaz e de propósito geral. A pesquisa pode precisar ser conduzida em condições de segurança muito alta e sujeita a uma avaliação de risco exigente.
2. Pressões competitivas. Uma preocupação é que compartilhar os resultados da avaliação entre desenvolvedores de IA concorrentes possa incentivá-los a se comportar de maneira menos responsável. Por exemplo, compartilhar os resultados da avaliação pré-implementação pode alertar os concorrentes sobre futuras melhorias de produtos, incentivando esses concorrentes a apressar suas próprias implementações e gastar menos tempo garantindo a segurança. Da mesma forma, uma vez que resultados de capacidade perigosa geralmente se correlacionam com as capacidades gerais do modelo, os desenvolvedores concorrentes podem descobrir que estão ficando para trás e decidir que precisam sacrificar a segurança para recuperar o atraso (Emery-Xu et al., 2023).
Dadas as sensibilidades envolvidas, uma opção é apoiar-se mais fortemente nos resultados da avaliação de alinhamento, pelo menos para relatórios entre os desenvolvedores. Para uma ilustração, uma possível diretriz entre desenvolvedores poderia ser:
- (a) Relate problemas de alinhamento inesperados ou importantes imediatamente a outros desenvolvedores. Por padrão, limite a descrição do treinamento do modelo a apenas uma visão geral abstrata (para evitar revelar informações confidenciais); mas compartilhe mais detalhes se isso for absolutamente necessário – em particular, se uma determinada classe de métodos estiver causando o problema.
- (b) Informe quando certos limites de capacidade perigosa tiverem sido ultrapassados. Esses limites podem ser altos para evitar o compartilhamento de informações detalhadas. Aguarde até a implementação para compartilhar mais.
3. Melhorias superficiais na segurança do modelo. Existe o risco de que avaliações de segurança amplamente disponíveis levem a modelos que exibem comportamentos apenas superficialmente desejáveis. Mais claramente, se os pesquisadores treinarem diretamente os modelos para serem aprovados nessas avaliações, as avaliações não poderão mais atuar como um indicador de risco. Os pesquisadores podem fazer isso acidentalmente (p. ex., porque os conjuntos de dados de avaliação são compartilhados on-line e, portanto, acabam no conjunto de dados pré-treinamento) ou como uma tentativa intencional de passar por auditorias externas (algo análogo ao escândalo das emissões da Volkswagen). O desempenho de avaliação desejável do modelo provavelmente não se generalizaria. Desenvolvedores e auditores de modelos podem, portanto, considerar manter algumas avaliações “retidas” privadas e garantir que elas não coincidam demais com conjuntos de dados ou tarefas usadas durante o treinamento.
Mesmo que os desenvolvedores se abstenham de treinar diretamente nas avaliações, recomendamos que os desenvolvedores evitem modelos de treinamento que falham nas avaliações (seção 3.1). Isso também poderia exercer pressão de seleção, embora mais fraca. A longo prazo, o risco é que o campo selecione métodos de treinamento que produzam modelos enganosamente alinhados.
4. Danos durante a avaliação. A execução de avaliações geralmente envolve a exposição do modelo ao mundo externo. Por exemplo, ao avaliar o GPT-4, a ARC usou o modelo para gerar mensagens (enganosas) a serem enviadas a um trabalhador da TaskRabbit (OpenAI, 2023a). No caso extremo, um teste mal gerenciado para saber se um modelo tem capacidades de autoproliferação pode terminar numa proliferação real; mas, de maneira mais prosaica, pode causar danos de outras maneiras, como causar sofrimento emocional a trabalhadores crowdsourcing. Portanto, grupos que realizam avaliações, como auditores, devem estabelecer protocolos de segurança quando necessário.
6. Conclusão
A avaliação de modelo para riscos extremos deve ser uma área prioritária para a segurança e a governança da IA. Há muitos desafios pela frente para encontrar avaliações eficazes e construir regimes de governança que os incorporem; incentivamos mais trabalhos nessa área. A avaliação de modelo não é uma panaceia: ela não abrangerá todos os riscos extremos. No entanto, é um componente necessário da infraestrutura de governança necessária para combater riscos extremos.
Os desenvolvedores de IA de fronteira atualmente têm uma responsabilidade especial de apoiar o trabalho em avaliações de modelo para riscos extremos, uma vez que possuem recursos – incluindo acesso a modelos de IA de ponta e profundo conhecimento técnico – que muitos outros atores normalmente não possuem. Os desenvolvedores de IA de fronteira também são atualmente os atores com maior probabilidade de desenvolver ou liberar involuntariamente sistemas de IA que apresentam riscos extremos. Os desenvolvedores de IA de fronteira devem, portanto:
- Investir em pesquisa: desenvolvedores de fronteira devem dedicar recursos a pesquisa e desenvolvimento de avaliações de modelo para riscos extremos.
- Elaborar políticas internas: desenvolvedores de fronteira devem elaborar políticas internas para conduzir, relatar e responder adequadamente aos resultados das avaliações de risco extremo.
- Apoiar o trabalho externo: laboratórios de fronteira devem permitir pesquisas externas sobre avaliações de risco extremo por meio de acesso ao modelo e outras formas de apoio.
- Educar os formuladores de políticas: desenvolvedores de fronteira devem educar os formuladores de políticas e participar de discussões de definição de normas, para aumentar a capacidade do governo de elaborar quaisquer regulamentações que possam acabar sendo necessárias para reduzir riscos extremos.
Os formuladores de políticas devem considerar a construção da infraestrutura de governança descrita na seção 3. Eles poderiam:
- Rastrear sistematicamente o desenvolvimento de capacidades perigosas e o progresso no alinhamento dentro da pesquisa e desenvolvimento de IA de fronteira (Whittlestone e Clark, 2021). Os formuladores de políticas poderiam estabelecer um processo formal de relatórios para avaliações de risco extremo.
- Investir no ecossistema para avaliação de segurança externa e criar espaços para as partes interessadas (como desenvolvedores de IA, pesquisadores acadêmicos e representantes do governo) se reunirem e discutirem essas avaliações (Anthropic, 2023).
- Tornar mandatórias auditorias externas, incluindo auditorias de modelo e auditorias de avaliações de risco dos desenvolvedores, para sistemas de IA de propósito geral altamente capazes.
- Incorporar avaliações de risco extremo na regulamentação da implementação de IA, esclarecendo que modelos que representam riscos extremos não devem ser implementados.
7. Agradecimentos
Agradecemos pelos comentários e discussões úteis sobre este trabalho de: Canfer Akbulut, Jide Alaga, Beth Barnes, Joslyn Barnhart, Sasha Brown, Miles Brundage, Martin Chadwick, Tom Everitt, Conor Griffin, Eric Horvitz, Evan Hubinger, William Isaac, Victoria Krakovna, Leonie Koessler, Sébastien Krier, Nikhil Mulani, Neel Nanda, Jonas Schuett, Rohin Shah, Andrew Trask, Gregory Wayne e Hjalmar Wijk. Agradecemos pelas discussões perspicazes com os participantes de dois eventos realizados em fevereiro de 2023: uma sessão de discussão virtual sobre o tema deste artigo e um workshop de um dia sobre avaliações de capacidades perigosas coorganizado por Steven Adler, Anne le Roux e Jade Leung. Agradecemos também a Celine Smith pelo suporte ao gerenciamento do projeto e a Michael Chang pelas melhorias nas visualizações.
Veja o artigo original para as referências.
Notas
1. Na prática, definir “capacidades médias” envolveria muitos julgamentos sobre quais avaliações deveriam ser incluídas e como deveriam ser ponderadas.
2. Isso é especialmente pertinente para riscos extremos: causar danos em grande escala normalmente não é um desafio fácil. Até grupos terroristas com bons recursos, determinados a causar danos extremos, geralmente falham.
3. Os desenvolvedores que treinam modelos de propósito geral altamente capazes devem se acostumar com essa perspectiva, não planejando sua pesquisa com base na suposição de que uma execução de treinamento será executada conforme o cronograma. Por exemplo, desenvolvedores bem administrados terão sistemas de alocação de computação que preenchem os recursos de computação vagos com outros projetos úteis. Da mesma forma, os desenvolvedores devem evitar fazer promessas fortes às partes interessadas (por exemplo, clientes, investidores) de que implementarão um determinado modelo em uma determinada data. No mínimo, eles devem manter a flexibilidade de mudar para uma versão menor ou menos arriscada do modelo.
4. A magnitude da mudança no modelo pode ser avaliada em termos da quantidade de treinamento adicional pela qual ele passou (como uma porcentagem da duração do treinamento original) ou a melhoria do modelo nos principais parâmetros de desempenho.
5. Este projeto é liderado por Mary Phuong.
Publicado originalmente aqui.
Autores:
Toby Shevlane 1, Sebastian Farquhar 1, Ben Garfinkel 2, Mary Phuong 1, Jess Whittlestone 3, Jade Leung 4, Daniel Kokotajlo 4, Nahema Marchal 1, Markus Anderljung 2, Noam Kolt 5, Lewis Ho 1, Divya Siddarth 6, 7, Shahar Avin 8, Will Hawkins 1, Been Kim 1, Iason Gabriel 1, Vijay Bolina 1, Jack Clark 9, Yoshua Bengio 10, 11, Paul Christiano 12 and Allan Dafoe 1.
Trabalham nas seguintes organizações:
1 Google DeepMind, 2 Centre for the Governance of AI, 3 Centre for Long-Term Resilience, 4 OpenAI, 5 University of Toronto, 6 University of Oxford, 7 Collective Intelligence Project, 8 University of Cambridge, 9 Anthropic, 10 Université de Montréal, 11 Mila–Quebec AI Institute, 12 Alignment Research Center.
Tradução: Luan Marques e Fernando Moreno.