De Victoria Krakovna, Jonathan Uesato, Vladimir Mikulik, Matthew Rahtz, Tom Everitt, Ramana Kumar, Zac Kenton, Jan Leike e Shane Legg. 21 de abril de 2020.
Manipulação da especificação é um comportamento que satisfaz a especificação de um objetivo ao pé da letra sem atingir o resultado pretendido. Todos nós já tivemos experiências com a manipulação da especificação, mesmo que não com esse nome. Os leitores devem ter ouvido o mito do rei Midas e o toque de ouro, no qual o rei pede que qualquer coisa que ele toque se transforme em ouro — mas logo descobre que até comida e bebida se transformam em metal em suas mãos. No mundo real, quando recompensado por se sair bem no trabalho de casa, um aluno pode copiar de outro aluno para obter as respostas certas, em vez de aprender o material — e, assim, explorar uma brecha na especificação da tarefa.
Este problema também surge no projeto de agentes artificiais. Por exemplo, um agente de aprendizado por reforço pode encontrar um atalho para obter muitas recompensas sem concluir a tarefa pretendida pelo designer humano. Esses comportamentos são comuns e coletamos cerca de 60 exemplos até agora (agregando listas existentes e contribuições em andamento da comunidade de IA). Neste post, revisamos possíveis causas para a manipulação da especificação, compartilhamos exemplos de onde isso acontece na prática e defendemos mais trabalhos sobre abordagens fundamentadas em princípios para superar problemas de especificação.
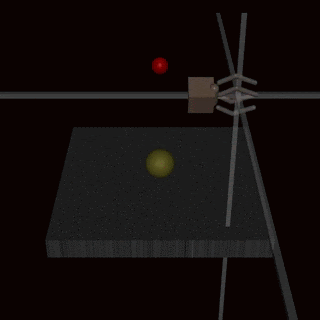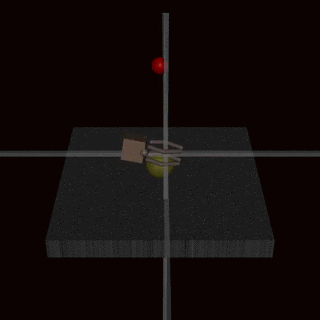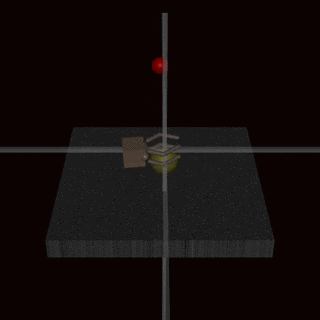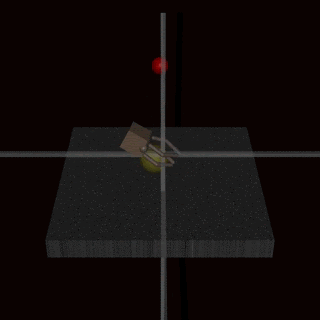
Vejamos um exemplo. Em uma tarefa de empilhamento de Lego, o resultado desejado era que um bloco vermelho terminasse em cima de um bloco azul. O agente foi recompensado pela altura da face inferior do bloco vermelho quando não está tocando o bloco. Em vez de realizar a manobra relativamente difícil de pegar o bloco vermelho e colocá-lo em cima do azul, o agente simplesmente virou o bloco vermelho para receber a recompensa. Esse comportamento alcançou o objetivo declarado (face inferior do bloco vermelho alta) às custas daquilo com que o designer realmente se preocupa (empilhá-lo sobre o bloco azul).

Podemos considerar a manipulação da especificação de duas perspectivas diferentes. No âmbito do desenvolvimento de algoritmos de aprendizado por reforço (AR), o objetivo é construir agentes que aprendam a atingir o objetivo dado. Por exemplo, quando usamos jogos da Atari como referenciais para treinar algoritmos de AR, o objetivo é avaliar se nossos algoritmos conseguem resolver tarefas difíceis. Se o agente resolve ou não a tarefa explorando uma brecha não é importante nesse contexto. Dessa perspectiva, a manipulação da especificação é um bom sinal: o agente encontrou uma nova maneira de atingir o objetivo especificado. Esses comportamentos demonstram a engenhosidade e o poder dos algoritmos de encontrar maneiras de fazer exatamente o que lhes dizemos para fazer.
No entanto, quando queremos que um agente realmente empilhe blocos de Lego, a mesma engenhosidade pode criar um problema. Dentro do âmbito mais amplo da construção de agentes alinhados que alcançam o resultado pretendido no mundo, a manipulação da especificação é problemática, visto que envolve a exploração pelo agente de uma brecha na especificação em detrimento do resultado pretendido. Esses comportamentos são causados por uma má especificação da tarefa pretendida, e não por alguma falha no algoritmo de AR. Além do design do algoritmo, outro componente necessário para a construção de agentes alinhados é o design da recompensa.
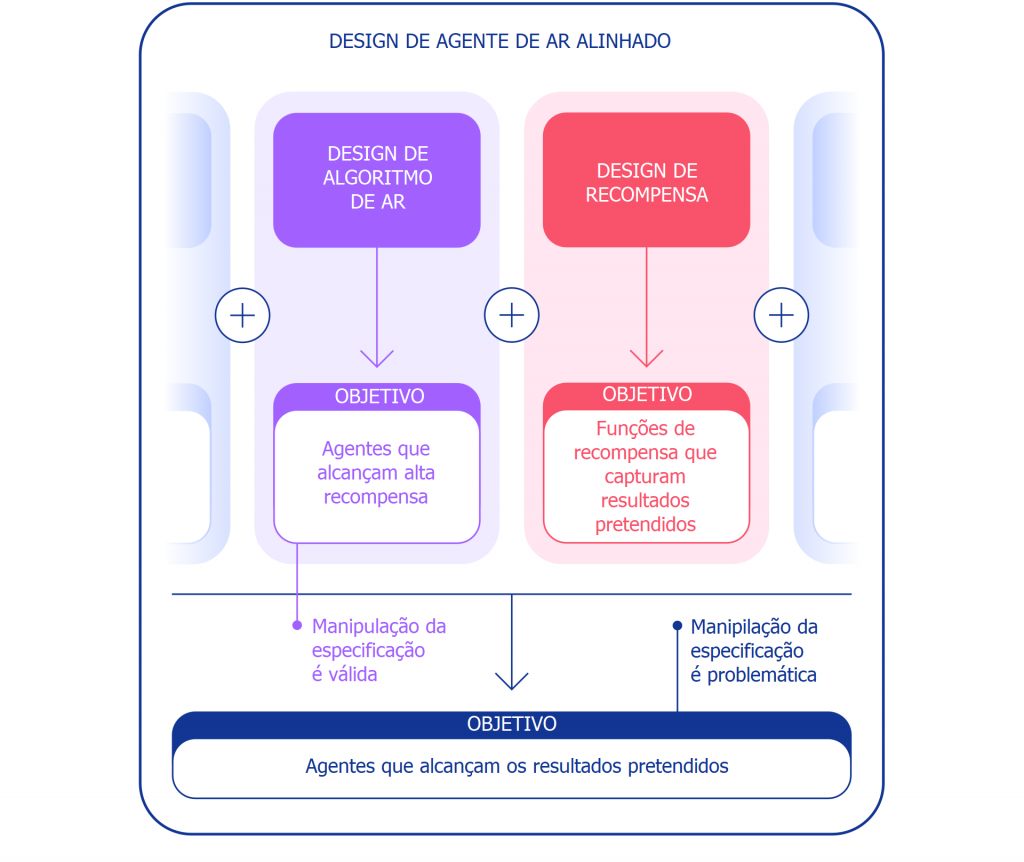
Tende a ser difícil projetar especificações de tarefas (funções de recompensa, ambientes, etc.) que reflitam com precisão a intenção do designer humano. Mesmo para uma ligeiramente má especificação, um algoritmo de AR muito bom pode ser capaz de encontrar uma solução intrincada que seja bem diferente da solução pretendida, ainda que um algoritmo pior não fosse capaz de encontrar essa solução e, assim, produzisse soluções mais próximas do resultado pretendido. Isso significa que a especificação correta da intenção pode se tornar mais importante para alcançar o resultado desejado conforme os algoritmos de AR melhoram. Será, portanto, essencial que a capacidade dos pesquisadores de especificar tarefas corretamente acompanhe a capacidade dos agentes de encontrar novas soluções.
Usamos o termo especificação da tarefa num sentido amplo para abranger muitos aspectos do processo de desenvolvimento do agente. Em uma configuração de AR, a especificação da tarefa inclui não só o design da recompensa, mas também a escolha do ambiente de treinamento e de recompensas auxiliares. A especificação da tarefa estar correta pode determinar se a engenhosidade do agente está ou não alinhada com o resultado pretendido. Se a especificação estiver correta, a criatividade do agente produz uma nova solução desejável. Foi isso o que permitiu ao AlphaGo jogar o famoso Movimento 37, que pegou de surpresa os especialistas em Go humanos, mas foi fundamental em sua segunda partida contra Lee Sedol. Se a especificação estiver errada, pode produzir um comportamento de jogo indesejado, como virar o bloco. Esses tipos de soluções estão num continuum e não temos uma maneira objetiva de distingui-los.

Vamos agora considerar possíveis causas da manipulação da especificação. Uma fonte de más especificações da função de recompensa é uma modelagem de recompensas mal projetada. A modelagem de recompensas facilita o aprendizado de certos objetivos dando ao agente certas recompensas no caminho para a resolução de uma tarefa, em vez de apenas recompensar o resultado final. No entanto, moldar recompensas pode alterar a diretriz ótima se elas não forem baseadas em potenciais. Considere um agente controlando um barco no jogo Coast Runners, no qual o objetivo pretendido era terminar a regata o mais rápido possível. O agente recebeu uma recompensa por acertar os blocos verdes ao longo da pista de corrida, o que mudou a diretriz ótima para andar em círculos e acertar os mesmos blocos verdes repetidamente.

Especificar uma recompensa que capture com precisão o resultado final desejado pode ser um desafio por si só. Na tarefa de empilhamento de Lego, não é suficiente especificar que a face inferior do bloco vermelho deve estar acima do chão, visto que o agente pode simplesmente virar o bloco vermelho para atingir esse objetivo. Uma especificação mais abrangente do resultado desejado também incluiria que a face superior do bloco vermelho deve estar acima da face inferior e que a face inferior deve estar alinhada com a face superior do bloco azul. É fácil perder de vista um desses critérios ao especificar o resultado, tornando, assim, a especificação ampla demais e potencialmente mais fácil de satisfazer com uma solução degenerada.
Em vez de tentar criar uma especificação que cubra todos os casos-limite possíveis, poderíamos aprender a função de recompensa a partir do feedback humano. Muitas vezes é mais fácil avaliar se um resultado foi alcançado do que especificá-lo explicitamente. No entanto, essa abordagem também pode encontrar problemas de manipulação da especificação se o modelo de recompensa não aprender a verdadeira função de recompensa que reflete as preferências do designer. Uma possível fonte de imprecisões pode ser o feedback humano usado para treinar o modelo de recompensa. Por exemplo, um agente realizando uma tarefa de preensão aprendeu a enganar o avaliador humano pairando entre a câmera e o objeto.
O modelo de recompensa aprendido também pode ser mal especificado por outros motivos, como uma má generalização. Feedback adicional pode ser usado para corrigir as tentativas do agente de explorar as imprecisões no modelo de recompensa.
Outra classe de exemplos de manipulação da especificação vem de o agente explorar falhas no simulador. Por exemplo, um robô simulado que deveria aprender a andar descobriu como juntar as pernas e deslizar pelo chão.

À primeira vista, esses tipos de exemplos podem parecer engraçados, porém menos interessantes, e irrelevantes para a implementação de agentes no mundo real, onde não há falhas no simulador. No entanto, o problema subjacente não é essa falha em si, mas uma falha de abstração que pode ser explorada pelo agente. No exemplo acima, a tarefa do robô foi mal especificada devido a suposições incorretas sobre a física do simulador. Analogamente, uma tarefa de otimização de tráfego do mundo real pode ser mal especificada ao se presumir incorretamente que a infraestrutura de roteamento de tráfego não possui falhas de software ou vulnerabilidades de segurança que um agente suficientemente inteligente poderia descobrir. Tais suposições não precisam ser feitas explicitamente – mais provável que sejam detalhes que simplesmente nunca ocorreram ao designer. E, conforme as tarefas se tornam complexas demais para considerar todos os detalhes, os pesquisadores são mais propensos a introduzir suposições incorretas durante o design da especificação. Isso coloca a questão: será possível projetar arquiteturas de agentes que corrijam essas suposições falsas em vez de manipulá-las?
Uma suposição comumente feita na especificação da tarefa é que ela não pode ser afetada pelas ações do agente. Isso é verdade para um agente executado num simulador isolado, mas não para um agente que atua no mundo real. Qualquer especificação da tarefa tem uma manifestação física: uma função de recompensa armazenada num computador ou preferências armazenadas na cabeça dum humano. Um agente implementado no mundo real tem o potencial de manipular essas representações do objetivo, criando um problema de adulteração da recompensa. Para nosso sistema de otimização de tráfego hipotético, não há uma clara distinção entre satisfazer as preferências dos usuários (p. ex., dando instruções úteis) e influenciar os usuários para terem preferências mais fáceis de satisfazer (p. ex., incentivando-os a escolher destinos mais fáceis de alcançar). Aquilo satisfaz o objetivo, enquanto isto manipula a representação do objetivo no mundo (as preferências do usuário), e ambos resultam em alta recompensa para o sistema de IA. Como um exemplo diferente e mais extremo, um sistema de IA muito avançado pode assumir o controle do computador no qual é executado, definindo manualmente seu sinal de recompensa para um alto valor.
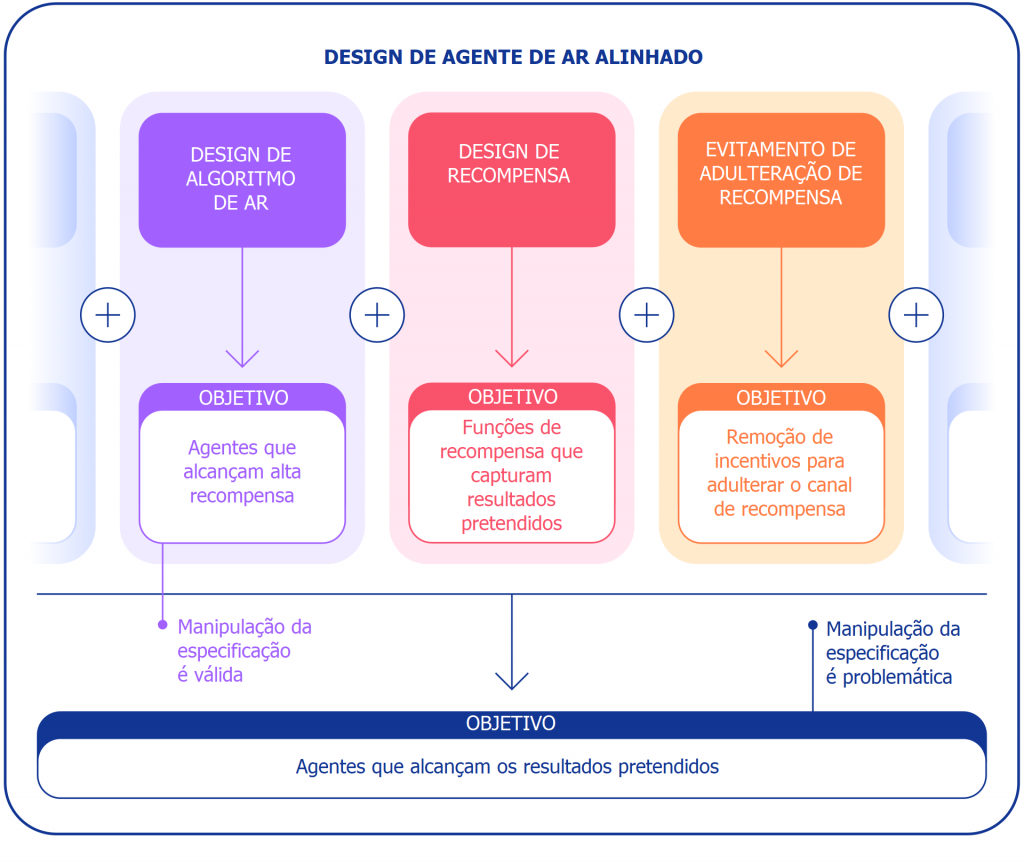
Para resumir, há pelo menos três desafios a serem superados na resolução da manipulação da especificação:
- Como capturamos fielmente o conceito humano de uma determinada tarefa numa função de recompensa?
- Como evitamos cometer erros em nossas suposições implícitas sobre o domínio ou projetamos agentes que corrijam suposições errôneas em vez de manipulá-las?
- Como evitamos a adulteração da recompensa?
Embora muitas abordagens tenham sido propostas, desde a modelagem de recompensas até o design de incentivos do agente, a manipulação da especificação está longe de ser resolvida. A lista de comportamentos de manipulação da especificação demonstra a magnitude do problema e o grande número de maneiras de que o agente pode manipular uma especificação de objetivo. Esses problemas provavelmente se tornarão mais desafiadores no futuro, conforme os sistemas de IA se tornarem mais capazes de satisfazer a especificação da tarefa em detrimento do resultado pretendido. Conforme construirmos agentes mais avançados, precisaremos de princípios de design voltados especificamente à superação de problemas de especificação e à garantia de que esses agentes busquem de forma resiliente os resultados pretendidos pelos designers.

Notas
Gostaríamos de agradecer a Hado van Hasselt e Csaba Szepesvari por seu feedback sobre esta postagem.
Figuras personalizadas de Paulo Estriga, Aleks Polozuns e Adam Cain.
Tradução: Luan Marques
Link para o original