De Stephen Casper, Dylan Hadfield-Menell, Gabriel Kreiman. 11 de setembro de 2023.
Índice
Resumo
A literatura sobre ataques adversários em visão computacional geralmente se concentra em perturbações ao nível dos pixels. Elas tendem a ser muito difíceis de interpretar. Trabalhos recentes que manipulam as representações latentes dos geradores de imagens para criar perturbações adversárias “ao nível das características” nos dão a oportunidade de explorar ataques adversários perceptíveis e interpretáveis. Fazemos três contribuições. Primeiro, observamos que os ataques ao nível das características fornecem classes úteis de entradas para estudar representações em modelos. Segundo, mostramos que esses adversários são excepcionalmente versáteis e altamente resilientes. Demonstramos que eles podem ser usados para produzir ataques direcionados, universais, disfarçados, fisicamente realizáveis e de caixa-preta à escala do ImageNet. Terceiro, mostramos como essas imagens adversárias podem ser usadas como uma ferramenta prática de interpretabilidade para identificar falhas em redes. Usamos esses adversários para fazer previsões sobre associações espúrias entre características e classes, as quais testamos projetando ataques de “copiar/colar” nos quais uma imagem natural é colada em outra para causar uma classificação equivocada direcionada. Nossos resultados sugerem que os ataques ao nível das características são uma abordagem promissora para pesquisas de interpretabilidade rigorosas. Eles apoiam o design de ferramentas para entender melhor o que um modelo aprendeu e diagnosticar associações frágeis entre características.1
1. Introdução
As redes neurais de última geração são vulneráveis a exemplos adversários. Convencionalmente, entradas adversárias para classificadores visuais assumem a forma de perturbações de pequena norma em imagens naturais. Essas perturbações causam classificações erradas confiantes. No entanto, para um humano, elas geralmente aparecem como ruído aleatório ou levemente texturizado. Consequentemente, é difícil interpretar esses ataques: eles raramente produzem insights compreensíveis para humanos sobre a rede-alvo. Em outras palavras, além da observação de que tais ataques são possíveis, é difícil aprender muito sobre a rede-alvo subjacente a partir dessas perturbações ao nível dos pixels.
Em contraste, muitas falhas do mundo real da visão biológica são causadas por características perceptíveis e descritíveis por humanos. Por exemplo, os predadores da borboleta ringlet são surpreendidos por “manchas oculares” adversárias em suas asas (Apêndice A.1, Fig. 7). Isso está fora do escopo dos exemplos adversários convencionais, pois a classificação errada resulta de uma mudança ao nível das características em um objeto/imagem. As manchas oculares adversárias são resilientes no sentido em que o mesmo ataque funciona em uma variedade de observadores diferentes, fundos e condições de visualização. Além disso, como o ataque depende de características de alto nível, é fácil para um humano descrevê-lo.

Este trabalho se inspira nas manchas oculares da borboleta ringlet e em exemplos semelhantes nos quais um modelo é enganado no mundo real por uma característica interpretável (p. ex., [46]). Nosso objetivo é projetar adversários que revelem fraquezas facilmente compreensíveis da rede-vítima. Concentramo-nos em dois desideratos para as perturbações adversárias: os ataques devem ser (1) interpretáveis (ou seja, descritíveis) para um humano e (2) resilientes para que as interpretações se generalizem. Chamamos esses tipos de ataques de exemplos adversários “ao nível das características”. Vários trabalhos anteriores criaram ataques perturbando as representações latentes de um gerador de imagens (p. ex., [24]), mas até agora, as abordagens têm sido pequenas em escala, limitadas em resiliência e não orientadas para interpretabilidade.
Construímos com base nesse trabalho anterior para propor um método de ataque que gera ataques ao nível das características contra modelos de visão computacional. Este método funciona em modelos à escala do ImageNet e cria exemplos adversários resilientes ao nível das características. Testamos três métodos de introduzir características adversárias em imagens de origem, modificando as representações latentes do gerador e/ou inserindo um patch gerado em imagens naturais. Ao contrário de trabalhos anteriores que aplicaram a “adversaridade” dos ataques apenas inserindo pequenas características ou restringindo a distância entre um adversário e uma entrada benigna, também introduzimos métodos que regularizam a característica para ser perceptível, mas disfarçada para se assemelhar a algo diferente da classe-alvo.
Mostramos que nosso método produz ataques resilientes que fornecem insights acionáveis sobre as representações aprendidas por uma rede. A Figura 1 demonstra os benefícios de interpretabilidade desse tipo de ataque ao nível das características. Compara um patch adversário convencional, ao nível dos pixels, criado usando o método de [6], com um ataque ao nível das características usando nosso método. Enquanto ambos os ataques tentam fazer com que uma rede classifique erroneamente uma abelha como uma mosca, o ataque ao nível dos pixels exibe padrões de alta frequência e carece de objetos visualmente coerentes. Por outro lado, o ataque ao nível das características exibe características facilmente descritíveis: os círculos coloridos. Podemos validar esse insight considerando o desempenho da rede quando uma imagem de um semáforo é inserida na imagem de uma abelha. Nesse exemplo, a classificação da imagem passa de uma confiança de 55% de que é uma abelha para uma confiança de 97% de que é uma mosca. A Seção 4.2 estuda esses tipos de ataques de “copiar/colar” mais a fundo.
Nossas contribuições são triplas:
- Insight Conceitual: observamos que adversários resilientes ao nível das características podem ser usados para produzir tipos úteis de entradas para estudar as representações de redes profundas.
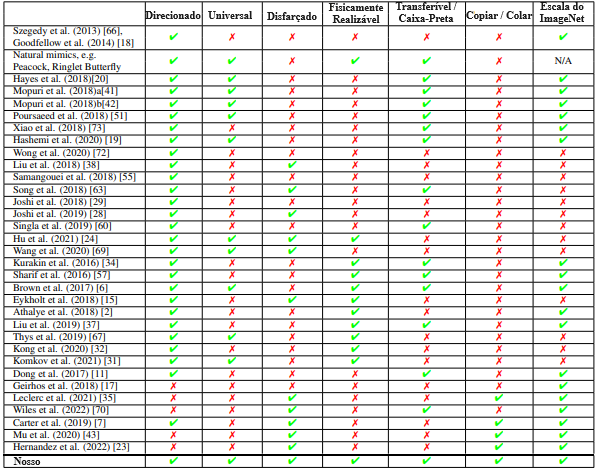
- Ataques Resilientes: introduzimos métodos para gerar adversários ao nível das características que são excepcionalmente versáteis e capazes de produzir ataques direcionados, universais, disfarçados, fisicamente realizáveis e de caixa-preta à escala do ImageNet. Veja a Tabela 1.
- Interpretabilidade: generalizamos a partir de nossos exemplos adversários para projetar ataques de “copiar/colar”, verificando que nossos adversários nos ajudam a entender bem a rede o suficiente para explorá-la.
As seções seguintes contêm o contexto, os métodos, os experimentos e a discussão. O Apêndice A. 11 tem um resumo de alto nível. O código está disponível em https://github.com/thestephencasper/feature_level_adv.
2. Trabalhos relacionados
Aqui, contextualizamos nossa abordagem com outras relacionadas à melhoria dos exemplos adversários convencionais [66, 18]. A Tabela 1 resume as capacidades.
Inspiração da Natureza: a mímica é comum na natureza e, às vezes, em vez de imitar holisticamente outra espécie, um mímico exibirá apenas características particulares. Por exemplo, muitos animais usam manchas oculares adversárias para confundir predadores [64] (veja o Apêndice A.1 Fig. 7a). Outro exemplo é o polvo mímico que imita o padrão, mas não a forma, de uma cobra marítima listrada. Mostramos na Figura 7b que um ResNet50 classifica uma imagem de um polvo mímico como uma cobra marítima.
Modelagem Generativa: uma abordagem relacionada à nossa é treinar um gerador ou autocodificador para produzir pequenas perturbações adversárias que são aplicadas a entradas naturais. Isso foi feito para sintetizar ataques imperceptíveis que são transferíveis, universais ou eficientes de produzir [20, 41, 42, 51, 73, 19, 72]. Em vez de treinar um gerador, o nosso e outros trabalhos perturbam os latentes de modelos generativos pré-treinados para produzir alterações perceptíveis. [38] fez isso com um renderizador de imagem diferenciável. Outros [55, 63, 29, 28, 60, 24] usaram redes generativas profundas, e [69] visou criar ataques mais semanticamente compreensíveis usando um autocodificador com um espaço de incorporação “desembaraçado”. Nosso trabalho é diferente em quatro aspectos. (1) Esses trabalhos se concentram em classificadores pequenos treinados em conjuntos de dados simples (MNIST [36], Fashion MNIST [74], SVHN [44], CelebA [39], BDD [75], INRIA [9] e MPII [1]), enquanto trabalhamos à escala do ImageNet [53]. (2) Não é que simplesmente confiamos em usar características pequenas ou restringir a distância para uma imagem benigna para impor a adversaridade dos ataques. Introduzimos técnicas que regularizam a característica adversária para ser perceptível, mas disfarçada para se assemelhar a algo diferente da classe-alvo. (3) Avaliamos três maneiras distintas de inserir características adversárias em imagens. (4) Nosso trabalho é orientado à interpretabilidade.
Ataques no Mundo Físico: a realizabilidade física demonstra resiliência. Mostramos que nossos ataques funcionam quando impressos e fotografados. Isso se relaciona diretamente com [34], que descobriu que adversários no espaço de pixels poderiam fazer isso em certa medida em ambientes controlados. Mais recentemente, [57, 6, 15, 2, 37, 67, 32, 31] criaram roupas, adesivos ou objetos adversários. Em contraste com eles, também produzimos ataques no mundo físico que estão disfarçados como uma classe-não alvo.
Adversários e Interpretabilidade: usar exemplos adversários para interpretar melhor as redes foi proposto por [11] e [68]. Usamos os nossos para descobrir associações entre características/classes descritíveis por humanos aprendidas por uma rede. Isso se relaciona com [17, 35, 70], que depuram redes pesquisando transformações, mudanças texturais e alterações de características. Mais semelhantes ao nosso trabalho são [7, 43, 23], que usam visualização de características [47] e dissecação de rede [3] para interpretar a rede. Cada um usa suas interpretações para projetar ataques de “copiar/colar” nos quais uma imagem natural colada dentro de outra causa uma classificação errada não relacionada. Acrescentamos a esse trabalho um novo método para identificar tais características adversárias. Ao contrário de qualquer abordagem anterior, o nosso faz isso de uma maneira que permite ataques direcionados que levam em conta uma distribuição arbitrária de imagens de origem.
3. Métodos
Adotamos o paradigma de adversários “não restritos” [63] sob o qual um ataque é bem-sucedido se a classificação da rede diferir da de um oráculo (p. ex., um humano). Nossos adversários só podem mudar uma pequena porção fixa dos latentes do gerador ou da imagem. Usamos acesso de caixa-branca à rede, embora apresentemos ataques de caixa-preta com base na transferência de um conjunto no Apêndice A.6.
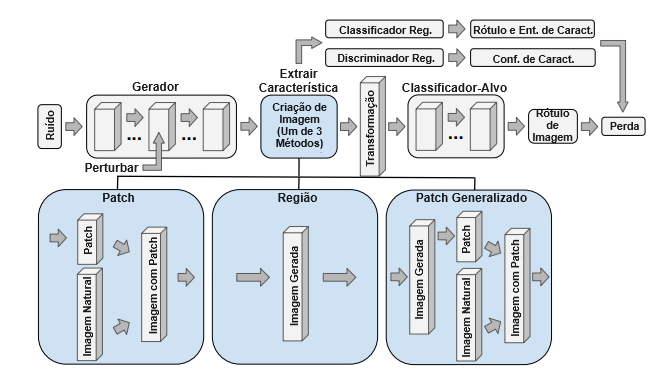
Nossos ataques envolvem a perturbação da representação latente em alguma camada de um gerador de imagens para produzir uma alteração adversária ao nível das características. A Figura 2 retrata nossa abordagem. Testamos três tipos de ataques, “patch”, “região” e “patch generalizado” (mais um quarto no Apêndice A.5, que chamamos de ataques de “canal”). Descobrimos que os ataques de patch geralmente são os mais bem-sucedidos.

Patch: usamos o gerador para produzir um patch quadrado que é inserido em uma imagem natural [58].
Região: começando com alguma imagem gerada, selecionamos aleatoriamente uma coluna quadrada do latente em uma camada do gerador que abrange a dimensão do canal e a substituímos por uma inserção aprendida. Isso é análogo a um patch quadrado na representação de pixels. Mantemos a localização da inserção fixa durante o treinamento. O latente modificado é passado pelo restante do gerador, produzindo a imagem adversária.
Patch Generalizado: estes patches podem ter qualquer forma; daí o nome “patch generalizado”. Primeiro, geramos um ataque de região e depois extraímos um patch generalizado dele. Fazemos isso tomando a diferença absoluta ao nível dos pixels entre a imagem original e a adversária, aplicando um filtro gaussiano para suavização e criando uma máscara binária a partir do maior decil dessas diferenças de pixels. Aplicamos essa máscara à imagem gerada para isolar a região que a perturbação alterou. Podemos então tratar isso como um patch e sobrepor na imagem em qualquer local.
Ataques Básicos: para todos os ataques, treinamos uma perturbação δ para o latente do gerador para minimizar uma perda que otimiza tanto para atacar o classificador quanto para parecer interpretável:
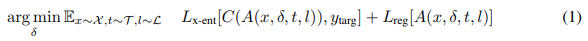
sendo X uma distribuição sobre imagens de origem (p. ex., um conjunto de dados ou distribuição de geração), T uma distribuição sobre transformações, L uma distribuição sobre locais de inserção (isso se aplica apenas a patches e patches generalizados), C o classificador-alvo, A uma função de geração de imagens, Lx-ent uma perda de entropia cruzada direcionada para atacar o classificador, ytarg a classe-alvo e Lreg uma perda de regularização. O adversário não tem controle sobre X, T ou L; então ele deve aprender características que funcionem na rede independentemente de qualquer imagem de origem, transformação ou local de inserção específico. Para todos os nossos ataques, Lreg contém uma perda de variação total, TV(a), para desencorajar padrões de alta frequência.
Ataques “Disfarçados”: idealmente, um exemplo adversário ao nível das características deve parecer facilmente descritível para um humano, mas não deve se assemelhar à classe-alvo do ataque. Chamamos esses ataques de “disfarçados”. Aqui, o principal objetivo não é enganar um humano, mas ajudá-lo a aprender sobre que tipos de características realistas podem fazer o modelo cometer um erro. Para treinar esses ataques disfarçados, usamos termos adicionais em Lreg como indicadores para esses dois critérios. Redimensionamos diferenciavelmente o patch ou o patch generalizado extraído e o passamos por um discriminador GAN e um classificador auxiliar. Em seguida, adicionamos termos ponderados à perda de regularização com base na perda logística do discriminador (D) para classificar a entrada como falsa, a entropia de saída (H) de algum classificador (C′) e/ou a negativa da perda de entropia cruzada do classificador para rotular a entrada como a classe-alvo do ataque. Observe que C′ pode ser o mesmo que o classificador-alvo C ou diferente dele. Com todos esses termos, o objetivo de regularização é:
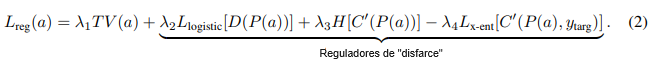
Aqui, P(a) retorna o patch extraído e redimensionado da imagem adversária a. Em ordem, esses três novos termos incentivam a característica adversária a (1) parecer realista e (2) se parecer com alguma classe específica, mas (3) não a classe-alvo. A escolha da classe de disfarce é deixada inteiramente para o processo de treinamento.
4. Experimentos
Utilizamos os geradores BigGAN de [5, 71] e perturbamos as saídas pós-ReLU dos “GenBlocks” internos. Também descobrimos que treinar pequenas perturbações nas entradas do BigGAN melhorou o desempenho. Utilizamos o discriminador do BigGAN e classificadores treinados adversariamente de [13] para a regularização do disfarce. Por padrão, atacamos uma ResNet50 [21], restringindo os ataques de patch a 1/16 da imagem e os ataques de região e patch generalizado a 1/8. O Apêndice A.2 contém detalhes adicionais. Primeiro, na Seção 4.1, mostramos que esses adversários ao nível das características são altamente resilientes para sugerir que as interpretações baseadas neles são generalizáveis. Segundo, na Seção 4.2, colocamos essas interpretações à prova e mostramos que nossos adversários ao nível das características podem ajudar a entender bem uma rede o suficiente para explorá-la.
4.1. Ataques resilientes
A Figura 3 mostra exemplos de ataques de patch (topo), região (meio) e patch generalizado (fundo) ao nível das características direcionados, universais e disfarçados, cada um treinado com todos os termos de regularização de disfarce da Eq. 2. Achamos os disfarces eficazes, especialmente para os patches (linha superior), mas imperfeitos. O Apêndice A.3 discute isso e o que pode sugerir sobre redes e viés de tamanho.
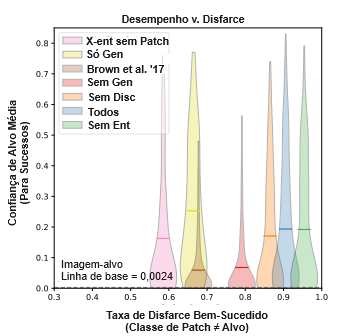
Desempenho versus Disfarce: Aqui, estudamos nossos ataques de patch em profundidade para testar sua eficácia em atacar a rede e como eles podem ajudar a identificar com sucesso características que não são da classe-alvo e que podem enganar a rede. Comparamos sete abordagens diferentes. A primeira foi nossa abordagem completa usando o gerador e todos os termos de regularização de disfarce da Eq. 2. As demais foram testes de ablação em que omitimos o gerador (Sem Gen), o discriminador (Sem Disc), o termo de regularização (Sem Reg), o termo de regularização de entropia (Sem Ent), o termo de regularização de entropia cruzada (Sem X-ent de Patch), todos os três termos de regularização (Apenas Gen) e, finalmente, o discriminador e todos os três termos de regularização (Brown et al. ’17). Esse método final não regularizado, ao nível dos pixels, resultou na mesma abordagem de Brown et al. (2017) [6]. Para cada teste, tudo o mais foi mantido idêntico, incluindo penalização de variação total, treinamento sob transformações e inicialização do patch como saída do gerador.

Para cada método, geramos ataques universais com classes-alvo aleatórias até obtermos 250 casos “disfarçados” com sucesso, nos quais a característica adversária resultante não foi classificada pela rede como a classe-alvo quando visualizada isoladamente. A Figura 4 mostra a taxa de sucesso versus a distribuição de confianças médias da classe-alvo para cada tipo de ataque. Para todos os métodos, esses ataques universais têm confianças variáveis na classe-alvo, devido em grande parte à seleção aleatória da classe-alvo. Alguns ataques são estocasticamente dominados de Pareto por outros. Por exemplo, os ataques do espaço de pixels de Brown et al. (2017) foram os menos eficazes em atacar a rede-alvo e tiveram a terceira menor taxa de disfarce. Em outros casos, há uma troca entre o desempenho do ataque e o disfarce, que pode ser controlado usando os termos de regularização da Eq. 2. Também comparamos nossos ataques com duas linhas de base usando imagens naturais redimensionadas da classe-alvo e patches tirados como amostras aleatórias do centro das imagens da classe-alvo. Isso resultou em confianças médias na classe-alvo de 0,0024 e 0,0018, respectivamente.
É importante observar que a Figura 4 não captura tudo o que se pode considerar importante nesses ataques. Não mostra nenhuma medida de quão “realistas” os patches resultantes parecem ser. No Apêndice A.4, a Figura 9 mostra os mesmos dados de confiança da classe-alvo do eixo y na Figura 4 versus o rótulo de confiança da classe de disfarce de um Inception-v3, que usamos como um indicador de quão realista um humano consideraria o patch. Isso sugere que os melhores ataques para produzir patches que parecem realistas são os métodos “Todos” e “Sem Disc”. No Apêndice A.10, as Figuras 13, 14 e 15 dão exemplos de ataques bem-sucedidos “Todos”, “Apenas Gen” e “Brown et al. ’17”, respectivamente. Por terem sido inicializados a partir das saídas do gerador, alguns dos ataques “Brown et al. ’17” têm uma semelhança como verniz com características que não são da classe-alvo. No entanto, eles contêm padrões de frequência mais alta e objetos menos coerentes em comparação com os dois conjuntos de ataques ao nível das características. Subjetivamente, encontramos os ataques “Todos” como os mais bem disfarçados.
Realizabilidade Física: para testar sua capacidade de transferência para o mundo físico, geramos 100 patches adversários direcionados, universais e disfarçados adicionais. Usamos o gerador e todos os termos de regularização (a condição “Todos” mencionada acima). Selecionamos os 10 com a melhor média de confiança na classe-alvo, imprimimos e fotografamos cada um ao lado de 9 objetos de diferentes classes do ImageNet.2 Confirmamos que as fotografias de cada objeto foram classificadas corretamente sem um patch. A Figura 5 mostra exemplos bem-sucedidos. Enquanto isso, versões redimensionáveis e imprimíveis de todos esses patches e outros estão no Apêndice A.10. A média e o desvio-padrão das confianças na classe-alvo para nossos ataques no mundo físico foram 0,312 e 0,318, respectivamente (n = 90, não i.i.d.). Isso significa que a média de eficácia desses patches caiu por menos de 1/2 ao transferir para o mundo físico.
Ataques de Caixa-Preta: no Apêndice A.6, mostramos que nossos ataques universais direcionados podem ser transferidos de um conjunto para um modelo mantido fora.
4.2. Interpretabilidade
Se uma característica adversária engana com sucesso a rede-vítima, isso sugere que a rede associa aquela característica, no contexto de uma imagem de origem, com a classe-alvo. Descobrimos que nossos adversários podem sugerir associações entre características e classes tanto benéficas quanto prejudiciais. No Apêndice A.7, a Figura 11 fornece um exemplo simples de cada. Desenvolver uma interpretação é fácil. Mostrar que ela leva a uma compreensão útil da rede é mais difícil. Um desafio na literatura de IA explicável é desenvolver interpretações que vão além de parecerem plausíveis e resistirem à análise crítica [52]. Patches adversários resilientes ao nível das características podem facilmente ser usados para desenvolver hipóteses sobre o comportamento da rede: p. ex., “A rede pensa que características de abelhas mais bolas coloridas implicam uma mosca.” Mas essas são interpretações válidas e úteis da rede? Em outras palavras, nossos adversários são adversários por causa de suas qualidades interpretáveis, ou é por causa de padrões ocultos? Verificamos as interpretações usando nossos ataques para fazer e validar previsões sobre como enganar a rede-alvo com objetos naturais.
Validando Interpretações com Ataques de “Copiar/Colar”: um ataque de “copiar/colar” é criado inserindo uma imagem natural em outra para causar uma classificação incorreta inesperada. Eles são mais restritos do que os ataques de patch porque as características coladas em uma imagem devem ser objetos naturais. Como resultado, eles são de grande interesse para ataques fisicamente realizáveis, porque sugerem combinações de objetos reais que resultam em classificações inesperadas. Eles também têm precedentes no mundo real. Por exemplo, inserções de subimagem em imagens pornográficas foram usadas para evitar detectores de conteúdo adulto. Para desenvolver ataques de “copiar/colar”, selecionamos uma classe de origem e uma classe-alvo, geramos características adversárias universalmente para a classe e as analisamos manualmente em busca de padrões que se assemelham a objetos naturais. Aqui, usamos ataques básicos sem os termos de regularização de disfarce da Eq. 2. Em seguida, colamos imagens desses objetos em imagens naturais e as passamos pelo classificador [76].
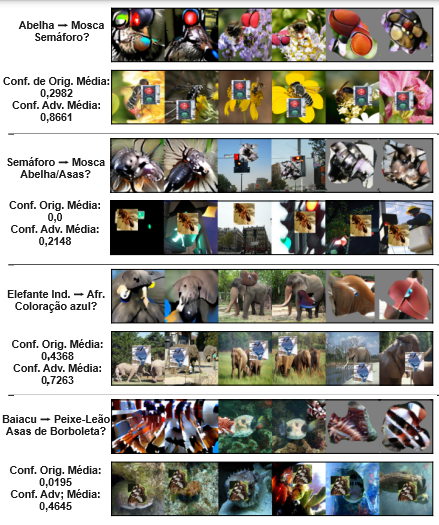
A Figura 6 mostra quatro tipos de ataques de “copiar/colar”. Em cada linha ímpar, mostramos seis adversários de patch, região e patch generalizado que foram usados para orientar o design de um ataque de “copiar/colar”. Em cada linha par, estão os adversários de “copiar/colar” para as 6 (de 50) imagens da classe de origem para as quais a inserção resultou no maior aumento na confiança da classe-alvo, junto com as confianças médias da classe-alvo antes e depois da inserção do patch para essas 6. O sucesso desses ataques mostra sua utilidade para interpretar a rede alvo, pois exigem que um humano entenda o erro que o modelo está cometendo, como “Abelha ∧ Semáforo → Mosca”, o suficiente para explorá-lo manualmente. Dadas as diferenças nas características adversárias produzidas nos ataques de Abelha → Mosca e Semáforo → Mosca, a Figura 6 também demonstra como nossos ataques levam em conta a distribuição de imagens de origem.
Comparação com Outros Métodos: três trabalhos anteriores desenvolveram ataques de “copiar/colar”, também por meio de ferramentas de interpretabilidade. Ao contrário de [43, 23], nossa abordagem permite ataques direcionados. E ao contrário de todos os três, em vez de simplesmente identificar características associadas a uma classe, nossos adversários geram características adversárias para uma classe-alvo condicionada a qualquer distribuição sobre imagens de origem (ou seja, a classe de origem) com a qual os adversários são treinados. Pouco trabalho foi feito em adversários de “copiar/colar”, e até agora, os métodos não permitiram ataques direcionados ou exigiram um humano no processo. Isso torna comparações objetivas difíceis. No entanto, fornecemos exemplos de um método baseado na visualização de características inspirada em [7] no Apêndice A.8 para comparar com o nosso. Para o ataque de Elefante Indiano → Africano, a classe de origem e a classe-alvo compartilham muitas características, e não encontramos evidências de que a visualização de características seja capaz de sugerir características úteis para ataques de “copiar/colar”. Isso sugere que a capacidade de nossos ataques de levar em conta a distribuição de imagens de origem possa ser mais útil para descobrir certas fraquezas em comparação com a linha de base inspirada em [7].
5. Discussão e impacto mais amplo
Contribuições: aqui utilizamos exemplos adversários ao nível das características para atacar e interpretar redes profundas, a fim de contribuir para uma compreensão mais prática das vulnerabilidades da rede. Como método de ataque, nossa abordagem é versátil. Ela pode produzir ataques direcionados, universais, disfarçados, realizáveis fisicamente, de caixa-preta e de copiar/colar à escala do ImageNet. Este método também pode ser usado como uma ferramenta de interpretabilidade para ajudar a diagnosticar falhas em modelos. Fundamentamos a noção de interpretabilidade na capacidade de fazer previsões sobre combinações de características naturais que farão um modelo falhar. E, finalmente, demonstramos isso por meio do design de ataques de copiar/colar direcionados a qualquer distribuição sobre as entradas de origem.
Implicações: como qualquer trabalho sobre ataques adversários, nossa abordagem poderia ser usada maliciosamente para fazer um sistema falhar, mas enfatizamos seu valor diagnóstico. Compreender as ameaças é um requisito prévio para evitá-las. Dada a resiliência e versatilidade de nossos ataques, argumentamos que eles podem ser valiosos para o trabalho contínuo para enfrentar ameaças que os sistemas possam enfrentar em aplicações práticas. Há pelo menos duas maneiras como esses métodos podem ser úteis.
Treinamento Adversário: o primeiro é para o treinamento adversário. O treinamento de redes em imagens adversárias mostrou-se útil para melhorar sua resiliência aos ataques usados [13]. Mas isso não garante resiliência a outros tipos de entradas adversárias (p. ex., [22]). Nossos ataques ao nível das características são categoricamente diferentes dos convencionais ao nível dos pixels, e nossos ataques de copiar/colar mostram como as redes podem ser enganadas por combinações novas de objetos naturais, falhas que estão fora do paradigma convencional de resiliência adversária (p. ex., [13]). Consequentemente, esperamos que o treinamento adversário em classes mais amplas de ataques, como o que propomos aqui, seja valioso para projetar modelos mais resilientes. Como um sinal promissor, mostramos no Apêndice A.9 que o treinamento adversário é útil contra nossos ataques.
Diagnóstico: o segundo é para diagnosticar rigorosamente falhas. Mostramos que adversários ao nível das características auxiliam na descoberta de associações de características /classes espúrias exploráveis e de um viés prejudicial à sociedade. Nossa abordagem também pode ser estendida para além do que demonstramos aqui. Por exemplo, nossos métodos podem ser úteis para a visualização de características [47] de uma rede neuronal interna. Uma abordagem análoga à nossa também pode ser usada no Processamento de Linguagem Natural [62, 50], e atualmente estamos trabalhando em um método para isso. Além disso, pode ser valioso usar esses adversários para identificar falhas generalizáveis em redes que os humanos possam entender facilmente, mas com o mínimo de envolvimento humano. Isso seria muito mais amplificável e impediria que as probabilidades a priori humanas influenciassem as interpretações. Consulte [8] o trabalho seguinte que envolve a descoberta totalmente automatizada de ataques de copiar/colar.
Limitações: uma limitação de nossa abordagem é que, quando vários desideratos são otimizados ao mesmo tempo (p. ex., universalidade + resiliência à transformação + disfarce), os ataques geralmente são menos bem-sucedidos, consomem mais tempo e exigem mais triagem para encontrar os bons. Isso pode ser um gargalo para o treinamento adversário em grande escala. Em última análise, esse tipo de ataque é limitado pela eficiência e qualidade do gerador; portanto, trabalhos futuros devem aproveitar os avanços na modelagem generativa. Nosso método de avaliação também é limitado a uma prova de conceito para o design de ataques de copiar/colar. Trabalhos futuros devem avaliar isso de forma mais rigorosa. Atualmente, estamos trabalhando para desenvolver um referencial para ferramentas de interpretabilidade com base em sua capacidade de ajudar um humano a redescobrir cavalos de Troia [16] que tenham sido implantados em um modelo.
Conclusão: à medida que a IA se torna cada vez mais capaz, torna-se mais importante projetar modelos que sejam confiáveis. Cada uma das 11 propostas para construir IA segura delineadas em [26] pedem explícitamente a resiliência adversária e/ou ferramentas de interpretabilidade, e um trabalho recente sobre confiabilidade de alto risco em IA descobriu que ferramentas de interpretabilidade fortaleceram sua capacidade de produzir entradas para o treinamento adversário. Dada a relação próxima entre interpretabilidade e resiliência adversária, o estudo contínuo das conexões entre elas será fundamental para a construção de sistemas de IA mais seguros.
Agradecimentos
Agradecemos a Cassidy Laidlaw, Miles Turpin, Will Xiao e Alexander Davies por discussões perspicazes e pelo feedback, e a Kaivu Hariharan pela ajuda com a codificação. Este trabalho foi realizado em parte com o financiamento do Escritório de Pesquisa e Bolsas de Estudos de Graduação de Harvard.
Notas:
1. https://github.com/thestephencasper/feature_level_adv
2. Mochila, banana, toalha de banho, limão, espátula, óculos de sol, papel higiênico e torradeira.
Referências
Consulte as referências do artigo original.
Tradução: Luan Marques
Link para o original